2026收藏夹总结(持续更新)

2026收藏夹总结(持续更新)
[!Tip] 收藏说明 本文档整理收录 2026 年度优质文章、技术教程与实用资源,持续更新中...
📌 内容概览
本文档按日期分类收录优质内容,主要涵盖以下领域:
🔧 技术教程
- 02/01 思源笔记 S3 插件配置、Clawdbot 钉钉接入、Nitro.js 服务端工具、Vue Router 5、Electron 自动更新、MCP AI 自动化
- 02/03 AI Coding 网页设计、SVN 迁移 Git
- 02/04 系统接口慢速排查实战
- 02/06 开源 UI-UX 设计技能包
- 02/07 Antdv Next (Vue3 组件库)、Vue 高效插件、Autorecon 懒人神器
- 02/08 AI 编程入门、视频下载技巧
- 02/09 Axios 封装与拦截器
- 02/10 OpenClaw 与 Skills/MCP/RAG/Agent 关联解析
- 02/14 VueUse 工具库、手写签名、富文本编辑器、HTTP 方法速查表
- 02/15 腾讯地图集成、emoji 选择器
- 02/16 vue-ai-migrator 项目迁移工具
- 02/17 VueRouter 4 入门
- 02/18 免费 WebSocket 服务器、GitHub 神级 Skills
- 02/20 RuoYi 全栈 AI 平台、xxl-job 定时调度原理
- 02/24 Bitwarden 自托管密码管理器、SQL 面试题、缓存模式、3 个 AI Agent 开源项目
- 02/25 GitHub 55k Star 单文件后端
- 02/26 OpenCode 中文教程、Vize 工具、AI 编程工作流
- 02/28 qrcode-vue3 二维码生成
- 03/03 ChartGPU (WebGPU ECharts)、OpenClaw 完整教程
- 03/27 Vue Native 发布、Token 计费机制详解
☕ Java & 全栈
- 02/02 SpringBoot 文件分片上传、Java 工程师必知、Claude Code 提示词技巧
- 02/11 Conventional Commits 规范、Java 转 Go 建议
- 02/24 面试题:缓存一致性解决方案
💡 AI 与工具
- 03/03 ChartGPU (WebGPU ECharts)、OpenClaw 完整教程
- 03/05 Nano Banana 2 创作工具
- 03/25 MiniMax Office Skills、CLI-Anything Agent 工具
🧠 思维与成长
- 03/06 斯多葛哲学实用指南
- 03/12 幸存者偏差与全样本思维
- 03/14 意志力霸凌、大脑戒备与微习惯
🏢 运维与安全
- 03/20 存储知识全解
- 02/24 Bitwarden + Cloudflare 自托管密码管理
📅 2月
02/01 | 技术教程
- 🚀 思源笔记 S3 插件 v1.0.2 更新:手把手教你配置 PicList 导出[^1]
- 🪁 Clawdbot 接入钉钉手把手教程[^2]
- 🦢 Nitro.js 前端技术栈 服务端运行时工具包[^3]
- 🐼 Vue Router 5:【手写路由】时代终结![^4]
- 🐕 electron应用自动更新详细教程(二):更新服务器搭建[^5]
- 🚆 【Electron】打包后图标不变问题[^6]
- 🔦 微软授权 Windows MCP AI:Flow IPC 本地大模型实现全流程自动化[^7]
02/02 | Java & Spring
- 🕋 SpringBoot + 文件分片上传 + 断点续传 + 秒传(MD5 校验)[^8]
- 🏆 java研发工程师必知必会[^9]
- 🍫 基于 Claude Code 自动编程案例的提示词技巧[^10]
02/03 | UI/设计 & Git
- 🐻❄️ 不会设计也能搭出高级感网页:AI Coding 提示词模板 & 精品组件库[^11]
- 👞 将 SVN 仓库迁移到 Git[^12]
- ☕ 6 个超神的 SKills,GitHub 热门推荐[^13]
02/04 | 系统排查
- 🐫 系统接口突发慢速的系统化排查思路与实战指南[^14]
02/06 | AI设计
- 📈 开源-UI-UX 设计技能包,跨平台多框架一键生成专业级界面[^15]
02/07 | 工具推荐
- 🍇 重磅!Antdv Next 正式发布!对标 Antd V6 的 Vue3 UI 组件库[^16]
- 📄 Vue 开发必备!9 个高效插件,Vue2-Vue3 通用[^17]
- 🧿 懒人神器 Autorecon[^18]
- 🏐 编程中的MVP是什么意思?[^19]
02/08 | AI编程
- 🎉 AI编程,我也入局了![^20]
- 📸 一句话让 AI 帮我下载各种视频[^21]
02/09 | Axios封装
- 🏡 Axios 高效封装实战:拦截器 + 统一处理,告别重复请求逻辑[^22]
02/10 | OpenClaw
- 🍗 OpenClaw(clawdbot)是什么?与 Skills、MCP、RAG、Memory 与 AI Agent 的关联解析[^23]
02/11 | 开发规范
- 📄 Conventional Commits 规范详解[^24]
- 📄 建议Java工程师都要学习一下Go语言[^25]
02/14 | Vue3 & 工具
- 🩱 干掉 Vite ?Vize ?[^26]
- 📄 MiniCPM-o 4.5 开源,登上了开源热榜[^27]
- 📄 Vue3 开发效率翻倍!VueUse 工具库从入门到实战[^28]
- 🪵 Vue3实现手写签名:Vue3-signature的快速应用[^29]
- 📄 开源 Web 现代富文本编辑器[^30]
- 📄 告别死记硬背!HTTP请求方法速查表[^31]
02/15 | Vue插件
- 📄 vue-qqmap:Vue 项目中快速集成腾讯地图的实用插件[^32]
- 📄 vue3-emoji-picker 优雅实现表情包选择器[^33]
02/16 | AI迁移
- 📄 vue-ai-migrator:AI赋能,Vue项目迁移新效率[^34]
02/17 | VueRouter
- 🎆 VueRouter 4 快速入门[^35]
02/18 | Websocket & Skills
- 🎇 免费 Websocket 服务器[^36]
- 📄 推荐 4 个神级 SKills 开源 GitHub 项目[^37]
02/20 | RuoYi & 定时任务
- 🎛️ RuoYi 全栈 AI 平台开源![^38]
- 📄 大白话说清楚xxl-job底层定时调度的原理[^39]
02/24 | 安全 & 面试
- 🩱 干掉 Vite ?Vize ?[^26]
- 📄 Bitwarden 跑在 Cloudflare 上!自托管密码管理器[^40]
- 🥑 一篇 Markdown,自动生成封面、信息图、小红书风格[^41]
- 📄 SQL面试题:怎么查连续登录N天的用户?[^42]
- 📄 面试官:项目中你是采用哪种缓存模式来解决数据一致性问题的?[^43]
- 📄 盘点 3 个 AI Agent 相关神级 GitHub 开源项目[^44]
02/25 | 全栈开发
- 🪮 GitHub 55k Star!仅需一个文件,10分钟上线全功能后端[^45]
02/26 | AI编程
- 🫓 OpenCode 中文教程 - AI 编程助手实战指南[^46]
- 🌦️ 前端最丑的 UI 组件,Chrome 痛下杀手![^47]
- 🫑 稳如老狗、节省成本的 AI 编程工作流实战指南[^48]
02/28 | Vue二维码
- 🎫 快速实现 Vue3 二维码生成:qrcode-vue3 使用指南[^49]
📅 3月
03/02 | 热点解析
- 🥛 深度解析:时薪48美元的赛博苦力,马斯克为何让AI洗碗?[^50]
- 🐇 老板让我做搜索功能:"一句 SQL 不就搞定了?" 结果...[^51]
03/03 | AI & Chart
- ♥️ ChartGPU 重磅发布!WebGPU 版的 ECharts[^52]
- 📄 OpenClaw从新手到中级完整教程[^53]
03/05 | AI创作
- 🦨 Nano Banana 2 的 16 个邪修玩法[^54]
03/06 | 人生哲学
- 👡 在动荡时代构建内在结界:斯多葛哲学的实用指南[^55]
03/12 | 思维认知
- 🛷 别被成功学误导:从幸存者偏差到全样本思维[^56]
03/14 | 成长心态
- 🏍️ 求你了,别再对自己搞"意志力霸凌"了[^57]
- 🎊 为什么越努力,越快失败?——大脑戒备、活化能与微习惯的科学解答[^58]
03/20 | 运维存储
- 🌑 运维工程师必存!存储知识,万字全解![^59]
03/25 | AI办公 & Agent
- 🦡 MiniMax Office Skills:开源一套生产级办公文档引擎[^60]
- 🥭 一条命令让 AI Agent 接管任何软件,港大开源 CLI-Anything[^61]
03/27 | 技术教程
- 📄 Vue Native 发布!官网已上线![^62]
- 📄 一文彻底搞懂 Token:词元是什么?输入输出与缓存命中又如何计费?[^63]
📅 4月
04/02 | AI工具 & 模型
- 🎯 又一款国产模型诞生,性价比杀疯了![^64]
- 🐴 Claude Code创始人最爱!一行命令打造24小时专属牛马,香爆了![^65]
04/05 | 技术问题
- 🐛 Node.js EACCES error when listening on most ports[^66]
04/07 | AI安全 & 开发工具
- 🔓 Claude 4小时血洗全球最安全系统,人类最后防线失守 - 36氪[^67]
- 🛠️ IDEA 的 Git 客户端,被社区单独做成了一个工具[^68]
- 🎨 前端 20 年!正式-干掉- 骨架屏![^69]
04/15 | Windows开发
- 💾 Memurai - Windows 上的 Redis 替代方案(内存缓存服务)[^70]
04/19 | 环境配置
- ⚙️ 解决 PowerShell 中 choco 命令缺失[^71]
04/20 | 前端工具
- 🖥️ 前端开发新纪元!22.7K Star 可视化编辑器,在浏览器里改 React 代码[^72]
- ⚡ 前端效率 ×10!在浏览器中改 UI,代码自动写回[^73]
04/23 | AI技术
- 📚 RAG 是什么?16 种 RAG 方案一次讲清!万字干货[^74]
[!Note] 更新日志
- 2026.02 创建文档,收录 2 月份优质资源
- 2026.03 持续更新中...
- 2026.04 新增 4 月份资源目录
[^1]: # 🚀 思源笔记 S3 插件 v1.0.2 更新:手把手教你配置 PicList 导出
# 思源笔记 S3 插件 v1.0.2 更新:配置 PicList 导出
本次更新最大的亮点是**加入了对 PicList 的支持**,让图床上传更加稳健。
---
## 1️⃣ 插件更新
进入思源笔记**集市**,搜索 **“S3”** ,找到“上传到 S3 并导出 Markdown”插件,更新至 **v1.0.2**。
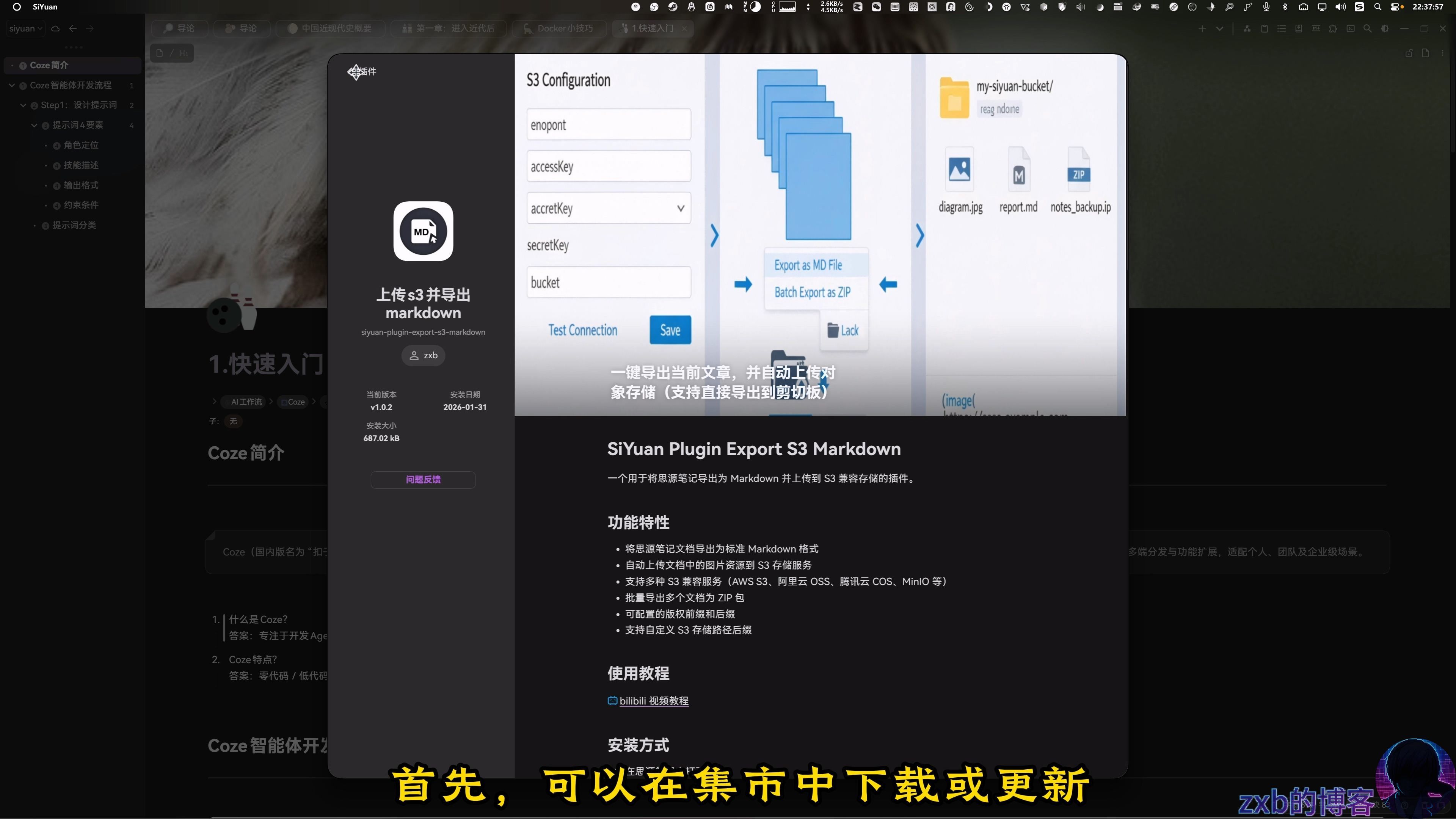
---
## 2️⃣ 开启配置界面
进入插件设置,左侧新增了 **“PicList 设置”** 和 **“上传方式选择”** 。
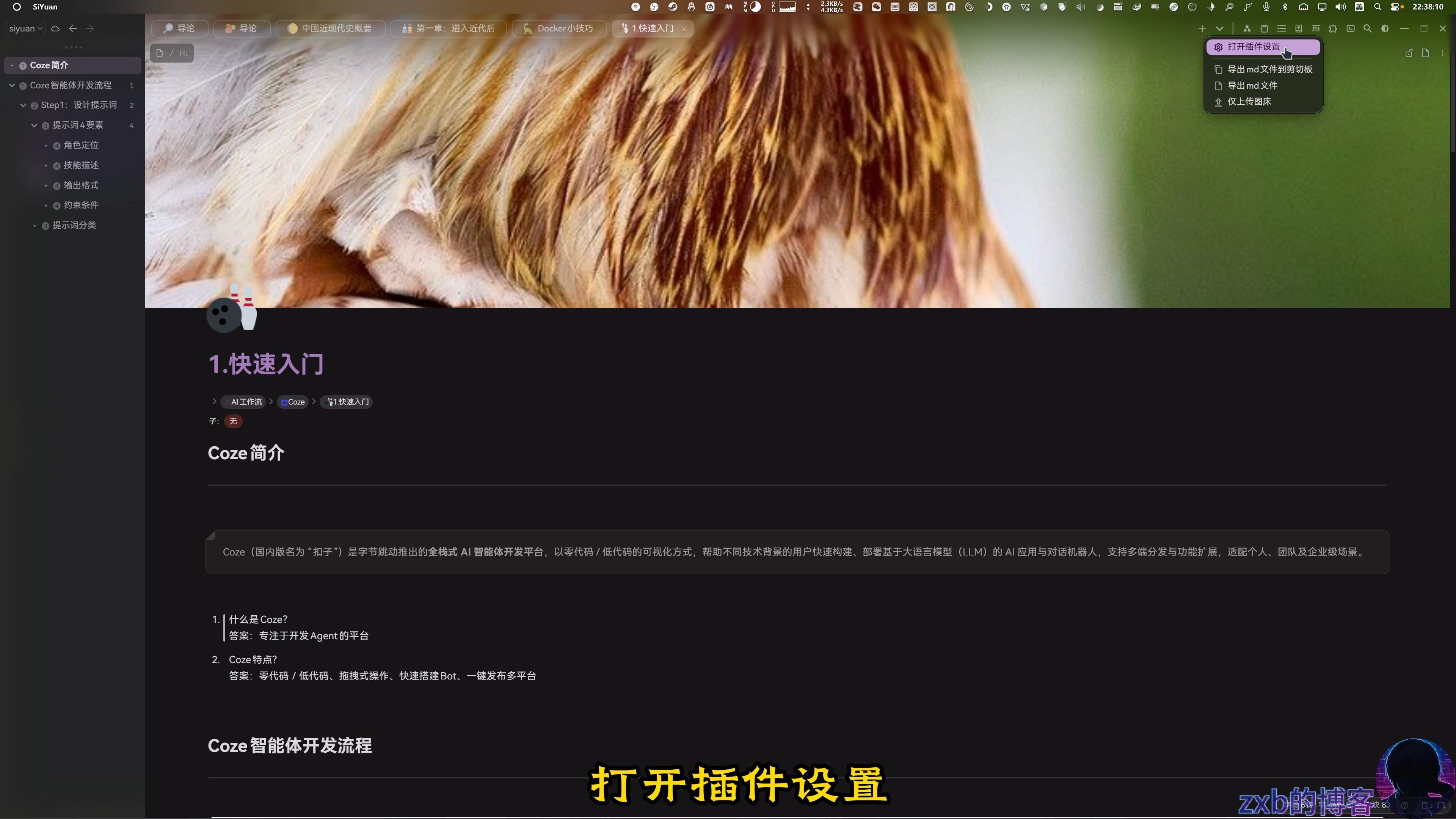
---
## 3️⃣ 关键参数匹配(重点)
在 PicList 设置页面,检查 **API 地址和端口**。
- **地址**:必须与 PicList 客户端设置一致(通常为 `127.0.0.1:36677`)。

> **提示**:如果测试连接报错,请检查 PicList 是否在系统托盘后台正常运行。
>
---
## 4️⃣ 切换上传模式
在“上传方式选择”中,将默认方式更改为 **“PicList”** 。

---
## 5️⃣ 实战测试
回到笔记页面执行导出,图片将通过 PicList 自动处理。
**小贴士:** 使用 PicList 可更方便地管理不同云端的图片存储。若遇问题,请检查防火墙是否拦截端口通讯。[^2]: # Clawdbot 接入钉钉手把手教程,只要一台电脑就能完成
# Clawdbot 接入钉钉手把手教程
> [!WARNING] ⚠️ 安全风险提示
> Clawdbot 需要完全的文件访问权限,且允许外部连入本机,存在较大安全风险。建议使用单独的、无敏感数据的电脑进行部署。
>
## 准备工作
- 一台电脑
- [通义千问 (Qwen) 账号](https://chat.qwen.ai/)
- 钉钉账号(个人账号即可,随便加入一个企业)
- **不需要**:Mac Mini、云主机、公网 IP
---
## 01 | 安装 Clawdbot (现名 Moltbot)
### 1. 执行安装命令
**Mac / Linux:**
```bash
curl -fsSL https://molt.bot/install.sh | bash
```
**Windows:**
```powershell
iwr -useb https://molt.bot/install.ps1 | iex
```
### 2. 初始化配置
终端中按提示操作:
1. 接受风险 -> 选 `Yes`
2. 配置模式 -> 选 `Quick Start`
3. 选择模型 -> 选 `Qwen` (免费量大)
4. 浏览器弹出 -> 确认登录 Qwen
5. Channel 配置 -> 选 `Skip for Now` (跳过)
6. Skill 插件 -> 选 `No` (跳过)
7. Hooks 钩子 -> 选 `Skip for Now` (跳过)
8. 运行方式 -> 选 `Hatch in TUI` (推荐)
安装完成后,浏览器会自动打开控制台:[http://127.0.0.1:18789](http://127.0.0.1:18789)
---
## 02 | 配置钉钉
### 第一步:安装钉钉插件
```bash
clawdbot plugins install https://github.com/soimy/clawdbot-channel-dingtalk.git
cd ~/.clawdbot/extensions/dingtalk/
npm install zod
```
### 第二步:创建应用
1. 访问 [钉钉开发者后台](https://open-dev.dingtalk.com/)
2. 点击“应用开发” -> “创建应用”
3. 填写应用名称(即机器人名字)和描述
### 第三步:机器人配置
1. 点击左侧“机器人” -> “机器人配置”
2. **关键设置**:将消息接收模式改为 **Stream 模式**
3. 点击“发布”
### 第四步:获取凭证
在应用详情页点击“凭证与基础信息”,复制以下信息:
- Client ID (AppKey)
- Client Secret (AppSecret)
- Robot Code (通常同 Client ID)
- Corp ID (企业 ID)
- Agent ID (应用 ID)
---
## 03 | 对接 Clawdbot 和钉钉
### 修改配置文件
编辑文件 `~/.clawdbot/clawdbot.json`,在最后一个 `}` 之前加入以下内容:
```json
"channels": {
"dingtalk": {
"enabled": true,
"clientId": "改成你的",
"clientSecret": "改成你的",
"robotCode": "改成你的",
"corpId": "改成你的",
"agentId": "改成你的",
"dmPolicy": "open",
"groupPolicy": "open",
"debug": false
}
}
```
### 重启服务
```bash
clawdbot gateway restart
```
*注:后续配置也可在 Web UI 的“Channels”菜单中修改。*
---
## 04 | 开始使用
现在可以在钉钉(手机或电脑端)中直接与机器人聊天,或将其拉入群组 @它进行对话。
**参考文档:**
- [钉钉插件文档](https://github.com/soimy/clawdbot-channel-dingtalk?tab=readme-ov-file)
- [官方文档](https://docs.molt.bot/start/showcase)[^3]: # Nitro.js 前端技术栈 服务端运行时工具包
# Nitro.js 前端技术栈
**标签**:服务端运行时工具包
Nitro.js 是一个通用的 Web 服务器框架,适用于多种前端技术栈。
[^4]: # Vue Router 5:【手写路由】时代终结!
# Vue Router 5:【手写路由】时代终结!
## 现状:重复且繁琐的劳动
过去,每个 Vue 项目都要维护这样的 `routes` 数组:
```javascript
const routes = [
{ path: '/', component: Home },
{ path: '/users/:id', component: User }
]
```
项目越大,路由文件越长,维护成本越高。现在,**Vue Router 5 官方支持路由自动化**。
---
## 什么是“路由自动化”?
**核心原则**:不用再手写 routes,文件结构就是路由结构。
`unplugin-vue-router` 正式并入 `vuejs/router` 核心仓库。
### 目录示例
```
src/pages/
├── index.vue → /
├── users.vue → /users
└── users/[id].vue → /users/:id
```
插件会在**构建阶段自动扫描文件**,生成完整的路由表。这套模式已在 Nuxt 和 Next.js 中得到验证。
---
## 核心价值:不只是少写代码
### 1. 路由参数完全类型安全
```javascript
router.push({
name: 'users-id',
params: { id: 123 }
})
```
- 路由名拼错 -> **编译期直接报错**
- 参数类型不对 -> **TS 立即提示**
### 2. 默认懒加载
所有页面自动变成 `() => import('./pages/xxx.vue')`,无需手动配置代码分割。
### 3. 官方方案,稳定可靠
不再是第三方插件,而是 Vue Router 核心的一部分,API 稳定且长期维护,与 Vue/Vite/TS 深度协同。
---
## 如何快速升级?
> 你不需要等 Vue Router 5 正式发布,现在就可以用。
>
### 老项目:渐进式接入(推荐)
**1. 安装插件**
```bash
npm i -D unplugin-vue-router
```
**2. 配置 Vite**
```javascript
// vite.config.ts
import VueRouter from 'unplugin-vue-router/vite'
import vue from '@vitejs/plugin-vue'
export default {
plugins: [VueRouter(), vue()]
}
```
**3. 使用生成的 routes**
```javascript
import { createRouter, createWebHistory } from 'vue-router'
import { routes } from 'vue-router/auto-routes'
export const router = createRouter({
history: createWebHistory(),
routes
})
```
### 新项目:直接使用
- 使用 `src/pages` 规划路由
- 放弃手写 `routes`
**Vue Router 5 的设计思路:不强推、不破坏、允许共存。**
[^5]: # electron应用自动更新详细教程(二):更新服务器搭建
# Electron 应用自动更新:搭建 Nginx 更新服务器
## 1. 准备目录
在服务器上创建必要的目录结构:
```bash
mkdir -p /root/docker/nginxElectronUpdateServer/logs
mkdir -p /root/docker/nginxElectronUpdateServer/conf
mkdir -p /root/docker/nginxElectronUpdateServer/html/updates
```
## 2. 配置 Nginx
新建配置文件 `vi /root/docker/nginxElectronUpdateServer/conf/nginx.conf`:
```nginx
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name localhost;
root /usr/share/nginx/html;
location / {
try_files $uri $uri/ =404;
}
location /updates/ {
autoindex on; # 启用目录列表显示
autoindex_exact_size off; # 友好的文件大小显示
autoindex_localtime on; # 显示本地时间
}
}
}
```
## 3. 启动服务
使用 Docker 启动 Nginx 容器:
```bash
docker run -p 13500:80 \
--name nginxElectronUpdateServer \
-v /root/docker/nginxElectronUpdateServer/logs:/var/log/nginx \
-v /root/docker/nginxElectronUpdateServer/conf/nginx.conf:/etc/nginx/nginx.conf:ro \
-v /root/docker/nginxElectronUpdateServer/html:/usr/share/nginx/html \
-d nginx
```
## 4. 验证与使用
1. 访问 `http://你的服务器IP:13500/updates/`,确认能看到文件列表。
2. 打包一个**高版本**应用,上传到 `html/updates` 目录。
3. 在本地安装一个**低版本**应用。
4. 打开应用,系统应提示有新版本。
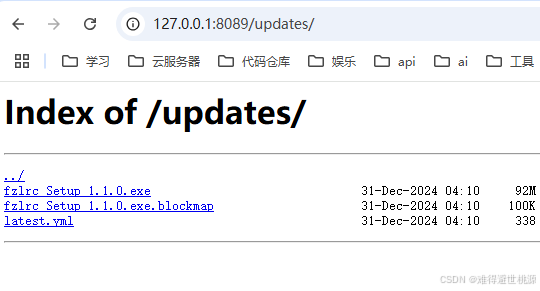[^6]: # 【Electron】打包后图标不变问题,图标问题
# 【Electron】打包后图标不变问题
## 问题描述
Windows 上图标已更换,但重新打包或安装后的 exe 文件图标未变。
## 排查与解决
**1. 验证是否真正生效**
右击 `exe` 文件 -> 属性。如果这里的图标已经显示为新图标,说明打包其实成功了,只是 Windows 图标缓存未刷新。
**2. 清除系统图标缓存**
1. 按 `Win + R` 打开运行。
2. 输入以下命令并回车:
```bash
ie4uinit -show
```
执行后,图标显示即可恢复正常。[^7]: # 微软授权 Windows MCP AI:Flow IPC 本地大模型实现全流程自动化
# 微软授权 Windows MCP AI:Flow IPC 本地大模型实现全流程自动化
## AI 主动生产工具的愿景
Flow IPC 展示了人工智能如何从被动辅助转变为主动生产力引擎。
## 示例:使用 Flow IPC 预订机票
系统通过自然语言指令完成了深圳飞往上海的机票预订流程:
1. 打开浏览器访问 Ctrip
2. 搜索出发地“深圳”
3. 输入目的地“上海”
4. 选择出发日期

## 核心优势
- **AI 驱动 vs 传统脚本**:具备自我纠错能力,自然语言指令即可完成复杂任务,无需大量代码。
- **跨软件自动化**:不仅能操作网页,还能控制本地应用(如启动网易云音乐播放、打开记事本记录)。
## 技术保障
- **微软官方授权**:拥有 Windows MCP (Microsoft Certified Professional) 认证,系统权限更高。
- **本地运行**:所有大模型在本地运行,数据不外泄,确保信息安全。

## 结论
Flow IPC 结合了**大模型本地化**、**系统高权限**与**跨软件自动化**,提供了一种安全、高效的生产力方案。[^8]: # SpringBoot + 文件分片上传 + 断点续传 + 秒传(MD5 校验):大文件上传优化全方案实战
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260202144730-atzb8c7)
## 正文
公众号名称:服务端技术精选
作者名称:服务端技术精选
发布时间:2026-02-01 18:00
原文链接:[http://www.jiangyi.space/articles/2026/02/01/1769749600834.html](http://www.jiangyi.space/articles/2026/02/01/1769749600834.html)
## 传统文件上传的痛点
在我们的日常开发工作中,经常会遇到这样的文件上传难题:
- 用户上传几个G的视频文件,网络中断导致上传失败,需要重新开始
- 大文件上传占用服务器大量带宽,影响其他用户访问
- 相同文件重复上传,浪费存储空间和带宽
- 上传进度无法实时显示,用户体验差
- 服务器内存被大量上传请求占满,导致服务不稳定
传统的单文件上传方式在面对大文件时显得力不从心。今天我们就来聊聊如何构建一个高效的大文件上传系统。
## 解决方案核心思路
### 1\. 文件分片上传
将大文件切分成多个小片段,分别上传,降低单次请求的压力。
### 2\. 断点续传
记录上传进度,网络中断后可以从断点继续上传,避免重新上传。
### 3\. MD5校验秒传
通过MD5校验判断文件是否已存在,实现秒传功能。
### 4\. 并发控制
合理控制并发上传的分片数量,平衡上传效率和服务器压力。
## 核心实现方案
### 1\. 文件分片处理
```java
@Service
public class FileChunkService {
/**
* 将大文件分割成多个小片段
* @param file 待分割的文件
* @param chunkSize 每个分片的大小(字节)
* @return 分片列表
*/
public List<FileChunk> splitFile(MultipartFile file, int chunkSize) {
List<FileChunk> chunks = new ArrayList<>();
long fileSize = file.getSize(); // 获取文件总大小
// 计算需要分成多少片:向上取整
int chunkCount = (int) Math.ceil((double) fileSize / chunkSize);
try {
InputStream inputStream = file.getInputStream();
byte[] buffer = new byte[chunkSize]; // 创建缓冲区
// 循环读取文件,每次读取一个分片的大小
for (int i = 0; i < chunkCount; i++) {
int bytesRead = inputStream.read(buffer); // 读取数据到缓冲区
if (bytesRead == -1) break; // 读到文件末尾
// 复制实际读取的字节数(最后一个分片可能小于chunkSize)
byte[] chunkData = Arrays.copyOf(buffer, bytesRead);
// 创建分片对象并设置属性
FileChunk chunk = new FileChunk();
chunk.setIndex(i); // 分片索引(从0开始)
chunk.setData(chunkData); // 分片数据
chunk.setTotalChunks(chunkCount); // 总分片数
chunk.setSize(bytesRead); // 当前分片大小
chunks.add(chunk);
}
} catch (IOException e) {
throw new RuntimeException("文件分片失败", e);
}
return chunks;
}
}
```
### 2\. MD5校验与秒传
```java
@Service
public class FileMd5Service {
/**
* 计算文件的MD5哈希值
* MD5用于唯一标识文件内容,实现秒传功能
* @param fileData 文件字节数组
* @return MD5字符串(32位十六进制)
*/
public String calculateFileMd5(byte[] fileData) {
try {
// 获取MD5摘要算法实例
MessageDigest md = MessageDigest.getInstance("MD5");
// 计算哈希值(字节数组)
byte[] hashBytes = md.digest(fileData);
// 将字节数组转换为32位十六进制字符串
StringBuilder sb = new StringBuilder();
for (byte b : hashBytes) {
// 每个字节转换为2位十六进制,不足补0
sb.append(String.format("%02x", b));
}
return sb.toString();
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("MD5算法不可用", e);
}
}
/**
* 检查文件是否已存在(用于秒传)
* @param md5 文件的MD5值
* @return true表示文件已存在,可以实现秒传
*/
public boolean isFileExists(String md5) {
// 检查文件是否已存在于数据库
return fileRepository.existsByMd5(md5);
}
/**
* 检查某个分片是否已上传(用于断点续传)
* @param md5 文件的MD5值
* @param chunkIndex 分片索引
* @return true表示该分片已存在,无需重复上传
*/
public boolean isChunkExists(String md5, int chunkIndex) {
// 检查分片是否已存在
return fileChunkRepository.existsByMd5AndChunkIndex(md5, chunkIndex);
}
}
```
### 3\. 上传进度管理
```java
@Service
public class UploadProgressService {
// 使用并发安全的Map存储上传进度
// key: 上传任务ID(通常使用文件MD5),value: 上传进度对象
private final Map<String, UploadProgress> progressMap = new ConcurrentHashMap<>();
/**
* 更新上传进度
* @param uploadId 上传任务ID
* @param currentChunk 当前已完成的分片数
* @param totalChunks 总分片数
*/
public void updateProgress(String uploadId, int currentChunk, int totalChunks) {
// 如果不存在则创建新的进度对象,存在则直接获取
UploadProgress progress = progressMap.computeIfAbsent(uploadId, k -> new UploadProgress());
// 更新进度信息
progress.setUploadId(uploadId);
progress.setCurrentChunk(currentChunk);
progress.setTotalChunks(totalChunks);
// 计算完成百分比
progress.setPercentage((currentChunk * 100) / totalChunks);
// 更新最后更新时间(用于清理过期任务)
progress.setLastUpdateTime(LocalDateTime.now());
}
/**
* 获取上传进度
* @param uploadId 上传任务ID
* @return 上传进度对象
*/
public UploadProgress getProgress(String uploadId) {
return progressMap.get(uploadId);
}
/**
* 移除上传进度(上传完成后清理)
* @param uploadId 上传任务ID
*/
public void removeProgress(String uploadId) {
progressMap.remove(uploadId);
}
}
```
### 4\. 分片上传接口
```java
@RestController
@RequestMapping("/api/upload")
public class FileUploadController {
@Autowired
private FileChunkService fileChunkService; // 文件分片服务
@Autowired
private FileMd5Service fileMd5Service; // MD5校验服务
@Autowired
private UploadProgressService uploadProgressService; // 上传进度服务
/**
* 上传单个分片接口
* 前端需要循环调用此接口,直到所有分片上传完成
*/
@PostMapping("/chunk")
public ResponseEntity<UploadResponse> uploadChunk(
@RequestParam("file") MultipartFile file, // 分片文件数据
@RequestParam("md5") String fileMd5, // 整个文件的MD5
@RequestParam("chunkIndex") int chunkIndex, // 当前分片索引
@RequestParam("totalChunks") int totalChunks) { // 总分片数
// 1. 检查是否已存在该分片(断点续传:如果分片已存在则跳过)
if (fileMd5Service.isChunkExists(fileMd5, chunkIndex)) {
// 分片已存在,跳过上传
uploadProgressService.updateProgress(fileMd5, chunkIndex + 1, totalChunks);
return ResponseEntity.ok(new UploadResponse("SUCCESS", "分片已存在"));
}
// 2. 保存分片到数据库或临时存储
FileChunk chunk = new FileChunk();
chunk.setMd5(fileMd5); // 绑定到整个文件的MD5
chunk.setChunkIndex(chunkIndex); // 分片索引
chunk.setTotalChunks(totalChunks); // 总分片数
chunk.setData(file.getBytes()); // 分片数据
chunk.setFileSize(file.getSize()); // 分片大小
fileChunkRepository.save(chunk);
// 3. 更新上传进度(前端可通过进度接口查询)
uploadProgressService.updateProgress(fileMd5, chunkIndex + 1, totalChunks);
return ResponseEntity.ok(new UploadResponse("SUCCESS", "分片上传成功"));
}
/**
* 完成上传接口
* 所有分片上传完成后,调用此接口合并分片
*/
@PostMapping("/complete")
public ResponseEntity<UploadResponse> completeUpload(
@RequestParam("md5") String fileMd5, // 文件MD5
@RequestParam("fileName") String fileName,// 文件名
@RequestParam("fileSize") long fileSize) { // 文件大小
// 1. 检查所有分片是否上传完成
int uploadedChunks = fileChunkRepository.countByMd5(fileMd5);
Optional<FileChunk> firstChunk = fileChunkRepository.findFirstByMd5(fileMd5);
// 判断:已上传分片数 == 总分片数
if (firstChunk.isPresent() && uploadedChunks == firstChunk.get().getTotalChunks()) {
// 2. 合并所有分片为一个完整文件
mergeChunks(fileMd5, fileName);
// 3. 记录文件信息到数据库
FileInfo fileInfo = new FileInfo();
fileInfo.setMd5(fileMd5);
fileInfo.setFileName(fileName);
fileInfo.setFileSize(fileSize);
fileInfo.setFilePath(generateFilePath(fileMd5, fileName));
fileInfo.setUploadTime(LocalDateTime.now());
fileRepository.save(fileInfo);
// 4. 清理临时分片(释放存储空间)
cleanupTempChunks(fileMd5);
// 5. 清理进度信息
uploadProgressService.removeProgress(fileMd5);
return ResponseEntity.ok(new UploadResponse("SUCCESS", "文件合并完成"));
} else {
// 分片不完整,返回错误
return ResponseEntity.badRequest()
.body(new UploadResponse("ERROR", "分片上传不完整"));
}
}
}
```
## 前端配合实现
### 1\. 文件分片上传
```javascript
/**
* 前端文件分片上传入口函数
* @param {File} file - 用户选择的文件对象
*/
function uploadFile(file) {
const chunkSize = 2 * 1024 * 1024; // 2MB:每个分片大小
const chunks = []; // 存储所有分片
let start = 0; // 当前读取位置
// 计算文件MD5(用于秒传和标识文件)
const fileReader = new FileReader();
fileReader.onload = function(e) {
// 使用SparkMD5库计算文件MD5
const md5 = SparkMD5.ArrayBuffer.hash(e.target.result);
// 检查是否秒传(服务器是否已有该文件)
checkFileExists(md5).then(exists => {
if (exists) {
console.log('文件已存在,秒传成功');
return;
}
// 不能秒传,进行分片上传
// 循环切割文件:每次切取chunkSize大小的片段
while (start < file.size) {
const chunk = file.slice(start, start + chunkSize);
chunks.push({
index: chunks.length, // 分片索引
data: chunk // 分片数据
});
start += chunkSize; // 移动读取位置
}
// 开始上传所有分片
uploadChunks(chunks, md5);
});
};
// 读取文件内容(用于计算MD5)
fileReader.readAsArrayBuffer(file);
}
```
### 2\. 上传进度展示
```javascript
/**
* 并发上传分片
* 使用递归方式控制并发数量,避免服务器压力过大
* @param {Array} chunks - 分片数组
* @param {String} fileMd5 - 文件MD5
*/
function uploadChunks(chunks, fileMd5) {
let uploadedChunks = 0; // 已上传的分片计数
// 并发上传分片,限制并发数为3
const concurrentLimit = 3;
const uploadingQueue = [...chunks]; // 复制一份用于队列管理
// 递归函数:上传下一个分片
const uploadNext = () => {
// 队列为空,说明所有分片已上传完成
if (uploadingQueue.length === 0) {
// 所有分片上传完成,通知服务器合并文件
completeUpload(fileMd5);
return;
}
// 从队列头部取出一个分片
const chunk = uploadingQueue.shift();
// 构建FormData(用于文件上传)
const formData = new FormData();
formData.append('file', chunk.data); // 分片数据
formData.append('md5', fileMd5); // 文件MD5
formData.append('chunkIndex', chunk.index); // 分片索引
formData.append('totalChunks', chunks.length); // 总分片数
// 发送上传请求
fetch('/api/upload/chunk', {
method: 'POST',
body: formData
}).then(response => {
uploadedChunks++;
// 计算上传进度百分比
const progress = (uploadedChunks / chunks.length) * 100;
// 更新进度条UI
updateProgressBar(progress);
}).finally(() => {
// 无论成功失败,都继续上传下一个分片
uploadNext();
});
};
// 启动并发上传:同时发起concurrentLimit个请求
for (let i = 0; i < concurrentLimit && i < chunks.length; i++) {
uploadNext();
}
}
```
## 高级特性实现
### 1\. 断点续传
```java
/**
* 断点续传检查接口
* 用户重新上传时,先调用此接口查询哪些分片已存在
*/
@PostMapping("/resume-check")
public ResponseEntity<ResumeCheckResponse> checkResume(
@RequestParam("md5") String fileMd5, // 文件MD5
@RequestParam("totalChunks") int totalChunks) { // 总分片数
// 1. 从数据库查询已上传的分片索引
List<Integer> uploadedChunks = fileChunkRepository.findUploadedChunkIndexes(fileMd5);
// 2. 构建响应数据
ResumeCheckResponse response = new ResumeCheckResponse();
// 找出缺失的分片(需要重新上传的分片索引)
response.setNeedUploadChunks(findMissingChunks(uploadedChunks, totalChunks));
// 计算当前上传进度(百分比)
response.setUploadProgress(uploadedChunks.size() * 100 / totalChunks);
return ResponseEntity.ok(response);
}
```
### 2\. 并发控制
```java
/**
* 并发控制服务
* 使用信号量(Semaphore)限制同时上传的分片数量
* 防止大量并发请求压垮服务器
*/
@Service
public class ChunkUploadThrottler {
// 创建信号量,设置最大并发数为10
// 同一时间最多允许10个分片在上传
private final Semaphore semaphore = new Semaphore(10);
/**
* 获取上传许可(如果已达到并发上限,则阻塞等待)
*/
public void acquire() throws InterruptedException {
semaphore.acquire();
}
/**
* 释放上传许可(上传完成后必须调用)
* 让其他等待的上传请求可以执行
*/
public void release() {
semaphore.release();
}
}
```
### 3\. 文件合并优化
```java
/**
* 文件合并方法
* 将所有分片按顺序合并成一个完整文件
* 使用NIO的FileChannel提高IO性能
*/
private void mergeChunks(String fileMd5, String fileName) {
try {
// 1. 从数据库查询所有分片(按索引排序)
List<FileChunk> chunks = fileChunkRepository.findByMd5OrderByChunkIndex(fileMd5);
// 2. 生成最终文件的存储路径
String filePath = generateFilePath(fileMd5, fileName);
Path outputPath = Paths.get(filePath);
// 3. 使用FileChannel进行高效文件写入
try (FileChannel outputChannel = FileChannel.open(outputPath,
StandardOpenOption.CREATE, // 文件不存在则创建
StandardOpenOption.WRITE)) { // 写入模式
// 4. 遍历所有分片,按顺序写入
for (FileChunk chunk : chunks) {
// 将分片数据包装成ByteBuffer
ByteBuffer buffer = ByteBuffer.wrap(chunk.getData());
// 写入到输出文件
outputChannel.write(buffer);
}
}
} catch (IOException e) {
throw new RuntimeException("文件合并失败", e);
}
}
```
## 性能优化策略
### 1\. 内存优化
- 使用流式处理,避免将整个文件加载到内存
- 合理设置分片大小,平衡内存使用和网络效率
### 2\. 存储优化
- 及时清理已完成合并的临时分片
- 使用对象存储服务存储最终文件
### 3\. 网络优化
- 合理设置并发上传数量
- 实现分片压缩传输
## 最佳实践建议
1. **分片大小选择**:通常2-5MB为宜,根据网络环境调整
2. **并发控制**:限制并发上传数量,避免服务器压力过大
3. **临时文件清理**:设置过期时间,自动清理未完成的上传
4. **安全考虑**:验证文件类型和大小,防止恶意上传
5. **监控告警**:监控上传成功率、失败率等关键指标
通过这套完整的大文件上传方案,我们可以有效解决传统文件上传的各种痛点,提供流畅的用户体验。[^9]: # java研发工程师必知必会
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260202140315-9mk0qaz)
## 正文
公众号名称:朝花夕拾人牙慧
作者名称:进击的拾穗者
发布时间:2026-01-23 22:20
java作为一种跨平台、面向对象的编程语言,广泛应用于企业级Web开发和移动应用开发。其核心特性包括可移植性(一次编写,到处运行)、安全性、分布式支持以及泛型编程能力。又因其简单易学深受广大程序员所喜爱。自1995年推出以来,语言也经历了多次的迭代更新,而对于一些较早接触该语言的老程序员来说,对一些新特征甚至语言层面的优化或许并不熟悉,针对一些较为常见的语言特征,在本文中进行了较为细致的入门介绍,希望能在学习语言的过程中起到积极的作用。另外由于水平有限,对某些特性的理解或许存在偏差,如果您发现有任何问题,欢迎随时交流学习。
## 常见问题解析
### 1、volatile在线程安全中能保证什么
通常以为,使用volatile变量就可以保证线程安全.事实真的如此吗?
其实,volatile只能保障的是可见性和排序,并不能保证操作的原子性,更不能防止竞态条件(race conditions)的发生.当一个变量被标记为volatile时,1) 某线程对该变量的任何写入操作会立即对其他线程可见;2) 读写操作不会对该变量的相关操作进行重排序.
```java
volatile int i;
i++;
```
代码中变量i虽然使用volatile修饰,但其并不是线程安全的,因为i++不是一个原子操作,它包含1 读取数值;2 加1;3 写回数值.因volatile修饰变量不能保证原子性,当两个线程同时执行上述代码,便会导致线程安全的问题.
### 2、是否应该选择synchronized锁
长久以来的认知告诉我们,synchronized速度慢,要避免使用.选用替代方案concurrent.lock包下的作为替代方案.从jdk1.6开始,针对synchronized的优化已经显著提高了其性能,jdk1.6引入了”锁升级”机制, 将锁的状态分为四种:无锁 → 偏向锁 → 轻量级锁 → 重量级锁。JVM 会根据线程竞争情况动态升级锁,避免不必要的开销.
许多情况下, synchronized由JVM优化,比手动锁定更快,语义也更容易理解.但当多个线程争用一个synchronized锁时,速度会变慢.如下代码中,如果doSomeThing()抛出异常,会发生什么情况?
```java
synchronized (lock) {
doSomeThing();
}
```
锁会自动释放!
同样如果使用手动锁,则必须注意锁释放.如使用ReentrantLock,需注意解锁某个finally区域,否则,一旦异常该区域将永远保持锁定状态,出现死锁.
```java
lock.lock();
try {
doSomeThing();
} finally {
lock.unlock();
}
```
### 3、可以使用Thread.sleep()协调线程吗
答案是否定的.因为Thread.sleep()并不能保证时间,不能协调状态,会在机器低速运转或重载时发生故障.想要正确的协调线程,需使用:
1、wait()/notify();
2、CountDownLatch;
3、CyclicBarrier;
4、CompletebleFuture.
那么,wait()和sleep()之间有什么区别呢?
#### wait()和sleep()的区别
其区别主要包括
1. **锁机制**:sleep()不释放锁,线程将占用cpu资源;wait()会释放监视器锁
2. **使用位置**:sleep()可以在任何地方使用,而wait()必须在synchronized代码块/方法中使用
3. **用途**:sleep()作用是暂停执行(休眠),而wait()作用是线程间通信
4. **唤醒条件**:sleep()的唤醒条件是超时自动唤醒,而wait()需等待notify()或notifyAll()
用一个日常生活中的场景大致描述一下,sleep()类似于你在床上看书,看累了抱着书躺下睡觉,虽然你不再看书,但因为书被你抱着,其他人是没法去看你手中的书.wait()类似你去排队出地铁站,在出站前你发现手机支付地铁票有问题,于是你让出排队通道去修复地铁卡手机支付,其他人依次跟上排队出站,等你解决了支付问题,又重新排进了出站队伍中.
在系统中,特别是多线程系统中使用sleep()只会降低系统性能.
### 4、多线程环境中,双重检查一定是安全的吗?
以下代码,在多线程环境中,是否存在问题?
```java
public class MyClass {
private static MyClass instance;
public static MyClass getInstance() {
if (instance == null) {
synchronized (MyClass.class) {
if (instance == null) {
instance = new MyClass();
}
}
}
return instance;
}
}
```
答案是肯定的。问题的根本是因为指令重排的存在,而JVM在执行instance = new MyClass();这行代码时,其操作并不是原子的,通常分为三个步骤:
1. **分配内存空间**:为对象分配一块内存
2. **初始化对象**:在内存中构造对象(执行构造函数)
3. **引用赋值**:将 instance 变量指向刚才分配的内存地址
而JVM和CPU为了优化性能,这三个步骤并不是严格的顺序执行的.这便可能导致另一个线程可能会看到一个半初始化的对象.而修复此问题便可以通过使用添加volatile修饰禁止其重排序修复后代码如下
```java
public class MyClass {
// 必须增加 volatile 关键字
private static volatile MyClass instance;
public static MyClass getInstance() {
if (instance == null) {
synchronized (MyClass.class) {
if (instance == null) {
instance = new MyClass();
}
}
}
return instance;
}
}
```
### 5、Java对象创建经历哪些阶段?
Java对象创建的五个阶段——类加载检查、内存分配、零值初始化、对象头设置和执行<init>方法——在逻辑上是顺序执行的。这些步骤共同构成了Java虚拟机(JVM)实例化对象的过程,按照由前到后的顺序保证了对象在内存中的正确配置和初始化。
具体细节如下:
1. **类加载检查**:虚拟机检查new指令的参数能否在常量池中定位到一个类的符号引用,并检查该类是否已加载、解析和初始化
2. **内存分配**:在类加载检查通过后,虚拟机为对象在堆中分配内存
3. **零值初始化**:将分配的内存空间初始化为零值(不包含对象头),保证字段在该阶段就能使用默认值
4. **对象头设置**:设置对象头,包括哈希码、GC分代年龄、锁状态标志等
5. **执行**:执行开发者定义的构造函数,按照程序员的意愿对对象进行初始化[^10]: # 基于一个 Claude Code 自动编程真实案例,为大家分享一些提示词技巧
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260203070138-e3pqrxx)
## 正文
## 案例背景
公众号名称:这波能反杀
作者名称:这波能反杀丶
发布时间:2026-01-17 11:01
### 原始需求

这篇文章,通过一个真实的案例,给大家分享一下 Claude Code 的真实使用案例。分享之前,先来做一个小调查
原始需求:是有一位尊贵的付费用户,它希望我在文章中,增加文章的更改时间
这个需求咋眼一看,实现起来有点困难。因为我网站的文章,并没有存储在数据库,都是利用 `next.js` 的 SSG 来构建的。他压根就没有更新时间。
### 为什么不能直接把原始需求喂给 AI
这里的一个技巧就是:在解决问题时,**我们不要直接把原始需求喂给**`Claude Code`,有如下几个原因
1. **需求模糊**:原始需求相对模糊,AI 可能理解偏差,最终实现的结果不一定靠谱
2. **成本高昂**:Claude Code 的 Token 消耗特别贵,模糊的需求可能导致大量 Token 被无意义消耗
因此,我们要对原始需求进行一次拆解,我先在 deepseek 中咨询了一下,deepseek 给了我两个方案
### 方案对比
## 解决方案探索
1、文件构建时间,每次 build 时,我们需要获取文件的构建时间,但是 `turbopack` 的打包策略还有点不太一样,它每次构建时,文件的 hash 值都会更改,这个构建时间可能不太靠谱
2、**git 提交的时间**,我一想,这个应该是比较靠谱的
### 提示词设计
有了大致的解决方向之后,我就有了这个简单的提示词:**把** **`git`** **提交时间编译在每一篇** **`.mdx`** **文章的头部**

`Claude Code` 还是比较靠谱的,如果提示词比较精准,总体来说还是没啥毛病,嘎嘎就是一顿执行
## 实施过程


在耗费了我 **7 美元**的额度之后,耗时 20 分钟左右,终于执行成功了。
### 第一阶段:初次执行
不出意外的话,就出现意外了,它居然跳过了 `171` 个文件的更改.

### 第二阶段:遇到问题
这里一个很坑的地方就在这里,实际上这里被跳过的文件,仅仅只是额外传入了一个 `pass` 参数,其他都完全一样
```
...
```
可是他不知变通,把多传的这个额外参数,定义成为了完全不同的自定义组件。然后就跳过不处理了 ~ ~
### 第三阶段:踩坑经历
```tsx
// 对于那 171 个被跳过的自定义 layout 文件,如果你也想添加 git 信息,需要手动修改它们的 layout.tsx,在调用 时传入 gitInfo 属性:
import Layout from 'components/post-layout';
import { getGitFileInfo } from '@/utils/git-info';
export default function Article({ children }: any) {
const gitInfo = getGitFileInfo('src/app/你的路径/page.mdx');
return (
{children}
);
}
```
但是真实的情况是,我需要的结果是这样,运行的结果是完全一致的。
```tsx
import MdxLayout from 'components/mdx-layout';
export default function Article({ children }: any) {
return (
{children}
);
}
```
然后这个时候,我就在提示词上面,踩了一个坑
我再次输入提示词:**使用跟上面一样的方式把跳过的 171 个文件重构一下**
我的这个表达呢,细想一下它有**一点歧义**。因为 Claude Code 已经给了我一个建议的方案,但是我不认可这个方案,我的本意是,用已经修改了的几百个文件那样的方案修改被跳过的文件,但是在执行的过程中,被它理解成为了:上面它给我建议的那个方案
这一点歧义,直接导致它按照我不想要的方案嘎嘎执行了 20 分钟,中间还出现了 2 次错误自我修复,嘎嘎猛吞我的 token,两种歧义开始打架导致了错误。
最终我又不得不重新放弃这次执行,重新明确我的语义。
## 总结
1、提示词之中,最好能够包含相对稳定准确的解决方案,让 AI 思考得越少越少,这样能减少幻觉率。
2、需求的提示词里一定不要有歧义,有歧义容易导致出错,虽然 Claude Code 最终可以修复,但是这样会造成大量的 token 消耗。并且由于 LLM 是基于预测机制产出结果,早期的误读、歧义等,都会导致后续的每一步都在错误的方向上越走越远,并且它还会尝试逻辑自洽,生成一些不存在的东西,越写问题越大,也增加开发者的审核难度,如果你被它的幻觉骗过去了,那就会造成严重的后果
3、自然语言的约束力度不如代码精准、在提示词中,包含文件名、代码变量、代码专有词、专业术语等,会极大的减少 Cluade Code 的幻觉[^11]: # 不会设计也能搭出高级感网页:小白可用的 AI Coding 提示词模板 & 精品组件库推荐
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260203155130-qa3oprm)
## 正文
公众号名称:Bay的设计奥德赛
作者名称:BayJ
发布时间:2026-01-07 20:00

# 前言
在[上一篇文章](/uploads/shares/4/assets/笔记同步助手/attachments/上一篇文章-20260203155135-9er89wt)中,我们测评了 11 款 AI Coding 产品,希望能帮和我一样的编程小白们跨过代码的门槛。
然而新的问题接踵而来 —— 明明用的是同一个模型、同一款产品,有的朋友能让 AI 搭出惊艳的网站,也有朋友觉得自己生成的效果总差点意思。这篇文章中,我们将拆解如何通过参考图、顶级组件库以及更精准的视觉提示词,把脑海中那个模糊的好看,精准地翻译给 AI ,让它真正成为更懂审美的编程搭档。
以下是本文大纲:

为方便大家查看,我将本文涉及的「主流网页设计风格」、「代码组件库」多维表及完整提示词技巧整理到了飞书链接中,在公众号后台回复关键词 **「网页高级感指南」** 即可获取。
# **一.使用图片/链接/关键词模仿流行风格**
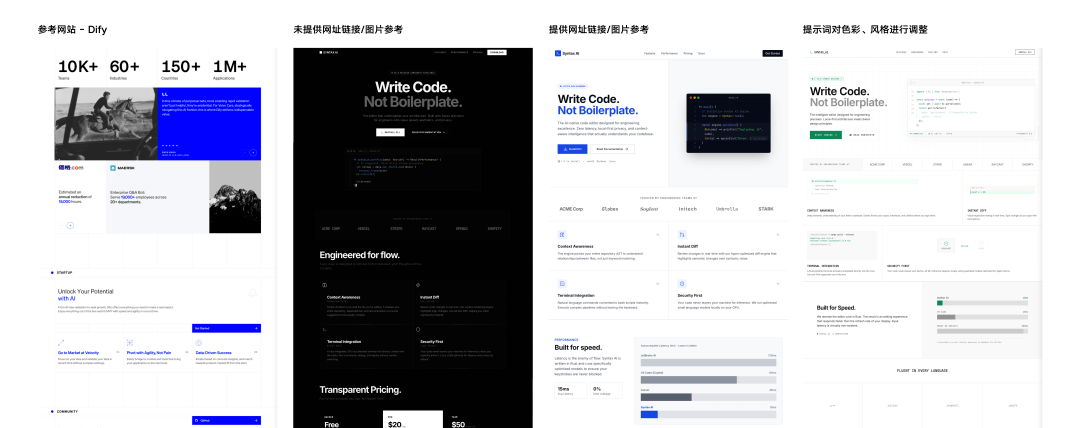
如果你对自己的产品有明确的风格倾向,那么可以通过同时提供参考图片、示例网站链接和风格关键词的方式,指导模型输出。虽然这三类输入看似简单,但在模型理解上各有不同作用:
- **参考图片(Reference Image)** :帮助模型快速锁定整体的色彩氛围与版式构图;
- **示例链接(Example Link)** :引导模型深入学习真实网页的代码结构、元素密度及交互细节,确保生成的页面符合成熟的网页标准;
- **风格关键词(Style Keywords)** :能起到差异化修正的作用 —— 通过提示词指定特定的字体或品牌色,你可以强制模型在模仿参考网页结构的同时,改变其视觉,避免千篇一律的机械模仿,生成具有独特辨识度的设计。
组合使用这三种输入,能有效收敛模型在审美上的随机发挥,让最终产出无限接近你的设计预期。下面是几组案例对比:
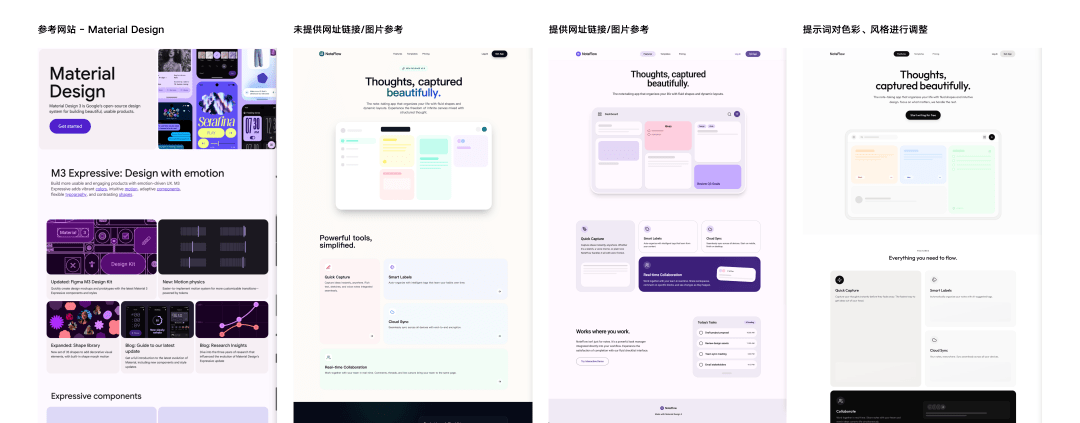
Material Design
结构线风格
我梳理了主流网站风格的介绍,方便大家在网站制作时进行灵感参考。
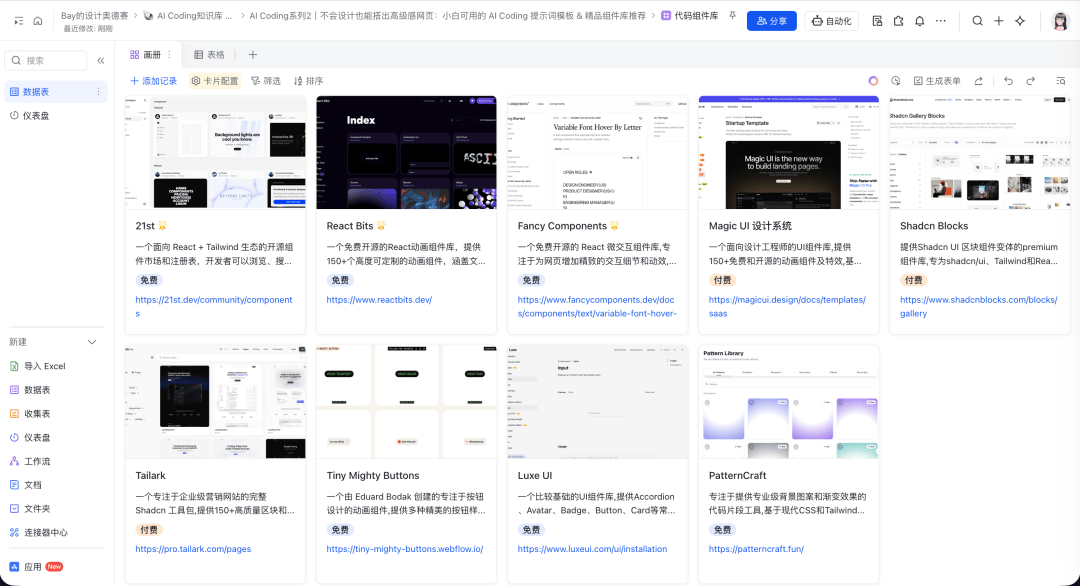
# **二.** 参考优质组件库
优质组件库通常包含经过大量产品验证的布局、动效与交互模式。把这些组件引入生成页面,可以让网页瞬间具备更专业、稳定的质感。我精选了一批优秀的代码组件库放在了多维表格中。
公众号后台回复关键词 **「网页高级感指南」** 即可获取。
下面我们来示范:在已经由 Gemini 3 生成基础页面的情况下,如何嵌入 21st.dev 的组件。
在使用组件时,关键是让它们的结构与页面现有样式尽可能自然融合。如果你只想借用动效逻辑,而组件本身的视觉风格与你的网站差异较大,也没关系—— 可以直接把原组件的代码复制给 AI,请它协助拆解与改写,让动效适配你的页面结构。
以上一节的结构线风格网站为例,我想在 Hero 区域引入一个「鼠标悬浮显现字母」的交互组件,如下图所示:

点开21st中的组件详情页,左侧「How to use」模块中,,你可以选择「Copy prompt」 或者 「Copy code」的方式进行组件使用,这里我选择了「Copy prompt」 可以选择不同代码工具。
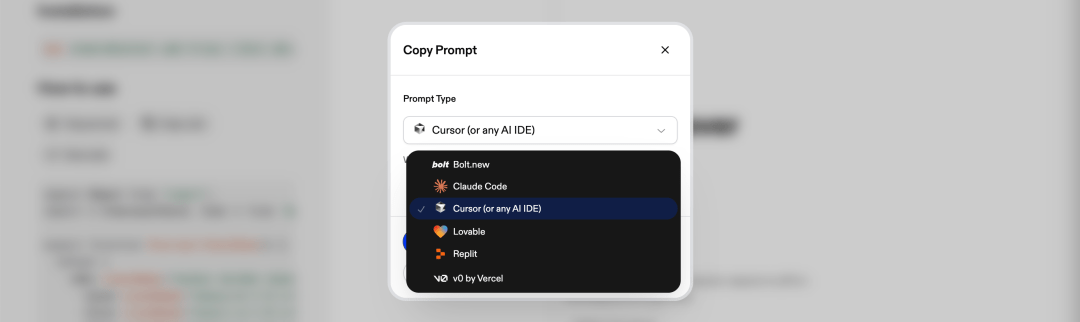
值得注意的是,原始 Prompt 通常包含组件自带的样式定义。为了让它完美融入我的设计系统,我在投喂给 AI 之前添加了额外指令,要求代码工具剥离原组件的视觉样式,仅保留核心交互逻辑:

将这段 Prompt 输入代码工具后,AI 迅速修改了代码,很快就实现了初步效果。
# 三.优化设计需求,让模型掌握视觉重点
当我们做的是实际项目,页面中需要呈现的内容往往是最先确定好的,此时我们可以将需求描述发给 Gemini 3 Pro,借助模型强大的联想能力,帮助我们清晰撰写一篇包含功能、设计要求的Prd,模型可以帮我们主动标记页面重点,甚至主动规划模块中的布局方式,而这样的提示词可以帮助模型生成网页时清晰理解不同文本、内容结构关系、了解页面的视觉重心。

两个版本的提示词及生成效果对比,可以看到,右侧对风格加入了更明确的页面元素与风格指令,在页面的结构线背景、配图细节等方面,效果明显更好。

那么如何获得右侧的提示词呢?我们可以将初版需求和以下Prompt一起发送给Gemini 3 Pro,让Gemini帮忙优化。

不过需要强调的是,在模型能力极大增强的今天,Prompt 的作用只是锦上添花。写的越多不等于效果越好。过于冗长、琐碎的指令反而会增加模型的认知负担,降低核心指令的权重,导致模型顾此失彼。因此精准远比冗长更重要。保持克制,从简单的指令开始,只增加必要约束。
# 四.用.md规范管理多页面风格一致性
## 形成规范的重要性
假设此时你已经从上述流程得到了一个不错的网页效果,但你想开发一套拥有多个页面的大型项目,那么设计规范的统一管理就相对重要了 —— 如果只是简单让AI 复用其他页面的设计样式,AI产出的结果在不同页面的用色、字号、间距有可能会出现差异,导致整体观感不统一。
我们需要将隐性的视觉显性化为设计需求文档。你可以直接向 AI 提要求,得到包含所有细节特征的.md 文档,同时,使用Markdown 有助于模型区分指令、上下文和任务。
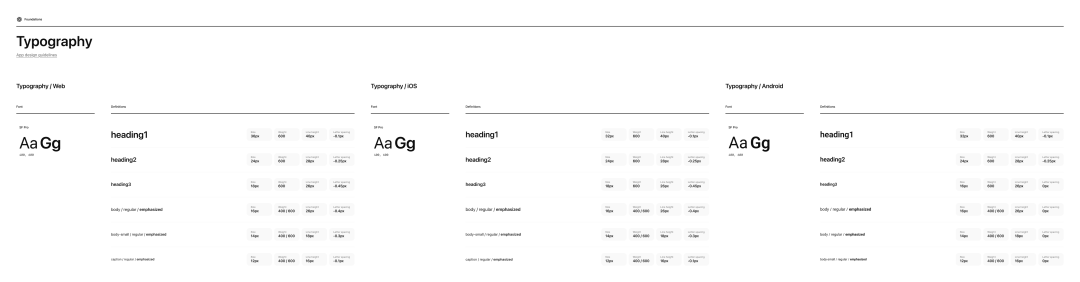
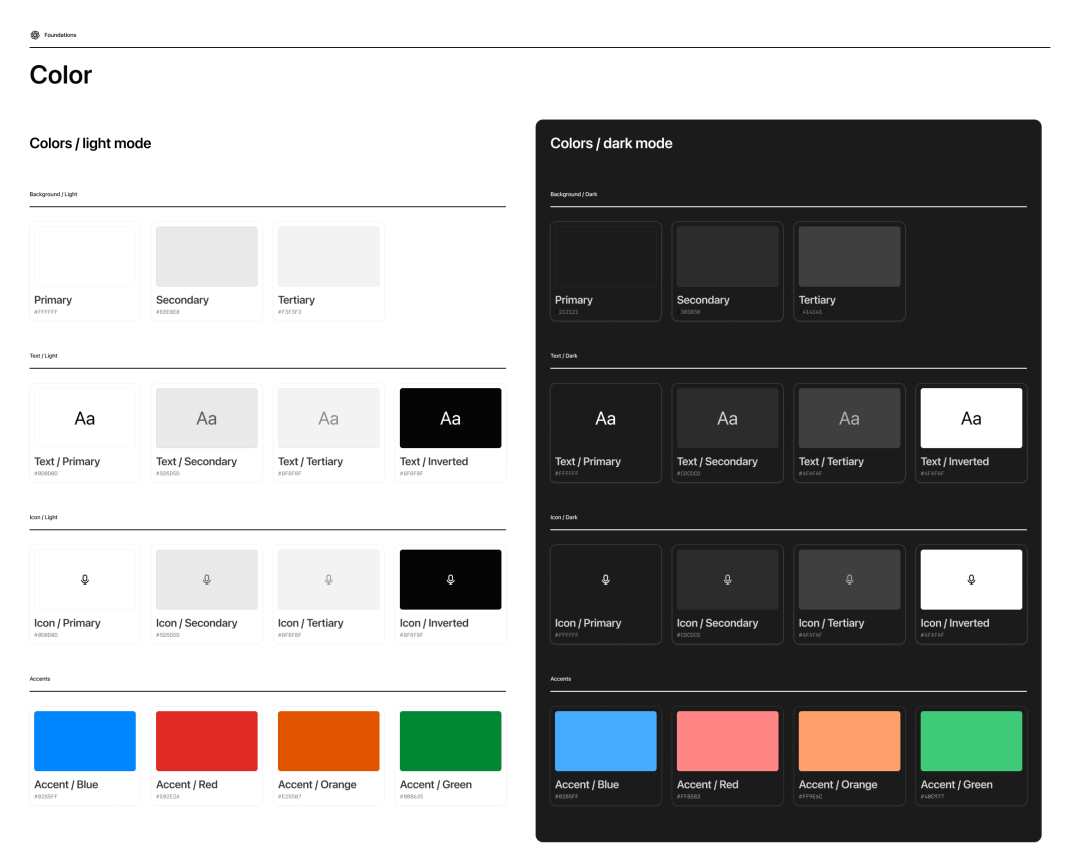
传统大型项目需要由设计师整理 Design Token
这种做法是有迹可循的,例如 Figma Make 在生成 Web app 时,会优先读取 `guidelines`文件夹里的内容,从 `Guidelines.md` 开始,把其中的文字当作额外上下文和约束。
Figma Make 的官方规范模板
## 让 AI 总结设计规范
那么,我们需要让AI帮忙建立的设计规范应该包含哪些维度呢?
其实很简单,只需要提取出核心的设计变量:
- **色彩系统 (Colors)** :主色、辅色、背景色、边框色(最好对应 Tailwind 类名);
- **排版系统 (Typography)** :标题、正文的字号与行高;
- **组件质感 (Components)** :圆角大小 (Radius)、阴影 (Shadow)、边框厚度;
- **布局间距 (Spacing)** :常用的内边距 (Padding) 和 间隙 (Gap)。
下面我们给出一个 Prompt 模板,你可以拿去输入给 Coding工具,让其将网站详细的设计规范总结成设计需求文档,并方便复用在其他页面中。

以上提到的所有提示词都可以在公众号后台回复关键词 **「网页高级感指南」** 访问原文获取。
我们将这个提示词输入给AI,很快文档就写好了

然后我们便可以让AI参考 **Design System.md** 文件进行Pricing页面生成,可以看到设计细节是基本一致的。

# 结语
到这里,我们已经掌握了生成高级感网页的组合拳,相信你已经迫不及待去生成自己的网页了。
不过,要让你的产品从Demo升级为具有独立灵魂的产品,我们需要了解更具体的设计规则,在此基础上根据目标人群与品牌调性,做出更明确的设计决策。
这时候,你该如何精准地发号施令去微调设计细节?这就需要一点点专业的设计知识来兜底。
下周,本系列将迎来最终章 ——《AI 编程颜值急救课》,我将介绍设计师压箱底的字体、配色与排版知识。那我们下篇见啦!
[^12]: # 将 SVN 仓库迁移到 Git
## **背景说明**
SVN(Subversion)是一个集中式的版本控制工具,与Git相比,其劣势明显:
- SVN的集中式管理限制了广泛参与,仅少数特权用户能协同编辑,难以满足开源社区的开放需求。
- SVN的提交须经服务器,网络依赖重、效率低,且缺失代码审核机制,质量难以保证。
## 参考方案
Git已成为主流的版本控制系统,转向Git前,建议您先明确迁移范围,根据需求挑选最佳的迁移方案。
### 方案一:仅需要迁移SVN的最新数据
如果仅需要迁移SVN的最新数据,不需要迁移SVN的提交历史记录,那么迁移操作非常简单。只需要 `svn` 和 `git` 两个工具即可完成迁移,操作如下。
- 使用以下命令从SVN仓库检出最新文件到本地工作区:
```bash
svn checkout <SVN_URL>
```
- 在本地工作区执行以下命令,完成本地Git仓库的初始化:
```bash
git init
```
- 编辑 `.git/info/exclude` 文件,添加 `.svn` 等条目以便忽略工作区中的SVN管理目录:
```bash
echo ".svn" >> .git/info/exclude
```
- 执行以下命令创建Git提交:
```bash
git add -A
git commit -m "Initial commit from SVN"
```
- 在远程Git服务器上创建代码仓库,假设仓库地址的示例地址为 `<URL>`。
- 执行以下命令将本地工作区和远程仓库地址相关联:
```bash
git remote add origin <URL>
```
- 执行以下命令将本地Git仓库的分支推送到远程仓库中:
```bash
git push -u origin HEAD
```
该迁移方式和普通Git仓库推送服务端一致,不再赘述。
### 方案二:需要迁移 SVN 的全部历史
如果需要迁移SVN的历史提交,或者需要迁移多个分支和标签,则需要安装和使用 `git-svn` 实现 SVN仓库到Git仓库的迁移。
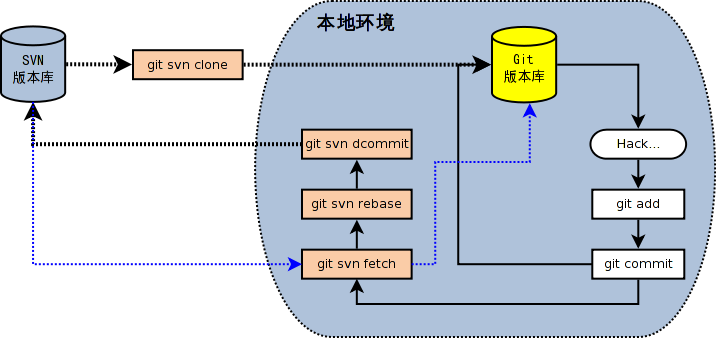
作为Git的一条子命令,`git-svn` 可以桥接远端的SVN仓库和本地的Git仓库,允许用户使用Git操作远端的SVN仓库。
`git-svn` 支持如下操作:
- 使用以下命令将远程的SVN代码仓库克隆到本地Git仓库:
```bash
git svn clone <SVN_URL>
```
- 使用 Git 命令在本地工作区中创建提交。
- 使用以下命令将本地的Git提交推送到SVN仓库上,创建SVN提交:
```bash
git svn dcommit
```
- 使用以下命令持续从SVN仓库同步提交到本地仓库:
```bash
git svn fetch
```
借助 `git-svn`,SVN仓库的完整历史将无损转为Git仓库,让迁移与协作更加流畅。
**针对方案二,迁移操作具体流程如下:**
1. **安装 git-svn**
Git的内置子命令 `git-svn` 和其他的子命令不同,不是编译后的原生可执行程序,而是一个Perl脚本,在运行时依赖svn的perl模块。
1. 以Ubuntu操作系统为例,首先安装Git和svn:
```bash
apt-get install git subversion
```
2. 单独安装 `git-svn` 和svn的perl模块:
```bash
apt-get install git-svn libsvn-perl
```
2. **探测 SVN 仓库布局**
SVN通过简单目录拷贝即可创建分支,灵活性极高,连不同版本或不完整的文件树也能变身分支。但这种混合管理策略,让自动化识别仓库中的分支变得棘手,极具挑战性。
要从SVN仓库的目录结构布局推测其分支和标签设置,以及主干分支和其他分支、标签的映射方式,关键在于理解SVN的标准目录结构及其含义。
- #### SVN 仓库标准目录结构
SVN 仓库通常采用以下标准目录结构:
/项目根目录
├── trunk
├── branches
│ ├── feature-1
│ ├── feature-2
│ └── ...
├── tags
│ ├── v1.0.0
│ ├── v1.1.0
│ └── ...
- trunk:主干分支,存放项目的主开发线。
- branches:存放各个功能分支或开发分支。
- tags:存放各个版本的标签,通常用于标记发布版本。
- #### **查看 SVN 仓库的根路径**
使用 `svn info` 命令可以查看给定地址的SVN仓库的根路径和其他信息。
```bash
svn info https://example.com/svn/repo/trunk
```
以下是一个示例脚本,用于查看SVN仓库的根路径,并根据目录结构猜测分支和标签的设置:
```bash
#!/bin/bash
# 输入 SVN 仓库 URL
SVN_URL="https://example.com/svn/repo"
# 获取 SVN 仓库信息
svn_info=$(svn info "$SVN_URL")
# 提取根路径
root_path=$(echo "$svn_info" | grep '^Repository Root:' | awk '{print $3}')
# 输出根路径
echo "SVN 仓库根路径: $root_path"
# 检查 trunk 目录
trunk_url="$root_path/trunk"
if svn info $trunk_url &> /dev/null; then
echo "主干分支 (trunk) 存在于: $trunk_url"
else
echo "未找到主干分支 (trunk)"
fi
# 检查 branches 目录
branches_url="$root_path/branches"
if svn info $branches_url &> /dev/null; then
echo "分支目录 (branches) 存在于: $branches_url"
else
echo "未找到分支目录 (branches)"
fi
# 检查 tags 目录
tags_url="$root_path/tags"
if svn info $tags_url &> /dev/null; then
echo "标签目录 (tags) 存在于: $tags_url"
else
echo "未找到标签目录 (tags)"
fi
```
执行以下命令查看仓库的根路径及目录结构:
```bash
svn ls https://example.com/svn/repo/
```
在SVN转换Git仓库时,要通过参数将仓库布局提供给 `git-svn`,以便将分支和标签正确导出。
其他的布局方式如下:
- 无分支、无标签的主干模式:SVN仓库的根目录即为项目主干。
- 多项目模式:SVN仓库的一级目录作为项目名,每个项目有自己特定的仓库布局。
3. **建立 SVN 和 Git 之间的作者名称映射**
SVN使用服务端ID作为提交者,而Git允许客户端自定义提交者,含全名和邮箱。
- 在 `git-svn` 转换时,建议提供SVN到Git用户的映射文件,每行记录映射关系,示例如下:
```
# 格式:SVN用户名 = Git用户名 <邮箱>
loginname = Joe User <user@example.com>
```
- 执行以下命令获取SVN仓库全部提交的用户名列表:
```bash
svn log -q https://example.com/svn/repo/
```
### **初始化本地 Git 仓库**
创建一个本地工作区目录,进入到目录中:
执行 `git svn init` 命令将本地工作区初始化为一个Git仓库。
- 对于**无分支的SVN仓库**,使用以下初始化命令:
```bash
git svn init https://example.com/svn/repo
```
- 对于**标准布局的SVN仓库**(包含trunk、branches、tags目录),使用以下初始化命令:
```bash
git svn init -s https://example.com/svn/repo
```
- 对于**非标准布局的SVN仓库**(例如目录名大小写与标准布局有差异),使用以下初始化命令:
```bash
git svn init -T Trunk -b Branches -t Tags https://example.com/svn/repo
```
### **拉取远程 SVN 仓库同步**
执行 `git svn fetch` 命令与远程SVN仓库数据同步,将远程仓库获取到本地并转换为Git提交。如果有SVN/Git 作者映射文件,如文件 `authors.map`,需在命令行中提供。
- 同步**全部历史提交**:
```bash
git svn fetch -A /path/of/authors.map
```
- 同步**某个范围的提交**(例如从r0到r100):
```bash
git svn fetch -A /path/of/authors.map -r 0:100
```
### **推送到远程仓库**
在云效的服务端创建Git仓库,用于保存转换后的结果。
1. 创建仓库操作,请参见[新建第一个代码库](/uploads/shares/4/assets/笔记同步助手/attachments/新建第一个代码库-20260203112422-knnvpuy)。
2. 在服务端页面获取Git库地址。
**说明**
请不要在新库上创建任何分支、标签以及文件,确保其为空仓库,否则可能因为强制推送问题导致迁移失败。
示例Git仓库地址:
https://codeup.aliyun.com/$group/repo.git
使用以下命令添加远程源,避免与 `git-svn` 源重名:
```bash
git remote add target https://codeup.aliyun.com/$group/repo.git
```
迁移后,SVN仓库变身Git仓库,分支标签一键转换。迁移完成,SVN分支标签即转为Git跟踪分支和标签。推送时,SVN布局决定推送方式。
1. 对于**无分支**和**标签的SVN仓库**,仓库的主干分支映射为 `refs/remotes/git-svn`,使用以下命令将其推送到目标Git仓库的 `master` 分支(或 `main` 分支):
2. 对于**标准布局的SVN仓库**,其分支和标签混杂在一起。首先使用以下命令重命名标签,以便本地跟踪分支和标签有不同前缀,便于区分:
```bash
git push target \\
--tags \\
refs/remotes/origin/trunk:refs/heads/master \\
"refs/remotes/origin/*:refs/heads/*"
```
然后执行以下命令将本地仓库的分支和标签推送到目标Git仓库:
```bash
git for-each-ref --format="%(objectname) %(refname:lstrip=4)" \\
"refs/remotes/origin/tags/*" |
while read oid tag; do
git update-ref "refs/tags/$tag" "$oid" &&
git update-ref -d "refs/remotes/origin/tags/$tag"
done
```
[^13]: # 这 6 个超神的 SKills,在 GitHub 上杀疯了。
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260203155148-3i66z3f)
## 正文
公众号名称:逛逛GitHub
作者名称:逛逛
发布时间:2026-02-03 15:05
01
**视频制作:Remotion Skill**
**不知道大家有没有用过 Remotion 这个开源项目,现在也有 2.8 万的 Star 了。**
**之前我想做视频生成自动化的时候,了解过 Remotion。它其实是一个用 React 编程来制作视频的框架。**
**比如下面这种视频,都可以使用** ****Remotion 框架制作。****


**最近 AI Skill 大火,Remotion 团队就推出了 remotion skills。**
**这个给 AI Agent 使用的技能包,可以教会 AI 如何正确、准确地使用 Remotion 框架来制作视频。**
**比如下面这个视频,没有使用任何剪辑工具。就是使用** ****remotion skills + Claude Code 来生成的:****
下面就是使用 remotion skills 生成上面这个视频的演示:
如果有条件,可以去 X 上看看,现在很多网友开始使用 remotion skills 来制作各种各样花里胡哨的视频了。
这个开源的 skill 确实指的单独一篇文章,有空详细讲讲。
你可以通过下面命令安装这个 skill:
```
npx skills add remotion-dev/skills
```
**原理其实是将 Remotion 的官方文档、API 规范和最佳实践封装成 AI 可读取的 Context,让 AI 成为更懂 Remotion 的视频制作助手。**
```
开源地址:https://github.com/remotion-dev/skills
```
02
**YouTube 视频剪辑 Skill**
Youtube-clipper-skill 是 AI 大佬开源的一个 YouTube 视频剪辑 Skill。
丢个 YouTube 的链接,它能自动完成环境检查、下载、语义分析、剪辑以及生成双语字幕文件,可以从长视频中提取精华片段。

它不是机械地按时间切割视频,而是利用 Claude 的 AI 能力对视频字幕进行语义分析,自动生成有用的视频切片。
这个开源项目项目集成了 yt-dlp 和 FFmpeg 底层工具,能够实现高质量的视频下载与处理。
它具备强大的字幕处理能力,支持将字幕批量翻译为中英双语格式,并能将双语字幕录入视频画面中。
翻译功能进行了优化,通过批量处理能显著减少 API 调用次数并提升翻译一致性。
而且它能够自动生成适用于小红书、抖音或微信等平台的视频摘要和素材。


```
开源地址:https://github.com/op7418/Youtube-clipper-skill
```
03
**skill-from-masters**
这个挺有意思的,它能帮你创建 Skill。
在创建新 Skill 之前,会先搜索,寻找目标领域的顶级专家的思维模型和最佳实践,确保生成的 Skill 具备专业深度。

这个开源项目采用三层搜索架构:
首先查询本地专家数据库,其次进行网络搜索以补充更多专家观点,最后深入查找一手资料并交叉验证。
它不仅寻找黄金范例作为输出标准,还会识别该领域的反面模式以避免常见错误,从而生成高质量、专业度极高的 Skill 指令。
除了从专家处学习,该仓库还包含一个 skill-from-github 功能。
你可以指定优秀的 GitHub 开源项目,让 AI 深入阅源码和文档,提取其中的算法逻辑或设计模式,并将其转化为一个独立的 Skill,还挺有用的。
```
开源地址:https://github.com/GBSOSS/skill-from-masters
```
04
**NotebookLM Skill**
这个开源 Skill 能让 Claude Code 直接与 Google NotebookLM 进行交互。通过连接 NotebookLM ,让 Claude 能够基于你上传的知识库回答。
这个项目会在本地运行一个独立的 Python 环境,利用 Patchright(基于 Playwright)技术实现浏览器自动化操作。
它模拟用户登录 Google 账号并操作 NotebookLM 界面,实现了持久化认证和库管理。

说白了,装了这个 Skill 不用再浏览器和命令行之前反复的复制粘贴了。
你可以直接在命令行里面通过自然语言查询自己的知识库,Claude 会自动从 NotebookLM 获取经过综合处理的答案。
```
开源地址:https://github.com/PleasePrompto/notebooklm-skill
```
05
**Markdown 文章一键发布到 X**
这个 Skill 可以把本地 Markdown 文章一键发布到 X 上。
X 平台自带编辑器对 Markdown 支持不好,经常排版丢失,手动插入图片很繁琐。
用这个 Skill 通过 Claude Code 就能完成从文稿解析到草稿生成的全过程。

工具支持将 Markdown 的丰富格式完美转换为 X Articles 的 HTML 格式。
为了确保文章排版的精准性,这个工具引入了 Block-Index 定位技术。
在解析 Markdown 时,它会计算每张图片在文章结构中的精确位置索引,通过浏览器自动化脚本将图片精准插入到对应的段落之间,彻底解决了传统文本匹配方式容易导致的图片错位问题。
```
开源地址:https://github.com/wshuyi/x-article-publisher-skill
```
06
**Agent Skills 公共仓库**
这是 Anthropic 官方发布的 Agent Skills 公共仓库,定义了 Claude 的 Skill 标准,重点是里面有大量现成的 Skill。
这些 Skill 设计灵活,既可以在 Claude Code 中用,也可以集成到 Claude.ai 或通过 API 调用。
我看了一下,有很多 Skill 还是非常实用的。
比如文档处理,强大的 PDF、Word、Excel、PPT 处理能力,都有对应的 Skill。
mcp-builder 可以辅助你创建高质量的 MCP Server,artifacts-builder 能使用 React、Tailwind CSS 和 shadcn/ui 组件库构建复杂的 HTML 交互式界面。
还有很多很多,感兴趣去瞧瞧吧。
```
开源地址:https://github.com/anthropics/skills
```
07
**点击下方卡片,关注逛逛 GitHub**
这个公众号历史发布过很多有趣的开源项目,如果你懒得翻文章一个个找,你直接关注微信公众号:逛逛 GitHub ,后台对话聊天就行了:
[^14]: # 系统接口突发慢速的系统化排查思路与实战指南
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260204123724-jhn88fv)
## 正文
作者:托尼学长1
发布日期:未知
## 前言
在面试或实际运维中,常会被问及“系统中接口突然变慢该如何排查”。在给出答案前,先明确是“全部接口”都变慢,还是仅有“某个特定接口”出现性能下降,这一点至关重要,因为两者的排查路径截然不同。
## 一、全部接口普遍变慢的排查思路
### 1\. 划分风险边界:外部还是内部
首先判断性能下降是由外部流量异常还是内部资源瓶颈引起。
- 外部风险:用户请求量突增。通过监控平台(如 Prometheus)观察 QPS(Queries Per Second)或 TPS(Transactions Per Second)曲线,若出现尖峰则可能是流量冲击导致的压垮。
- 内部风险:请求量未异常,需进一步分析系统内部组件。
### 2\. 内部问题深度划分
在确认是内部因素后,继续划分为数据库/中间件层与业务系统自身层。
- **数据库层**
1. 检查慢查询日志(MySQL、PostgreSQL 等)是否出现新产生的大量慢查询。
2. 使用监控指标(QPS、TPS、连接数、CPU、磁盘 I/O)判断数据库负载是否异常升高。
- **下游服务层**
通过 Grafana 查看下游依赖服务的响应时间(RT)曲线,判断是否出现整体延迟。
- **业务系统自身**
1. 监控内存使用情况,排查内存泄漏或 OOM。
2. 获取线程快照,使用阿里开源的线上诊断工具 *Arthas* 分析锁竞争、线程阻塞等。
3. 检查网络 I/O 与磁盘 I/O 是否达到瓶颈——常见原因包括单次返回数据过大、日志打印过多等。
4. 若近期上线了高 QPS 的业务入口,观察该入口的调用链是否因为业务逻辑过于复杂而拖慢整体。
### 3\. 通过监控定位根因
利用 Prometheus + Grafana 监控平台,查看不同接口的响应时间(Latency)曲线,识别最先出现异常的接口,即为问题的“元凶”。随后聚焦该接口所在的服务或资源进行细致排查。
## 二、单个接口变慢的排查思路
相对整体慢,单接口问题更容易定位。推荐使用 APM 工具(如 SkyWalking、CloudStart)结合链路追踪来确认瓶颈所在。
- 在调用链上标记每一步的耗时,快速判断是数据库查询、下游服务调用还是业务逻辑处理导致的延迟。
- 针对发现的慢环节,依据前文的数据库或系统排查步骤进行深入分析。
## 三、总结
排查系统接口慢的核心原则是**分层、分阶段、逐步缩小范围**:
1. 先确认是全局还是局部慢。
2. 再判断是外部流量异常还是内部资源瓶颈。
3. 随后在内部层面逐层检查数据库、下游服务、业务系统自身。
4. 借助监控、日志、链路追踪和诊断工具,定位根因并进行针对性优化。
切记不要盲目“东一锤子西一棒子”地排查,否则可能错失关键窗口,等到问题根源被定位时,已经“黄花菜都凉了”。[^15]: # 开源-一款专治“AI审美疲劳”的 UI-UX 设计技能包,支持跨平台、多框架一键生成专业级界面
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260206091359-9tiegzd)
## 正文
公众号名称:刘哥聊技术
作者名称:刘哥聊技术
发布时间:2026-01-24 12:39
在日常开发中,你是不是也遇到过这样的场景:
- • 你让 AI 帮你写一个 SaaS 产品的落地页,结果它交回来的界面虽然“能用”,但配色像调色盘打翻了,字体搭配毫无章法,交互逻辑还缺胳膊少腿。
- • 你反复调整提示词,来回沟通三四轮,发现还不如自己手写快。
- • 更头疼的是,不同项目之间风格不统一,今天是极简风,明天又冒出个“AI 紫渐变”,团队协作时根本没法对齐设计语言。
这其实不是 AI 能力不行,而是缺乏一套**结构化、可复用、行业适配的设计智-能**。普通提示词只能靠“猜”,而真正专业的 UI/UX 需要的是**系统化的决策引擎**,知道什么行业该用什么布局、什么品牌调性匹配什么色彩、哪些动效提升转化、哪些反模式必须避开。
那有没有一款工具,能让 AI 不再“自由发挥”,而是像资深设计师一样,**按照行业专业实践,自动生成完整、一致、可落地的设计方案**?
答案是:有。而且它已经开源。
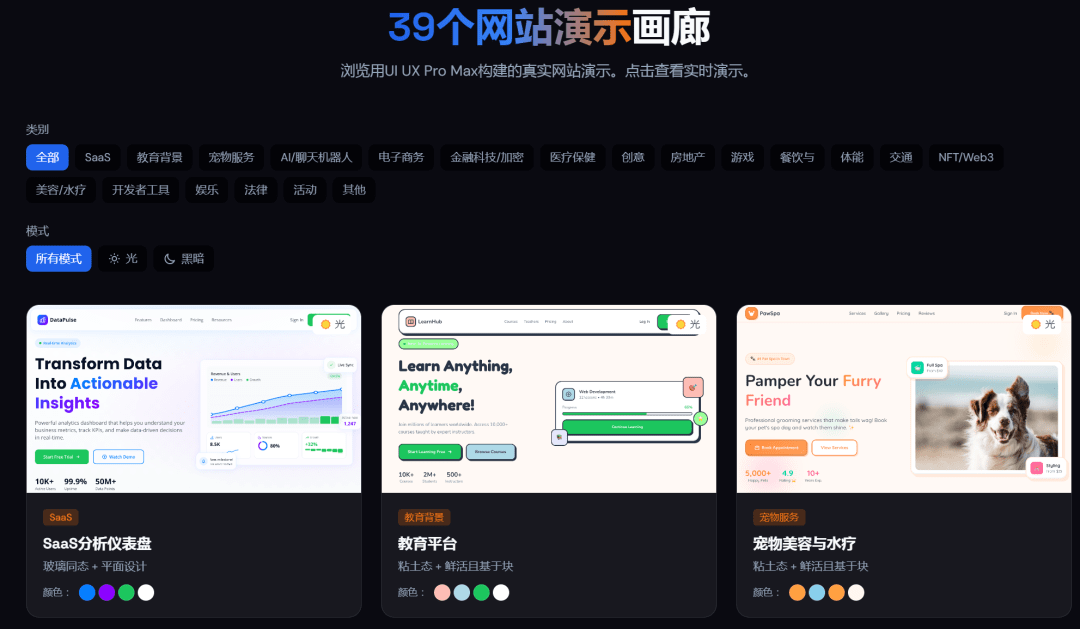
### 介绍
这款工具名叫 **UI/UX Pro Max Skill**,本质上是一个为 AI 助手(如 Claude、Cursor、Copilot、Trae 等)量身打造的“设计智-能插件”。它不是一个独立软件,而是一套**可嵌入任何 AI 编程环境的技能包(Skill)** ,专门处理“AI 生成界面太业余”的问题。
它的核心不是写代码,而是**先生成一套完整的设计系统**,包括页面结构、色彩体系、字体组合、交互规范、无障碍检查清单,甚至明确告诉你“哪些东西千万别用”。
换句话说,它把 UI/UX 设计师的经验,编码成了 AI 能理解的推理规则。

### 前端
前端输出默认基于 **HTML + Tailwind CSS**,这是目前轻量、易维护的组合。但如果你用的是 React、Vue、Svelte、Flutter 或 SwiftUI,也没问题,它内置了对 **13 个主流技术栈**的支持,只需在提示中提一句“用 Next.js 实现”或“生成 Flutter 代码”,它就会自动适配对应框架的专业实践。
更重要的是,它生成的代码**不是“能跑就行”** ,而是严格遵循:
- • 可访问性标准(WCAG AA)
- • 响应式断点(375px / 768px / 1024px / 1440px)
- • 交互反馈(hover、focus、cursor-pointer)
- • 动效节奏(200–300ms 平滑过渡)
- • 无 emoji 图标(强制使用 Heroicons/Lucide SVG)
这些细节,恰恰是普通 AI 容易忽略的“专业感”来源。
### 后端
严格来说,它没有传统意义上的“后端”。整个推理过程由本地 Python 脚本驱动,通过多路并行搜索(产品类型、风格、配色、排版、图表等),结合 **100 条行业特定规则**,输出结构化设计建议。
比如你输入“为美容水疗中心做官网”,它会自动匹配:
- • **页面模式**:Hero-Centric + Social Proof(突出主视觉+客户证言)
- • **色彩方案**:柔粉 #E8B4B8 + 鼠尾草绿 #A8D5BA + 金色 CTA
- • **字体组合**:Cormorant Garamond(优雅衬线) + Montserrat(现代无衬线)
- • **反模式提醒**:禁止使用霓虹色、硬动画、暗黑模式、“AI 紫渐变”
所有这些决策,都来自对真实商业案例的归纳,而非随机生成。
### 特点
- • **67 种 UI 风格**:从玻璃拟态、粘土风到新拟物、极简主义,覆盖主流审美趋势
- • **96 套行业配色**:SaaS、电商、金融、医-疗、美妆等专-属调色板
- • **56 组字体搭配**:全部来自 Google Fonts,可一键导入
- • **25 类仪表盘图表**:BI 场景也能智-能推荐
- • **98 条 UX 指南**:包含无障碍、动效、响应式等实践
- • **持久化设计系统**:支持生成 `MASTER.md` 全局规范 + 页面级覆盖文件,实现跨页面风格统一
实用的一点是:**它能自动规避“AI 味”设计**。比如明确禁止在银行类应用中使用紫色渐变,在健康类网站中禁用刺眼动画,这些正是人类设计师多年踩坑总结出的经验。

### 技术架构
整体采用 **“推理引擎 + 规则库 + 输出模板”** 的三层架构:
1. 1\. **输入层**:接收自然语言需求(如 “Build a landing page for my beauty spa”)
2. 2\. **推理层**:并行查询 5 个维度(品类、风格、色彩、排版、图表),通过 BM25 排序和 JSON 条件过滤,匹配最优组合
3. 3\. **输出层**:生成结构化设计系统(ASCII / Markdown 格式),并可直接驱动代码生成
整个过程无需联网(除非主动下载字体或图标),所有规则本地运行,保障隐私与速度。
### 部署方式
#### 前端
无需部署。生成的代码可直接集成到你的项目中。支持:
- • Web:HTML + Tailwind、React、Next.js、Vue、Nuxt、Svelte、Astro
- • 移动端:React Native、Flutter
- • 原生:SwiftUI(iOS)、Jetpack Compose(Android)
#### 后端
只需安装 CLI 工具或 Python 3.x:
```
npm install -g uipro-cli
uipro init --ai claude # 或 cursor/copilot/trae 等
```
然后在项目目录中调用:
```
/ui-ux-pro-max Build a landing page for my SaaS product
```
或者直接运行脚本生成设计系统:
```
python3 .claude/skills/ui-ux-pro-max/scripts/search.py "fintech banking" --design-system -f markdown
```
整个过程轻量、无依赖、适合嵌入现有开发流。

### 开源协议
项目采用 **MIT 开源协议**,这意味着:
- • 允许商用
- • 允许修改、分发、私有化部署
- • 无需公开衍生作品源码
- • ⚠️ 唯一要求:保留原始版权声明
对个人开发者、创业团队、企业项目都非常友好,无法律风险。
### 即刻体验一波
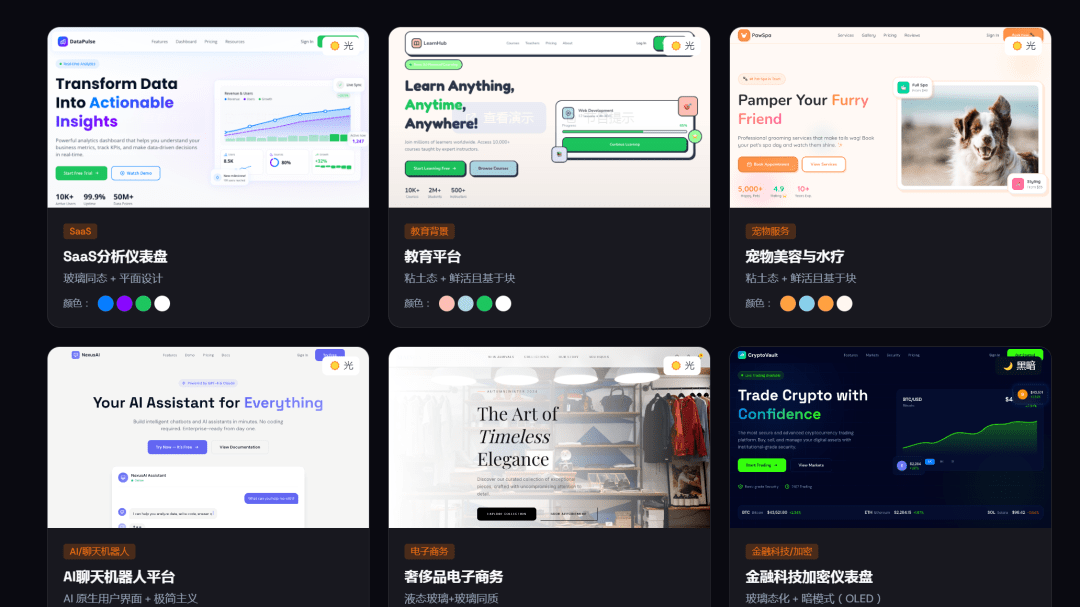
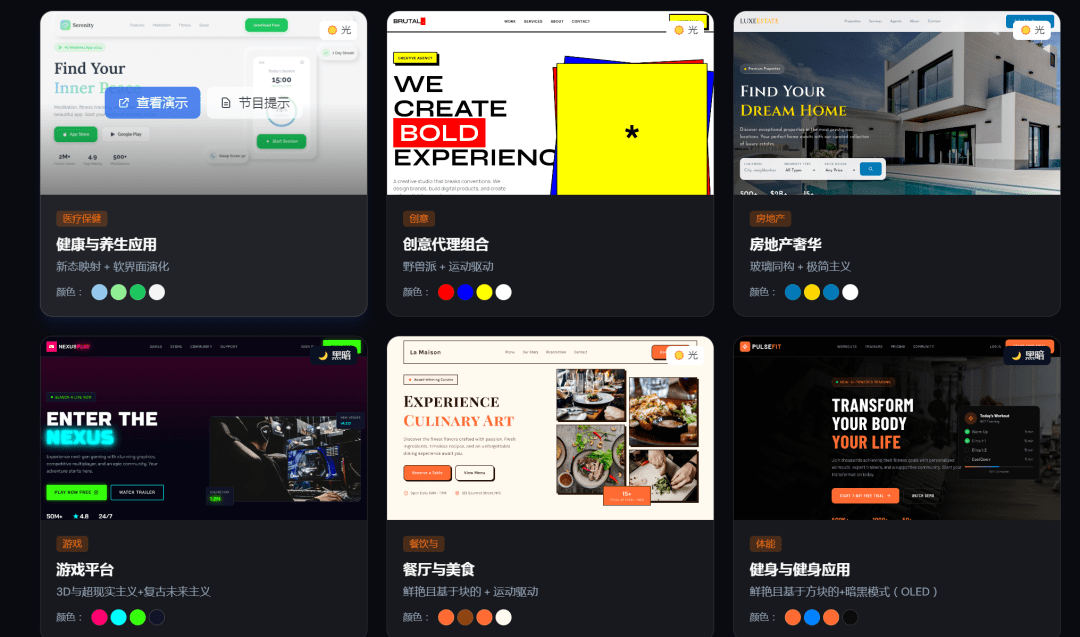
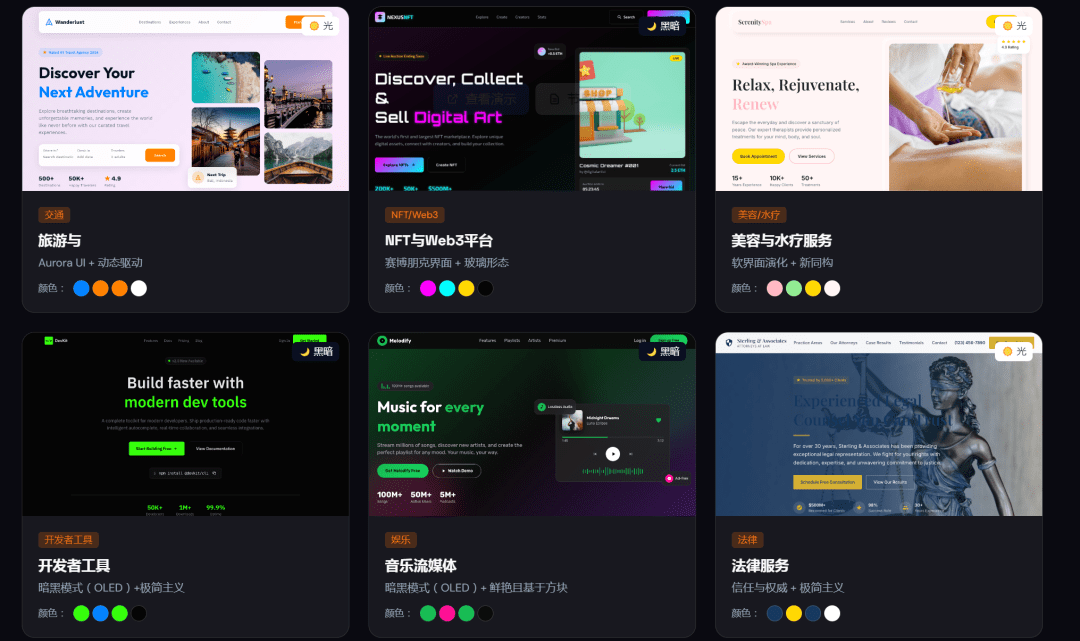
假设你要为一家高端水疗品牌“Serenity Spa”做官网,只需输入:
> Build a landing page for my beauty spa
>
AI 会立刻返回如下设计系统(简化版):
```
PATTERN: Hero-Centric + Social Proof
STYLE: Soft UI Evolution
COLORS: Primary #E8B4B8, Secondary #A8D5BA, CTA #D4AF37
TYPOGRAPHY: Cormorant Garamond / Montserrat
AVOID: Neon colors, harsh animations, dark mode, AI purple gradients
CHECKLIST: [✓] SVG icons [✓] Hover transitions [✓] WCAG contrast ≥4.5:1
```
接着,它会基于这套规范,生成完整的 HTML + Tailwind 代码,包含 Hero 区、服务介绍、客户评价、预约表单、联系方式五大模块,且每一处交互都经过 UX 验证。
你甚至可以保存为 `design-system/MASTER.md`,后续做“会员中心”或“博客页”时,自动继承全局规范,仅覆盖局部差异。
### 业务场景
- • **独立开发者**:快速产出高质感 MVP 界面,告别“AI 味”原型
- • **小型团队**:统一设计语言,避免前端与设计师反复对稿
- • **外包接单**:用专业级输出提升客户信任度,报价更有底气
- • **内部工具**:为后台系统注入现代 UI,提升使用体验
尤其适合那些**不想花大价钱请设计师,又不愿将就“能用就行”界面**的务实派开发者。
### 结语
UI/UX Pro Max Skill 的出现,不是要取代设计师,而是把设计领域的“常识”和“经验”封装成 AI 能执行的规则,让每个开发者都能站在专业设计的肩膀上。
它处理的不是“能不能做”,而是“做得够不够专业”。在效率与质量之间,找到了一个恰到好处的平衡点。
如果你也厌倦了和 AI 反复拉扯界面细节,不妨试试这个开源技能包。或许下一次,你只需要一句话,就能拿到一个可以直接交付的设计方案。
后台私:uiskill 获取源码和文档。
往期项目
[一款数字孪生三维可视化开发工具,融合3D场景、实时数据、UI看板,数百个API开放,支持二次开发](/uploads/shares/4/assets/笔记同步助手/attachments/一款数字孪生三维可视化开发工具,融合3D场景、实时数据、UI看板,数百个API开放,支持二次开发-20260206091359-s6eggkj)
[开源|一款轻量级自动化运维平台,支持 Web 终端、批量执行、CI/CD 与日志追踪](/uploads/shares/4/assets/笔记同步助手/attachments/开源-一款轻量级自动化运维平台,支持Web终端、批量执行、CI-CD与日志追踪-20260206091359-foixdv0)
[开源|一款基于 Node.js 和Amis 的轻量级低代码平台,支持多租户、工作流与一键部署](/uploads/shares/4/assets/笔记同步助手/attachments/开源-一款基于Node.js和Amis的轻量级低代码平台,支持多租户、工作流与一键部-20260206091400-rcgpxr1.js和amis的轻量级低代码平台,支持多租户、工作流与一键部署)
[一款GEO AI优化系统,支持关键词蒸馏、自动创作、多平台投喂与收录验证,让品牌在DeepSeek、豆包等大模型中被优先推荐](/uploads/shares/4/assets/笔记同步助手/attachments/一款GEOAI优化系统,支持关键词蒸馏、自动创作、多平台投喂与收录验证,让品牌在DeepSeek、豆包等大模型中被优先推荐-20260206091400-38r7ohc)
[开源|一款零成本、免公网IP的内网穿透工具,一条命令直连两台主机,支持远程桌面、SSH、Git 等端口访问](/uploads/shares/4/assets/笔记同步助手/attachments/开源-一款零成本、免公网IP的内网穿透工具,一条命令直连两台主机,支持远程桌面、SSH、Git等端口访问-20260206091400-lsaq98t)
[开源|一款全场景电子签章系统,支持多租户、私有化部署与合规签署](/uploads/shares/4/assets/笔记同步助手/attachments/开源-一款全场景电子签章系统,支持多租户、私有化部署与合规签署-20260206091400-aqefeba)
[开源|一款零成本、免公网IP的内网穿透工具,一条命令直连两台主机,支持远程桌面、SSH、Git 等端口访问](/uploads/shares/4/assets/笔记同步助手/attachments/开源-一款零成本、免公网IP的内网穿透工具,一条命令直连两台主机,支持远程桌面、SSH、Git等端口访问-20260206091400-0jic7fm)
了解更多
#开源、#AI 设计、#UI/UX、#前端开发、#Tailwind、#设计系统、#Claude、#技能包、#MIT 协议、#跨平台
---
原创 刘哥聊技术 刘哥聊技术
继续滑动看下一个

刘哥聊技术
向上滑动看下一个[^16]: # 重磅!Antdv Next 正式发布!对标 Antd V6 的 Vue3 UI 组件库!
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260207105532-9ctazld)
## 正文
公众号名称:前端开发爱好者
作者名称:认真努力的小四子
发布时间:2026-02-07 08:34
如果你是 **Vue** 开发者,大概率绕不开一个名字——**Ant Design Vue**。

在很长一段时间里,它几乎是 **Vue**`企业级后台`项目的`“标准答案”`:`成熟、稳定、组件齐全`,支撑了无数真实业务系统。
但随着时间推移,越来越多 **Vue** 开发者也开始意识到一个现实问题:
> **Ant Design 在快速演进,而 Ant Design Vue,正在变得越来越“吃力”。**
>
## 🤔 当 Ant Design 走到 v6,Vue 生态却有点“卡住了”
**Ant Design v6** 并不是一次普通升级。
它带来的,是一次**设计体系级别的变化**:
- 全新的 **Design Token System**
- 更系统化的`颜色`、`字号`、`间距抽象`
- 更现代的`视觉`与`交互规范`
- 面向未来的`样式`与`主题`能力
但对于 **Vue** 生态来说,问题也随之变得非常现实:
- `Ant Design` 的核心实现始终 **React 优先**
- `Ant Design Vue` 经过多年演进,背负了大量历史设计
- `API` 中仍然保留不少 `React` 风格的使用方式
- 要在现有架构上完整对齐 `v6`,成本极高
于是,一个很多人心里都有、但一直没人真正去做的问题出现了:
> **有没有可能,为 Vue 3 重新实现一次 Ant Design?**
>
## ✨ Antdv Next:不是升级,而是重建
**Antdv Next**,正是在这样的背景下诞生的。

需要特别强调的是:
**Antdv Next 并不是 Ant Design Vue 的 Next 版本。**
它不是渐进升级,也不是兼容演化,而是一个**从 0 开始的全新项目**,目标非常明确:
- 🎯 **设计体系直接对标 Ant Design v6**
- 🎯 **API 从一开始就为 Vue 而设计**
- 🎯 **工程架构面向未来,而不是历史包袱**
随着 **Antdv Next v1.0 的正式发布**,**Vue** 生态终于迎来了一个明确对标 **Ant Design v6** 的新选择。
## 🧩 核心设计理念:真正的 Vue,而不是“React 翻译版”

### API 设计:完全 Vue 化
**Antdv Next** 在 `API` 设计上,做了一个非常坚定的取舍:
👉 **不追求 React API 的一一对应,而是遵循 Vue 的使用直觉。**
具体体现为:
- **插槽(Slots)** 是核心能力,而不是 `children` 兼容
- `模板`表达自然、清晰
- 减少`“为了兼容而复杂”`的设计
用一句话形容就是:**你不会感觉自己在“用 Vue 写 React 组件”。**
### 设计体系:对齐 Ant Design v6 的 Design Token
**Antdv Next** 从项目伊始,就直接对齐 `Ant Design v6` 的设计体系:
- `颜色`、`字体`、`间距`、`圆角`等全部基于 **Token**
- **设计与实现解耦**
- **主题定制更灵活、更系统**
这意味着它不是“看起来像 **Ant Design**”, 而是**在设计层面就属于 Ant Design v6 体系的一部分**。
### 样式方案:CSS-in-JS + 更少运行时负担
在样式架构上,**Antdv Next** 选择了更偏向现代前端的方案:
- **样式生成可控**
- **更利于主题切换**
- **对** **`SSR / Nuxt`** **更友好**
- **降低运行时开销**
这类设计在中大型项目中,长期维护价值非常高。
## 🛠 技术栈与工程定位
**Antdv Next** 的整体技术选型非常清晰:
- **Vue 3**
- **TypeScript**
- 面向 **SSR / Nuxt**
- 企业级工程结构
- 可持续维护的组件体系
它并不是一个“玩票性质”的实验,而是一个**有明确工程目标的长期项目**。
## 📦 快速上手
安装非常简单:
```
npm install antdv-next
# or
pnpm add antdv-next
# or
yarn add antdv-next
```
随后即可在 **Vue 3** 项目中按需引入组件。
📘 **官方文档**:[https://antdv-next.com/index-cn](/uploads/shares/4/assets/笔记同步助手/attachments/https---antdv-next-20260207105532-b5iefye.com-index-cn)
📦 **GitHub 仓库**:[https://github.com/antdv-next/antdv-next](/uploads/shares/4/assets/笔记同步助手/attachments/https---github-20260207105533-zpnnnf6.com-antdv-next-antdv-next)
## 🔍 Antdv Next vs Ant Design Vue
很多人会自然地把两者放在一起**对比**,其实它们的**定位**并不相同:
|维度|Antdv Next|Ant Design Vue|
| ----------| ------------| ----------------|
|设计体系|**Ant Design v6**|**v5**及之前|
|实现方式|从 **0** 重构|长期演进|
|API 风格|完全 **Vue** 化|部分 **React** 遗留|
|历史包袱|几乎没有|较重|
|未来扩展|更灵活|受历史限制|
与其说是`“替代关系”`,不如说是**不同阶段的选择**:
- **Ant Design Vue**:`成熟、稳定、经过时间验证`
- **Antdv Next**:`面向未来、设计体系更新、更现代`
## 🎯 写在最后
**Antdv Next** 的出现,其实是一件很 **“难得”** 的事。
它没有选择最安全的路径,而是做了一次更艰难的决定:
**不是为了兼容过去,而是为 Vue 生态对齐 Ant Design 的未来。**
如果你:
- 正在使用 **Vue 3**
- 关注 **Ant Design v6** 的设计体系
- 希望一个**更现代**、**更干净**的组件库实现
那么 **Antdv Next 非常值得关注,甚至参与共建**。
🚀 **Vue** 生态,终于迎来了一个真正对标 **Ant Design v6** 的新答案。
- 📘 **官方文档**:[https://antdv-next.com/index-cn](/uploads/shares/4/assets/笔记同步助手/attachments/https---antdv-next-20260207105532-b5iefye.com-index-cn)
- 📦 **GitHub 仓库**:[https://github.com/antdv-next/antdv-next](/uploads/shares/4/assets/笔记同步助手/attachments/https---github-20260207105534-3p3e21g.com-antdv-next-antdv-next)
---

Original 认真努力的小四子 前端开发爱好者
继续滑动看下一个[^17]: # Vue 开发必备!9 个高效插件,从基础到工具全栈覆盖(Vue2-Vue3 通用)
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260207212539-8o58tml)
## 正文
公众号名称:Ai懒人码农
作者名称:JackChen007
发布时间:2026-02-05 08:08
Vue 之所以能成为前端开发者的首选框架之一,除了简洁灵活的语法设计,其强大的插件生态更是核心优势!这些插件就像 “开发快捷键”,能帮我们跳过重复的基础编码,直接攻克路由管理、状态共享、UI 搭建、接口请求等高频需求。无论是 Vue2 项目维护,还是 Vue3(含组合式 API)新项目开发,都能找到适配的成熟插件。
本文精选 9 个日常开发高频使用的 Vue 插件,按基础核心、UI 组件、网络请求、工具辅助四大类分类,每款都附上核心功能、安装命令和极简使用示例,新手也能快速上手融入项目,让开发效率直线提升!
说明:文中默认以 Vue3(基于 Vite)项目为例,Vue2 项目的安装命令和使用差异会单独标注,确保不同技术栈都能无缝适配。
## 一、基础核心插件:Vue 项目的 “骨架基石”
这类插件是绝大多数 Vue 项目的必备基础,解决路由跳转、跨组件数据共享等核心问题,是项目启动的前提条件,缺一不可。
### 1\. vue-router:Vue 官方路由管理器
**核心作用**:Vue 官方标配的路由插件,专为单页应用(SPA)设计,支持页面跳转、路由守卫、动态路由、嵌套路由等核心功能,是实现页面切换的核心工具。**适配版本**:Vue2 适配 vue-router@3,Vue3 适配 vue-router@4**安装命令**:
```
# Vue3 + Vite
npm install vue-router@4 --save
# Vue2
npm install vue-router@3 --save
```
**极简使用**:(1)新建路由配置文件`src/router/index.js`,定义路由规则:
```
import { createRouter, createWebHistory } from'vue-router'
// 引入需要跳转的页面组件
import Home from'@/views/Home.vue'
import About from'@/views/About.vue'
const routes = [
{ path: '/', name: 'Home', component: Home },
{ path: '/about', name: 'About', component: About }
]
// Vue3推荐使用createWebHistory模式(无#号URL)
const router = createRouter({
history: createWebHistory(),
routes
})
exportdefault router
```
(2)在`src/main.js`全局注册路由:
```
import { createApp } from 'vue'
import App from './App.vue'
import router from './router'
// 全局挂载路由插件
createApp(App).use(router).mount('#app')
```
(3)页面中使用路由跳转和渲染:
```
首页
关于我们
```
### 2\. Pinia:Vue3 官方推荐状态管理库
**核心作用**:Vue3 官方推出的状态管理工具,替代传统 Vuex,专门解决跨组件、跨页面的数据共享问题。相比 Vuex 更轻量、语法更简洁,支持组合式 API,无需复杂的 mutations/actions,可直接修改状态,开发体验更流畅。**适配版本**:主打 Vue3,Vue2 需额外配置适配**安装命令**:
```
npm install pinia --save
```
**极简使用**:(1)在`src/main.js`全局注册 Pinia:
```
import { createApp } from 'vue'
import App from './App.vue'
import { createPinia } from 'pinia'
const pinia = createPinia()
createApp(App).use(pinia).mount('#app')
```
(2)新建状态仓库`src/stores/counter.js`:
```
import { defineStore } from'pinia'
// 定义并导出仓库,唯一标识为"counter"
exportconst useCounterStore = defineStore('counter', {
// 状态数据(返回对象的函数)
state: () => ({ count: 0 }),
// 修改状态的方法(支持同步/异步)
actions: {
increment() {
this.count++
}
},
// 计算属性(基于state派生的数据)
getters: {
doubleCount: (state) => state.count * 2
}
})
```
(3)在组件中使用状态:
```
// 引入仓库并实例化
import { useCounterStore } from '@/stores/counter'
const counter = useCounterStore()
```
### 3\. Vuex:经典状态管理(Vue2 首选)
**核心作用**:Vue2 官方状态管理库,规范了状态的修改流程,支持模块化拆分,适合中大型 Vue2 项目的复杂状态管理。Vue3 虽兼容(需用 vuex@4),但更推荐使用 Pinia。**适配版本**:Vue2 用 vuex@3,Vue3 用 vuex@4(兼容模式)**安装命令**:
```
# Vue2
npm install vuex@3 --save
```
**极简使用**:全局注册后,通过`this.$store.state`获取状态,`this.$store.commit`提交 mutation 修改状态,支持按业务模块拆分仓库(如用户模块、商品模块),适合复杂项目的状态分层管理。
## 二、UI 组件库:快速搭页,告别重复写样式
UI 组件库是前端开发的 “效率神器”,封装了按钮、表单、弹窗、表格等高频 UI 组件,支持按需引入,无需手动编写 CSS/HTML,直接调用即可完成页面搭建,以下 3 款覆盖通用 PC 端、移动端、高颜值轻量三大场景。
### 4\. Element Plus:Vue3 通用 PC 端 UI 库
**核心作用**:饿了么团队开发的 Vue3 PC 端 UI 组件库,国内最主流的 Vue3 UI 解决方案。组件丰富(近 100 个)、文档详细、兼容性强,支持完整引入和按需引入,是中后台管理系统、PC 端官网的首选。**适配版本**:Vue3 专属(Vue2 对应 Element UI)**安装命令**:
```
# 完整安装(新手友好)
npm install element-plus --save
# 按需引入(推荐生产环境,减小打包体积)
npm install element-plus unplugin-vue-components --save
```
**极简使用(完整引入)** :
```
// src/main.js
import { createApp } from 'vue'
import App from './App.vue'
import ElementPlus from 'element-plus'
import 'element-plus/dist/index.css' // 引入全局样式
createApp(App).use(ElementPlus).mount('#app')
```
组件中直接使用,无需单独引入:
```
import { ref } from 'vue'
const input = ref('')
```
### 5\. Vant 4:Vue3 移动端 UI 库
**核心作用**:有赞团队打造的移动端 UI 库,专为手机端优化,组件轻量、适配各种屏幕尺寸,支持按需引入、主题定制,是 Vue 移动端项目的首选。适用于电商 APP、资讯类应用、小程序等场景。**适配版本**:Vue3 用 Vant4,Vue2 用 Vant2**安装命令**:
```
npm install vant --save
# 按需引入依赖插件
npm install unplugin-vue-components unplugin-auto-import --save-dev
```
**极简使用**:配置 Vite 后支持按需引入,组件直接使用:
### 6\. Naive UI:Vue3 高颜值轻量 UI 库
**核心作用**:一款原生 Vue3 UI 库,设计风格现代化、颜值高,相比 Element Plus 更轻量,支持暗黑模式、按需引入,无需额外配置样式,适合追求 UI 质感的 PC 端项目。**适配版本**:仅支持 Vue3**安装命令**:
```
npm install naive-ui --save
```
**极简使用**:组件需手动按需引入,按需加载更灵活:
```
// 手动引入需要的组件
import { NButton } from 'naive-ui'
```
## 三、网络请求插件:优雅处理接口,少写冗余代码
项目开发中频繁遇到的接口请求、请求拦截、响应错误处理等需求,无需重复封装原生 fetch/axios,以下插件专为 Vue 适配,让请求处理更简洁、更优雅。
### 7\. vue-axios:Vue 适配的 Axios 插件
**核心作用**:将 Axios 封装为 Vue 插件,支持全局注册,可通过`this.$axios`或`proxy.$axios`全局调用。结合 Axios 的拦截器,轻松实现请求头添加 Token、响应错误统一处理、加载状态显示等功能。**适配版本**:Vue2/Vue3 通用**安装命令**:
```
# 先安装axios,再安装vue-axios
npm install axios vue-axios --save
```
**极简使用**:(1)全局注册并封装(`src/main.js`):
```
import { createApp } from'vue'
import App from'./App.vue'
import axios from'axios'
import VueAxios from'vue-axios'
const app = createApp(App)
app.use(VueAxios, axios)
// 配置请求基准地址
axios.defaults.baseURL = 'https://api.example.com'
// 请求拦截器:添加Token
axios.interceptors.request.use(config => {
config.headers.token = localStorage.getItem('token') || ''
return config
})
// 响应拦截器:统一处理错误
axios.interceptors.response.use(
res => res.data, // 直接返回响应数据
err => {
console.error('请求失败:', err.message)
returnPromise.reject(err)
}
)
app.mount('#app')
```
(2)组件中发起请求:
```
import { getCurrentInstance } from 'vue'
const { proxy } = getCurrentInstance()
// 发起GET请求
const getList = async () => {
const res = await proxy.$axios.get('/api/list')
console.log('请求结果:', res)
}
// 发起POST请求
proxy.$axios.post('/api/add', { name: 'Vue插件' })
```
### 8\. VueUse:Vue 官方工具集(全能型选手)
**核心作用**:不是单一插件,而是 Vue 官方维护的工具函数集合,封装了近 200 个高频开发需求,包括网络请求、本地存储、防抖节流、DOM 操作、时间处理等。支持组合式 API,按需引入,体积极小,功能覆盖全面。**适配版本**:Vue2/Vue3 通用(Vue2 需额外安装`@vue/composition-api`)**安装命令**:
plaintext
```
npm install @vueuse/core --save
```
**极简使用(网络请求 + 本地存储示例)** :
```
// 按需引入需要的工具函数
import { useFetch } from '@vueuse/core'
import { useLocalStorage } from '@vueuse/core'
// 网络请求:自动处理加载状态和错误
const { data, isLoading, error } = useFetch('https://api.example.com/api/list').get()
// 本地存储:自动序列化/反序列化,响应式更新
const userInfo = useLocalStorage('userInfo', { name: 'Vue', age: 3 })
userInfo.value.age = 4 // 直接修改,localStorage自动同步更新
```
## 四、工具辅助插件:搞定高频小需求,提升开发体验
这类插件专注解决开发中的 “小痛点”,比如本地存储序列化、数据持久化等高频需求,让代码更简洁,开发更省心。
### 9\. vue-ls:Vue 适配的本地存储插件
**核心作用**:专门为 Vue 封装的 localStorage/sessionStorage 工具,解决原生本地存储需手动调用`JSON.stringify`/`JSON.parse`的问题,支持设置过期时间、命名空间,全局注册后可通过`this.$ls`调用,完美适配 Vue 的响应式特性。**适配版本**:Vue2/Vue3 通用**安装命令**:
plaintext
```
npm install vue-ls --save
```
**极简使用**:(1)全局注册并配置(`src/main.js`):
```
import { createApp } from'vue'
import App from'./App.vue'
import Storage from'vue-ls'
// 配置项:命名空间、存储类型
const options = {
namespace: 'vue_', // 本地存储key的前缀
storage: 'local'// 存储类型:local(持久化)/ session(会话级)
}
createApp(App).use(Storage, options).mount('#app')
```
(2)组件中使用:
```
import { getCurrentInstance } from'vue'
const { proxy } = getCurrentInstance()
// 设置存储:key、value、过期时间(秒,可选)
proxy.$ls.set('name', 'Vue插件', 60 * 60) // 1小时后过期
// 获取存储值
console.log('获取存储:', proxy.$ls.get('name'))
// 删除指定存储
proxy.$ls.remove('name')
// 清空当前命名空间下的所有存储
proxy.$ls.clear()
```
## 五、插件使用小技巧(新手避坑指南)
1. **按需引入优先**:除了 vue-router、Pinia 等核心插件,UI 库(如 Element Plus、Vant)和工具库建议按需引入,可大幅减小项目打包体积,提升页面加载速度;
2. **版本匹配是关键**:Vue2 和 Vue3 的插件版本差异较大,安装前务必确认插件适配的 Vue 版本(如 vue-router@3 对应 Vue2,@4 对应 Vue3),避免出现兼容报错;
3. **注册方式有讲究**:核心插件(路由、状态管理)全局注册,保证全项目可用;单个组件的专用工具(如 VueUse 的某个函数)局部引入,避免全局污染,保持项目结构清晰;
4. **二次封装提效率**:网络请求、本地存储等插件,建议在全局注册时做二次封装(如统一请求头、统一存储命名空间、统一错误处理),避免每个组件重复编写相同逻辑。
## 总结
以上 9 个 Vue 插件,覆盖了从项目基础搭建到业务落地的全流程需求:基础核心插件搞定路由跳转和状态共享,UI 组件库快速实现页面搭建,网络插件简化接口请求逻辑,工具插件解决本地存储等高频小需求。
每个插件都经过社区长期验证,稳定可靠,能帮你省去大量重复开发的时间,将精力聚焦在核心业务逻辑上。无论是新手入门还是资深开发者提效,这些插件都是 Vue 项目开发的 “得力助手”,赶紧收藏起来融入你的项目吧!
---

Original JackChen007 Ai懒人码农
继续滑动看下一个[^18]: # 懒人神器 Autorecon
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260207105527-xfi96pa)
## 正文
公众号名称:kali笔记
作者名称:大表哥吆
发布时间:2026-02-05 08:35
> 当下信息收集工具百花齐放,每款工具都有自身的优点和不足。而这需要我们在多款工具中来回切换,因此,本文为大家分享一款更加适合懒人的信息收集工具`autorecon`
>
`AutoRecon`是一款信息收集工具,输入目标IP后,就可以自动联动nmap, gobuster, nikto,如果有smb服务的话也会顺便联动smbclient之类的工具。进行安全测试,一步到位。
在Kali Linux中已经默认安装,输入下面命令可查看相关帮助文档。
```
autorecon -h
```

**小试牛刀**
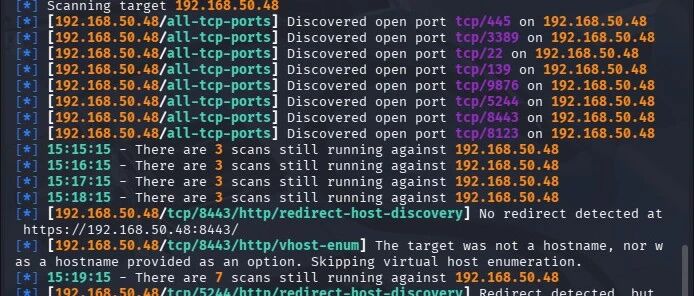
输入目标IP便可以进行全方面的信息收集,如
```
autorecon 192.168.50.48
```
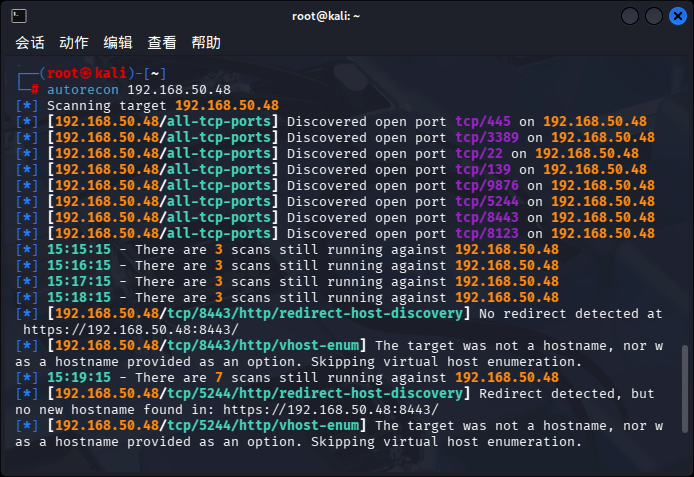
端口扫描效果 准确率还行
其他扫描命令示例:
```
# 扫描多个目标
autorecon 192.168.50.100 192.168.50.101
# 从文件读取目标
autorecon -t xiaoyaozi.txt
# 指定端口范围
autorecon -p "T:21-25,80,443,U:53" 192.168.50.100
```
**扫描结果**
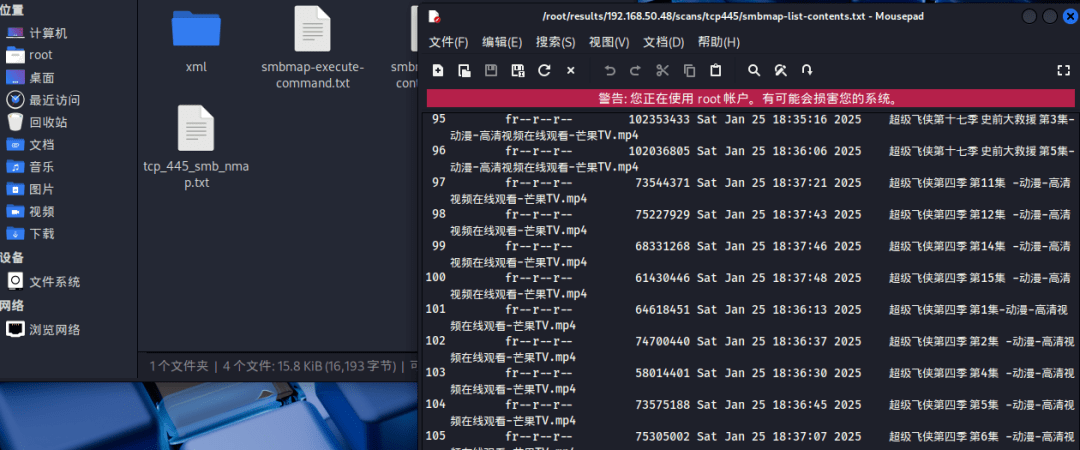
扫描完成后,在`/root/results`会显示相关扫描结果。
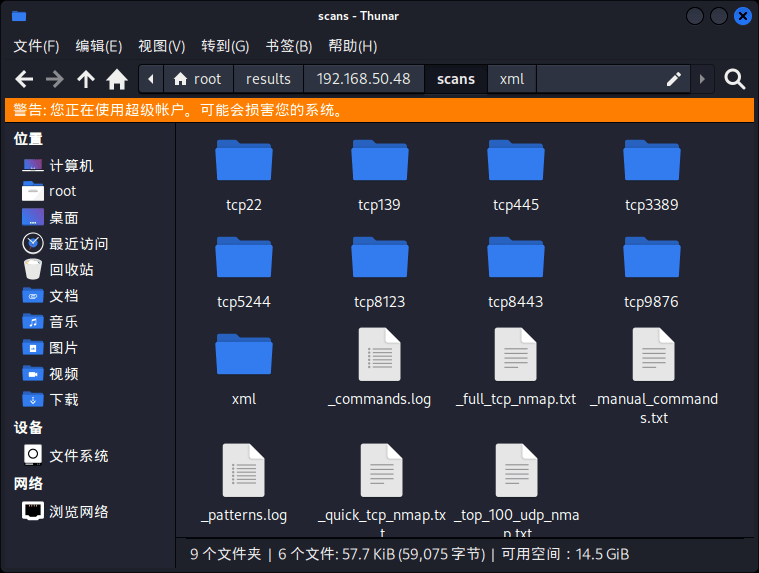
根据不同的开放端口 显示不同的结果
如目标开启了`445`端口,会自动扫描smb共享文件。
更多精彩文章 欢迎关注我们

---
原创 大表哥吆 kali笔记
继续滑动看下一个

kali笔记
向上滑动看下一个[^19]: # 编程中的MVP是什么意思?
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260207212543-k5dvefr)
## 正文
公众号名称:陈宝AI编程
发布时间:2025-12-31 17:00
MVP = 先做一个“能用”的最小版本,不做完整。
用最简单的话说
👉 不是最好
👉 不是最全
👉 只要能解决一个最核心的问题
不考虑UI设计,不考虑用户交互,只需要能有这一个功能,能解决一个问题就是MVP。
为什么一定要先做MVP?
因为你不确定有没有人用
先少花时间
快速试错!
[^20]: # AI编程,我也入局了!
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260208203548-txsm12s)
## 正文
公众号名称:程序员小灰
作者名称:小灰
发布时间:2026-02-08 18:36
大家好,我是程序员小灰。
如今,我们进入AI时代已经整整三年了。

如果说从2023年到2024年,AI在多数时候还仅仅是玩具,那么到了2025年,AI已经真的可以用于生产环境了。
尤其是AI编程这个细分领域,许多互联网企业的程序员已经把AI编程融入自己的日常工作,为编码工作带来了效率的提升。
对于独立开发者和创业者而言,AI编程更加重要,目前已经有许多利用AI编程创造出的产品走入了大众的视野。
比如2024年末,霸榜苹果付费App排行榜的产品“小猫补光灯”,就是一位不太懂代码的产品经理用Cursor开发的。
再比如2025年末,风靡一时的“死了么”App,是由三位95后创业者用1500元的成本快速开发的,其中大概率用到了AI编程技术。

如今2026年刚刚到来,AI编程技术在今年一定进化得更加强大,也会有越来越多的普通人利用AI编程做出爆火的产品。
为了帮助更多朋友掌握AI编程技术,小灰和团队里的四位教练共同设计了一个AI编程训练营。我们计划在6个月的时间里,帮助大家掌握当下主流的各种AI编程工具,并且用AI编程技术做出自己的产品。
这个AI编程训练营,都包含了哪些内容呢?
训练营的第一部分是基础概念和工具的教学,这部分包含如下内容:
1\. 学习Vibe Coding的基本概念,并为非程序员讲解编程涉及的常用工具。
2\. 学习使用百度秒哒。
3\. 学习使用Trae。
4\. 学习使用Cursor。
5\. 学习使用Claude Code。
训练营的第二部分是带着大家进行实战演练,这部分包含如下内容:
1\. 用AI开发Web网站。
2\. 用AI开发游戏。
3\. 用AI开发微信小程序。
4\. 用AI开发桌面应用。
5\. 用AI开发移动端App。
训练营的第三部分是额外的加餐,这部分包含如下内容:
1\. 介绍AI编程的变现路径
2\. 讲解如何进行市场需求的挖掘
3\. 讲解AI开发产品的运营和推广
4\. 2026年AI编程领域的重大更新,我们也会列入到加餐课程当中。
我们这个训练营的交付形式是怎样的呢?
1\. 训练营在2026年3月1日正式发车,整体交付周期为6个月。
2\. 交付形式以直播为主,平均1-2周有一场直播,直播时间在周末晚上。
3\. 每次直播有回放,可以反复回顾,不用担心错过。
4\. 直播课配套清晰的图文讲义,方便大家听课学习与课后复习。
5\. 有任何AI编程相关的疑问,都可以在群里向教练咨询。
这个训练营适合什么样的人群呢?
第一类:创业者,想要做出自己的产品
借助AI编程工具,轻松实现自己心中的产品,带来流量和变现。
第二类:职场程序员,希望提升效率
用好AI编程工具,可以让你的编程效率至少提升3倍。
第三类:编程零基础,希望跟上AI时代的步伐
无需任何编程基础即可学习AI编程,制作自己的小工具为生活和工作带来便利。
第四类:在校学生
学习前沿AI变现技能,探索更多可能性,为今后的职业规划打下基础。
AI编程训练营的价格是多少?
我们的AI编程训练营的原价是1999元。
但由于我们的产品刚刚首发,现在只收大家最低价299元,这个最低价持续到2026年2月12日。
过了2月12日,我们的价格会上涨到399元。后面随着报名人数增加,价格还会进一步上涨,一直上涨到原价1999元为止。
因此,想要抓住这一波AI红利,系统学习AI编程的朋友,一定要抓紧时间以最低价报名哦~~
说到这里,大家应该已经对我们的AI编程训练营有了全方位的了解。
为了方便查阅,小灰还用NanoBanana生成了一张训练营海报,还蛮酷炫的:

对AI编程训练营感兴趣的朋友,欢迎扫码添加小灰微信进行报名,对本训练营有任何的疑问,也欢迎私信咨询。添加微信时请备注“ai编程”:

2026年,希望大家都能抓住AI编程的红利,一起成长,一起变现!
---

Original 小灰 程序员小灰
继续滑动看下一个

程序员小灰
向上滑动看下一个[^21]: # 一句话让 AI 帮我下载各种视频,爽了!
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260208203817-ut1s3ap)
## 正文
公众号名称:程序员鱼皮
发布时间:2026-02-08 12:44
需要用到 yt-dlp 这个超强的开源视频下载器,支持 YouTube、B站、Twitter/X、TikTok、抖音等 1000+ 网站,GitHub 上十几万 Star 不是虚的。
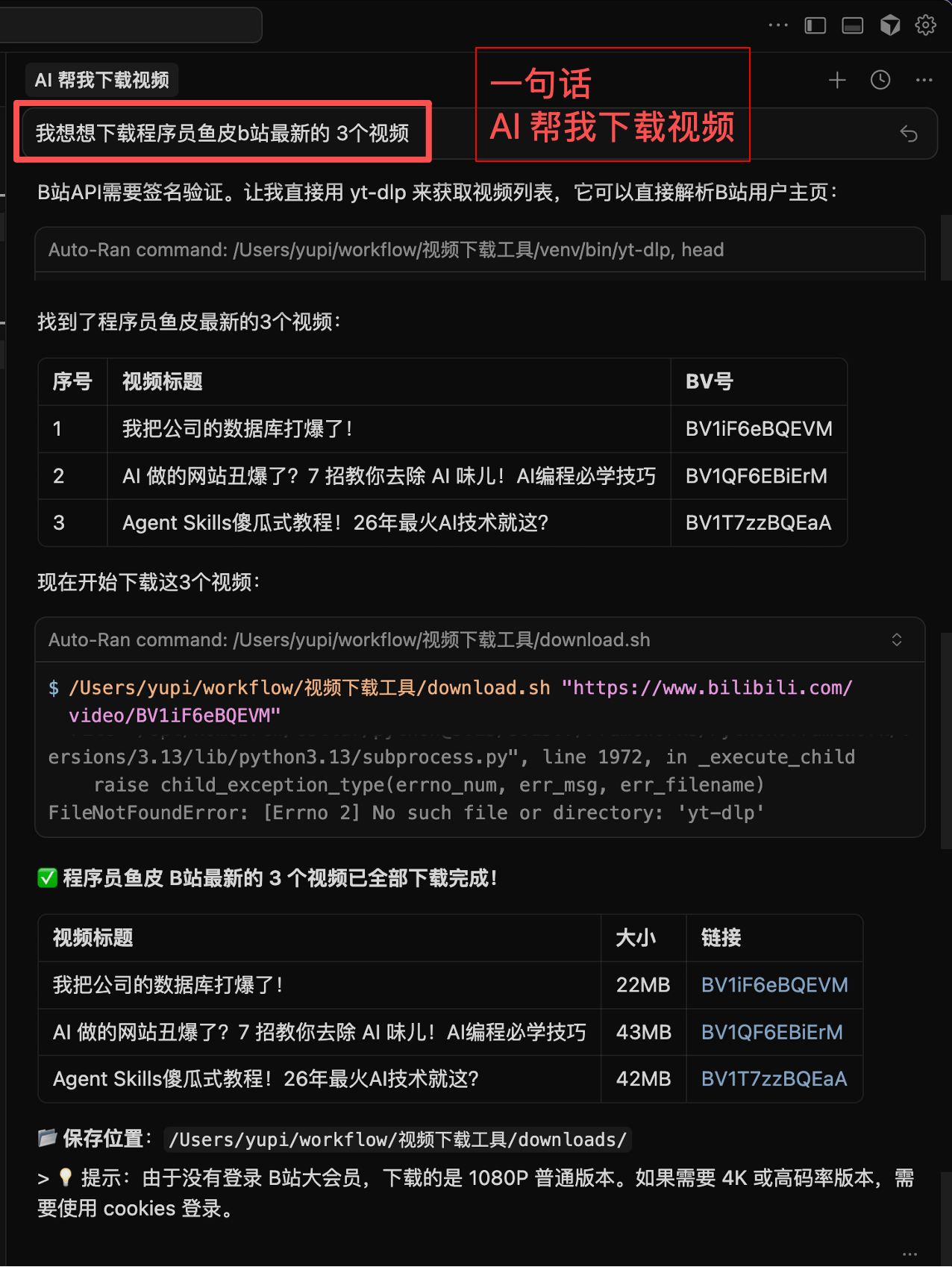
你不需要知道这玩意怎么用,只要打开 Cursor / Claude Code 等 AI 工具,跟 AI 说:
\> 帮我基于 https://github.com/yt-dlp/yt-dlp 项目,封装一套「视频下载工作流」。以后我只需要跟你说要下载什么视频,就会自动帮我下载到本地,并且我可以指定视频的格式
然后 AI 就会编写 Python 脚本,以及教 AI 做事的指令,直到完成任务。
之后你就可以一句话下载视频了,比如跟 AI 说:
\- 帮我下载这个视频 https://xxx
\- 下载这个视频,要 1080p 的 mp4
\- 把这个视频转成 mp3 下载
\- 下载程序员鱼皮在 B 站的最新视频
不用记任何命令、不用装任何软件,说人话就行。想要什么格式、存到哪里、叫什么名字,AI 全帮你搞定。
当然,你也可以让 AI 把它变成网页拿去变现、或者封装成 Skills 整合到你的其他 AI 工作流中。
学会的话记得点赞收藏,别再花冤枉钱买什么视频下载会员了!
一些对大家有用的资源:
👉🏻 100+ 编程学习路线 / 实战项目 / 求职指导 [codefather.cn](/uploads/shares/4/assets/笔记同步助手/attachments/codefather-20260208203817-wy4w629.cn)
👉🏻 100+ 简历模板 [laoyujianli.com](/uploads/shares/4/assets/笔记同步助手/attachments/laoyujianli-20260208203818-ocup053.com)
👉🏻 300+ 企业面试题库 mianshiya.com
👉🏻 500+ AI 资源大全 [ai.codefather.cn](/uploads/shares/4/assets/笔记同步助手/attachments/ai.codefather-20260208203818-j0y2gzt.cn)
👉🏻 1 对 1 模拟面试 [ai.mianshiya.com](/uploads/shares/4/assets/笔记同步助手/attachments/ai.mianshiya-20260208203818-rqs550v.com)
👉🏻 动画学算法教程 [algo.codefather.cn](/uploads/shares/4/assets/笔记同步助手/attachments/algo.codefather-20260208203818-l9a4nq5.cn)
[^22]: # Axios 高效封装实战:拦截器 + 统一处理,彻底告别重复请求逻辑
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260209211526-1y3r2vo)
## 正文
公众号名称:Ai懒人码农
作者名称:JackChen007
发布时间:2026-02-07 08:09
在前端项目开发中,Axios 作为主流的 HTTP 请求库,几乎是必备工具。但直接在业务代码中零散调用 Axios,会面临 token 手动处理、错误提示混乱、loading 状态不统一等问题,不仅增加维护成本,还会影响用户体验。今天就带来一套实战级 Axios 封装方案,包含实例创建、拦截器配置、API 统一管理,让请求逻辑更简洁、更易维护!
## 一、为什么一定要封装 Axios?
直接使用 Axios 看似便捷,实则暗藏诸多痛点:
- 重复工作多:每个请求都要手动添加 token、处理超时、配置请求头;
- 状态管理乱:loading 显示 / 隐藏不统一,不同组件可能出现重复加载效果;
- 错误处理散:网络错误、权限不足、接口异常等错误未集中处理,用户体验参差不齐;
- 维护成本高:多服务请求配置混乱,后续修改需逐个查找调整。
而合理封装后,能实现:
1. 统一配置 baseURL、超时时间、请求头格式;
2. 自动添加 token、统一管理 loading 状态;
3. 集中处理接口错误、token 过期等异常场景;
4. 暴露简洁的 get/post 方法,支持类型推导;
5. 支持多服务实例隔离,适配复杂项目需求。
## 二、Axios 封装核心步骤(附完整代码)
### 1\. 前期准备:安装依赖
首先确保项目中已安装 Axios,若未安装可执行以下命令:
```
npm install axios
```
本文还结合 Vant 组件库的 Toast 做加载和错误提示,若未使用 Vant,可替换为项目中的提示组件。
### 2\. 创建 Axios 实例:实现配置隔离
通过 `axios.create()` 创建独立配置的实例,是封装的核心第一步,能实现多服务配置隔离,提升代码可扩展性。
```
/* 引入依赖 */
import axios, { CanceledError } from'axios'
import { showToast, showLoadingToast, closeToast } from'vant'
import { useUserStore } from'@/store/module/userInfo'
import { getToken } from'@/utils/aes'
// 从环境变量中读取基础地址(灵活适配开发/生产环境)
const apiBaseUrl = import.meta.env.VITE_TARGET
// 创建 Axios 实例
const service = axios.create({
baseURL: apiBaseUrl, // 接口请求基础路径
timeout: 60000, // 请求超时时间(60秒)
timeoutErrorMessage: '请求超时,请稍后再试',
withCredentials: false, // 是否携带 Cookie(根据项目需求调整)
headers: {
// 设置默认请求头格式(表单格式/JSON 格式可按需切换)
'Content-Type': 'application/x-www-form-urlencoded'
}
})
```
#### 关键疑问:为什么要用 axios.create ()?
`axios.create()` 的核心价值是创建**独立配置的 Axios 实例**,不同实例可拥有不同的 baseURL、超时时间、拦截器,完美适配项目中多服务请求场景(如同时调用用户服务、商品服务);同时能统一封装逻辑,避免全局配置污染,大幅提升代码可维护性和复用性。
### 3\. 封装请求拦截器:统一预处理请求
请求拦截器用于在请求发送前完成统一操作,比如添加 token、显示 loading,避免在每个请求中重复编写。
```
const userStore = useUserStore() // 从状态管理中获取用户信息
// 添加请求拦截器
service.interceptors.request.use(
(config) => {
// 1. 自动添加 Token 到请求头
const AuthToken = userStore.getAuthTokenValue()
if (AuthToken) {
config.headers['token'] = `${AuthToken}`// 按后端要求的格式设置(如 Bearer Token 可调整格式)
}
// 2. 统一显示加载状态
showLoadingToast({
message: '加载中...',
forbidClick: true, // 禁止点击背景
iconSize: 30,
loadingType: 'spinner',
className: 'custom-loading-toast'
})
return config // 必须返回配置,否则请求会中断
},
(error) => {
// 处理请求配置阶段的错误(如拦截器逻辑异常)
showToast('网络请求失败,请检查网络状态')
returnPromise.reject(error) // 抛出错误,供业务代码 catch 处理
}
)
```
#### 拦截器核心说明:
`axios.interceptors.request.use()` 接收两个回调函数:
- 第一个回调:请求发送前执行,参数 `config` 为请求配置对象,处理后必须返回 `config`;
- 第二个回调:请求配置失败时执行(如拦截器内抛错),需通过 `Promise.reject` 抛出错误。
### 4\. 封装响应拦截器:统一处理结果与异常
响应拦截器用于接收后端响应后,统一处理成功结果、关闭 loading、处理错误状态(如 token 过期、404、500 等)。
```
// 标记是否正在刷新 token(避免重复刷新)
let isRefreshing = false
// 存储 token 过期后需要重试的请求队列
let requests = []
// 添加响应拦截器
service.interceptors.response.use(
(response) => {
closeToast() // 成功响应后关闭 loading
const res = response.data // 直接返回响应体,简化业务代码处理
// 可根据后端统一响应格式添加业务错误处理(如 res.code !== 200 时提示)
// if (res.code !== 200) {
// showToast(res.msg || '接口请求失败')
// return Promise.reject(new Error(res.msg || 'Error'))
// }
return res
},
async (error) => {
closeToast() // 错误响应后关闭 loading
const { config, response } = error
// 处理不同状态码的错误
if (response) {
switch (response.status) {
case401: // 未授权(token 过期或无效)
// 处理 token 无感刷新逻辑
if (isRefreshing) {
// 若正在刷新 token,将当前请求加入队列
returnnewPromise((resolve) => {
requests.push((newToken) => {
config.headers['token'] = `${newToken}`
resolve(service(config))
})
})
}
isRefreshing = true
try {
const newToken = await getToken() // 调用刷新 token 接口
// 重试队列中的所有请求
requests.forEach((cb) => cb(newToken))
requests = []
// 重试当前请求
config.headers['token'] = `${newToken}`
return service(config)
} catch (e) {
showToast('登录已过期,请重新登录')
// 跳转至登录页(根据项目路由配置调整)
// router.push('/login')
returnPromise.reject(error)
} finally {
isRefreshing = false
}
case403: // 禁止访问
showToast('无权限访问该资源')
break
case404: // 资源未找到
showToast('请求资源不存在')
break
case500: // 服务器错误
showToast('服务器异常,请稍后再试')
break
default: // 其他错误
showToast(response.data?.message || error.message || '请求失败')
}
} else {
// 无响应(如网络错误)
showToast('网络连接异常,请检查网络')
}
returnPromise.reject(error)
}
)
exportdefault service
```
### 5\. API 统一管理:集中维护接口地址
创建 `api.ts` 文件,统一封装所有接口请求方法,避免接口地址散落在业务代码中。
```
import request from'@/service/axios'
// GET 请求示例:查询列表
exportfunction getListApi(params: { page: number; size: number }) {
return request.get('/api/list', { params })
}
// POST 请求示例:提交表单
exportfunction submitFormApi(data: { name: string; age: number }) {
return request.post('/api/submit', data)
}
// 备注:最终请求地址 = baseURL + 接口路径(如 baseURL 为 https://xxx.com,最终地址为 https://xxx.com/api/list)
```
### 6\. 页面中实战使用:简洁调用
封装完成后,页面中直接引入 API 方法即可,无需关注 token、loading、错误处理等逻辑。
```
import { getListApi, submitFormApi } from'@/api'
// 调用 GET 接口
const getList = async () => {
try {
const res = await getListApi({ page: 1, size: 10 })
// 处理接口返回数据
console.log('列表数据:', res)
} catch (error) {
// 可选:处理特定业务错误(通用错误已在拦截器处理)
console.error('请求失败:', error)
}
}
// 调用 POST 接口
const submitForm = async () => {
try {
const res = await submitFormApi({ name: '张三', age: 25 })
showToast('提交成功')
console.log('提交结果:', res)
} catch (error) {
console.error('提交失败:', error)
}
}
```
## 三、封装核心优势总结
1. **高效复用**:统一处理 token、loading、错误提示,减少重复代码;
2. **易于维护**:接口地址集中管理,修改时无需逐个查找;
3. **用户体验佳**:loading 统一显示、错误提示标准化,token 无感刷新;
4. **扩展性强**:支持多服务实例、类型推导,适配中大型项目;
5. **降低耦合**:业务代码与请求逻辑分离,代码结构更清晰。
## 四、常见问题解答
### Q1:axios.create () 和直接使用 axios 有什么区别?
A:`axios.create()` 会创建独立的 Axios 实例,拥有自己的配置(baseURL、超时时间、拦截器等),可实现多服务隔离(如同时调用 A 服务和 B 服务,各自配置不同 baseURL);而直接使用 axios 是全局配置,修改后会影响所有请求。
### Q2:拦截器中为什么必须返回 config 或 Promise?
A:请求拦截器需返回 config 才能让请求正常发送,否则请求会被中断;响应拦截器返回数据供业务代码使用,错误时需返回 Promise.reject,让业务代码能通过 catch 捕获错误。
### Q3:token 无感刷新的核心逻辑是什么?
A:当检测到 401 状态码时,标记正在刷新 token,将后续请求存入队列;刷新 token 成功后,重试队列中的所有请求,并更新当前请求的 token,实现用户无感知。
通过以上封装方案,既能解决日常开发中的请求痛点,又能让代码更具规范性和可维护性。赶紧整合到你的项目中,提升前端请求效率吧!如果需要根据项目特殊需求调整封装逻辑(如多环境配置、请求取消等),可以随时灵活扩展~
---

Original JackChen007 Ai懒人码农
继续滑动看下一个[^23]: # OpenClaw(clawdbot)是什么?它与 Skills、MCP、RAG、Memory 与 AI Agent 的关联解析
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260210144435-fnky7z4)
## 正文
作者: 小白debug
发布日期: 未知
## 引言
近年来,随着大模型的快速发展,围绕模型的使用与扩展形成了一套完整的技术体系。OpenClaw(又名 clawdbot)正是基于这套体系构建的一款 AI 代理产品。本文系统梳理 OpenClaw 的核心概念,并阐明它与 Skills、MCP、RAG、Memory、AI Agent 等技术的关联。
## 推理服务(Inference Service)
大模型本身是一个存放在磁盘上的巨型文件,文件中保存了经过训练得到的参数。要让模型产生响应,需要有专门的程序把模型加载到内存,并对外提供 HTTP 接口,接收用户请求、进行推理并返回结果,这一过程即称为推理服务。推理服务通常以无状态的方式运行,多个实例通过负载均衡共同承载高并发请求。

推理服务架构示意图
## 记忆(Memory)
推理服务是无状态的,每次请求结束后便不保留任何上下文。然而在聊天场景中,用户希望模型能够记住前面的对话。实现这一点的方式是:在每一次请求时将历史对话拼接到当前请求的上下文中发送给模型。为了避免上下文过长,系统会将对话分为短期记忆(最近几轮完整保留)和长期记忆(提炼关键信息生成摘要)。这种上下文管理机制即为记忆(Memory)。

记忆管理示意图
## 检索增强生成(RAG)
大模型的知识截止于训练时的快照,无法直接获取实时信息或企业内部文档。RAG(Retrieval‑Augmented Generation)通过在外部知识库中检索相关文档,将检索结果与用户问题一起喂给模型,从而实现基于最新或专有数据的回答。传统的关键字匹配难以匹配语义相近的表达,向量化文本并使用向量相似度搜索可以解决这一难题。向量数据库(如 Milvus、PostgreSQL + pgvector)因此成为 RAG 的重要组成部分。
RAG 工作流示意图
## 模型联系协议(MCP)
单纯的对话模型只能输出文字,若要让模型真正去操作系统资源(例如发送邮件、调用 GitHub API),需要约定一种结构化的消息格式。MCP(Model‑Contact‑Protocol)定义了模型与外部工具之间的通信协议:模型在需要使用工具时输出符合 JSON 规范的指令,外部的 MCP Host 解析该指令并执行相应操作,再把结果回传给模型。MCP 插件可以分为本地客户端(负责接收指令)和远端服务器(实际调用第三方 API),如 GitHub MCP 插件。

MCP 消息流示意图
## 技能(Skills)
拥有了多种工具(MCP 插件)后,模型仍需要知道在何种情境下使用哪些工具以及使用的顺序。Skills 则是一套结构化的操作手册,描述了特定业务场景的完整工作流。例如在排查线上故障时,Skills 规定先查看监控、判断影响范围、再查日志和配置,必要时执行回滚。Skills 为模型提供了经验和流程,使其能够像真正的工程师一样有条理地完成任务。

Skills 故障排查流程图
## AI 代理(AI Agent)
将记忆(Memory)、检索增强生成(RAG)、模型联系协议(MCP)以及 Skills 组合在一起,就形成了能够自主完成目标的 AI 系统——AI 代理(Agent)。在提示词的引导下,Agent 可以担任客服、程序员、律师等角色,并在用户指令下执行相应操作。OpenClaw 正是基于上述技术栈实现的 AI 代理产品。
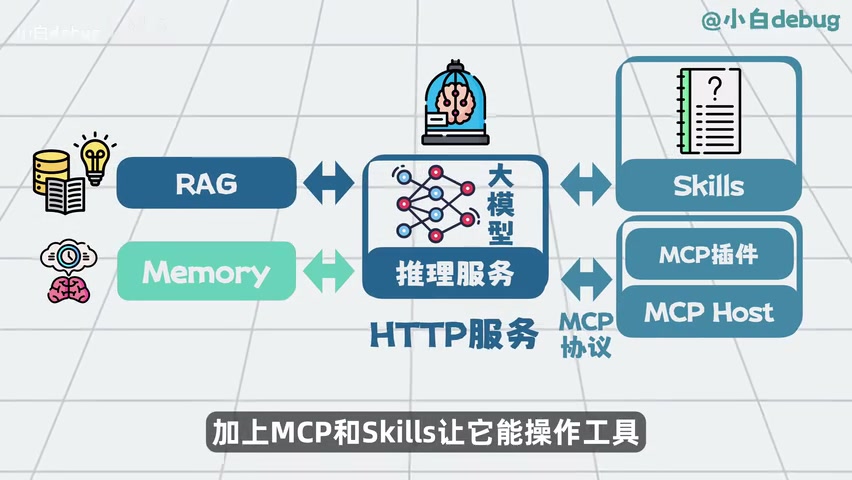
OpenClaw(clawdbot)整体架构图
## 案例:Cloudboard 作为 OpenClaw 的实现
Cloudboard 是目前刷屏的本地 AI 代理,它把上述概念落地为一个可以直接在用户电脑上执行指令的系统。用户通过自然语言告诉 Cloudboard 想要完成的任务,系统依据内部的 Skills 与 MCP 插件自动操作系统,实现发送邮件、投递简历、执行交易等功能。由于直接控制本地环境,权限管理与安全防护成为关键考量。
## 总结
OpenClaw(clawdbot)通过将推理服务、记忆管理、检索增强生成、模型联系协议以及技能流程有机组合,为大模型赋予了记忆、知识检索、工具调用和业务经验四大能力,进而形成可在真实环境中自主行动的 AI 代理。这套技术体系正在推动从“会聊天”向“会实际操作”迈进。[^24]: # Conventional Commits 规范详解
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260211192757-3xq0sy7)
## 正文
公众号名称:陆震生物统计
作者名称:luzhen
发布时间:2025-04-18 18:03
原文链接:[https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzI1MTU4NjIyMg==\x26amp;action=getalbum\x26amp;album_id=2156280842229186561#wechat_redirect](/uploads/shares/4/assets/笔记同步助手/attachments/https---mp.weixin.qq.com-mp-appmsgalbum--_-_bizMzI1MTU4NjIyMg--x26ampactio-20260211192757-zkg5v4a.com-mp-appmsgalbum--_-_bizmzi1mtu4njiymg--x26ampactiongetalbum--x26ampalbum-_id2156280842229186561wechat-_redirect)
## 背景
在软件开发中,版本控制是一个至关重要的环节。Git 是最流行的版本控制系统之一,而 Git 提交信息(commit message)则是记录代码变更的重要方式。而我们经常会遇见:
- 查看项目 Git 日志时,提交信息杂乱无章,完全看不懂每个提交的意图。
- 手动编写 CHANGELOG 耗时费力,还容易遗漏重要变更。
- 团队协作中,成员提交风格不一,代码审查效率低下
为了提高 Git 提交信息的可读性和一致性,Conventional Commits 规范(地址:https://www.conventionalcommits.org/en/v1.0.0/)应运而生。这是一套被 Angular、Vue 等顶级开源项目广泛采用的 Git 提交规范,能将提交信息从混乱的草稿变为清晰的文档。
这里,我们将详细介绍 Conventional Commits 规范的定义、格式、使用场景以及一些最佳实践。

Conventional Commits
## Conventional Commits 规范
Conventional Commits 是一套基于 Git 提交消息的轻量级约定,旨在通过结构化格式提升提交信息的可读性和自动化处理能力。它的核心目标包括:
- 人类可读:清晰描述提交的意图和影响范围。
- 机器友好:支持自动化生成 CHANGELOG 和语义化版本(SemVer)。
- 团队协作:统一提交风格,减少沟通成本。
## 格式结构
一条规范的提交消息需包含以下部分(部分可选):
```
<类型>[可选范围]: <简短描述>
[可选正文]
[可选脚注]
```
### 1\. 类型(type)
类型是提交的核心部分,表示提交的目的和性质。常见的类型包括:
|类型|用途|对应 SemVer|
| -----------------| ----------------------------------| ---------------------|
|feat|新增功能|MINOR(次版本)|
|fix|修复 Bug|PATCH(补丁版本)|
|BREAKING CHANGE|破坏性变更(如 API 不兼容)|MAJOR(主版本)|
|docs|文档更新|\-(不影响版本)|
|style|代码格式调整(如缩进、空格)|\-(不影响版本)|
|refactor|代码重构(不新增功能或修复 Bug)|\-(不影响版本)|
其他推荐类型有:build(构建系统)、ci(持续集成)、test(测试用例)等。
这里我们插一句,对于版本号的控制,可以参考以下规则:

版本号控制
### 2\. 可选范围(scope)
可选范围用于指定提交影响的模块或功能区域。它可以是一个具体的模块名、文件名或其他标识符。范围有助于快速定位问题和理解变更的上下文。
例如:`feat(auth): add JWT authentication` 表示在 `auth` 模块中新增了 JWT 身份验证功能。
### 3\. 简短描述(subject)
简短描述是对提交内容的简要说明,通常不超过 72 个字符。它应以小写字母开头,并使用祈使句(imperative mood)来描述变更的目的。
例如:`fix: correct typo in README` 表示修复了 README 文件中的拼写错误。
### 4\. 可选正文(body)
可选正文用于详细描述提交的内容和背景信息。它可以包含多行文本,通常用于解释为什么要进行此更改、如何实现等。正文应与简短描述之间空一行。
例如:
```
feat: 支持多语言切换
新增中英文切换按钮,默认跟随系统语言。
依赖第三方库 `i18n-utils`,需运行 `npm install` 安装。
```
### 5\. 可选脚注(footer)
可选脚注用于记录与提交相关的其他信息,如关联的任务、问题或破坏性变更。它通常以 `BREAKING CHANGE:` 开头,后跟详细说明。脚注也可以包含引用的 issue 编号或链接。
例如:
```
BREAKING CHANGE:
- 更新了 API 接口,删除了 `getUser` 方法,改为 `fetchUser`。
- 需要更新客户端代码以适应新接口。
Closes #123
Review by @zhenlu
```
## 为什么推荐使用
### 1\. 自动化工具支持
- 生成 CHANGELOG:工具(如 standard-version)可自动从提交历史提取内容生成变更日志。
- 语义化版本控制:根据提交类型自动升级版本号(feat → MINOR,fix → PATCH,BREAKING CHANGE → MAJOR)。
- 代码审查加速:通过类型快速定位提交意图,减少沟通成本。
### 2\. 团队协作效率提升
- 统一提交风格:团队成员遵循相同的提交规范,减少沟通障碍,避免风格混乱。
- 清晰的历史记录:通过结构化的提交信息,团队成员可以快速了解项目进展和变更。
- 问题追溯:通过关联的 issue 编号和脚注,快速定位问题和变更历史。
### 3\. 开源项目友好性
- 开源项目通常需要清晰的文档和变更记录,Conventional Commits 规范可以帮助维护者和用户快速了解项目的演变。
- 社区贡献者可以通过遵循规范的提交信息,轻松参与项目开发,降低贡献门槛。
## Takeaway
Conventional Commits 不仅是技术规范,更是团队协作的沟通协议。通过标准化提交信息,它能将 Git 日志从杂乱的历史记录升级为项目演进的清晰路线图。无论是个人项目还是大型团队,尽早引入这一规范都将显著提升开发效率和代码质量。
---

原创 luzhen 陆震生物统计
阅读原文
继续滑动看下一个

陆震生物统计
向上滑动看下一个[^25]: # 建议Java工程师都要学习一下Go语言
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260211192759-4bzrlgu)
## 正文
公众号名称:王中阳
作者名称:地鼠哥
发布时间:2026-02-11 08:02
原文链接:[https://mp.weixin.qq.com/s/o2c5glt8gyc76DpAfx5mVA#rd](/uploads/shares/4/assets/笔记同步助手/attachments/https---mp.weixin.qq-20260211192759-wkl46yy.com-s-o2c5glt8gyc76dpafx5mvard)
## 开篇:这不是一篇劝退Java的文章
首先声明,我不是来劝你放弃Java的。
我深知Spring全家桶在企业级应用开发中的统治地位,写业务逻辑、搞复杂架构、做ERP系统,Java依然是当之无愧的王者。
但是,**作为一名有追求的Java工程师,我强烈建议你把Go语言加入你的武器库。**
为什么?因为时代变了。
## 理由一:突破"应用层"的天花板
你有没有发现,当你把Java学通了,Spring源码看完了,JVM调优搞定了,似乎就触碰到了一层隐形的天花板?
往上看,是业务架构;**往下走,是基础设施。**
而今天的基础设施,**几乎是Go语言的天下**:
- **容器编排**:Kubernetes (Go)
- **容器引擎**:Docker (Go)
- **服务网格**:Istio (Go)
- **监控告警**:Prometheus (Go)
- **配置中心**:Etcd (Go)
- **网关代理**:Traefik, Envoy (Go周边)
如果你只会Java,当Kubernetes集群出现诡异调度问题时,当Prometheus抓取不到数据时,你只能看着黑盒干着急。
**学会Go,你就不再只是一个"写接口的",你拥有了窥探和掌控整个云原生基础设施的能力。**
## 理由二:Java太重,Go太快
Java被人诟病最多的就是"重"。
写一个简单的CLI工具,或者一个轻量级的Sidecar代理:
- **Java**:启动慢,吃内存,还需要装JRE。
- **Go**:编译成一个二进制文件,丢上去就能跑,启动瞬间完成,内存占用极低。
在微服务架构中,越来越多的辅助组件(Agent、Sidecar、Forwarder)都在转向Go。作为Java工程师,如果你能用Go快速写一个高性能的辅助工具,解决生产环境的燃眉之急,这绝对是你的核心竞争力。
## 理由三:Java工程师学Go,简直是降维打击
很多Java同学不敢学Go,觉得是新语言,门槛高。
**大错特错!**
Go语言的设计哲学是"做减法"。相比于Java复杂的继承、多态、注解、反射,Go简单得令人发指。
对于Java工程师来说,学Go几乎是无痛的,因为核心概念完全互通:
|Java概念|Go概念|区别|
| -----------| ---------------| ------------------------------|
|Class|Struct|没有继承,只有组合|
|Interface|Interface|鸭子类型(隐式实现),更灵活|
|Thread|Goroutine|极轻量级,启动几十万个都没事|
|Try-Catch|if err != nil|显式处理,代码逻辑更清晰|
|Maven|Go Mod|依赖管理更简单|
## 实战对比:一眼看懂Go的"简单"
我们来看一个最简单的HTTP服务,感受一下两者的区别。
### Java (Spring Boot)
你需要配置Controller,注解,依赖注入...
```
@RestController
public class HelloController {
@GetMapping("/hello")
public String hello(@RequestParam String name) {
return "Hello, " + name;
}
}
```
看似代码少,但这背后需要庞大的Spring框架支撑,启动时间几秒到几十秒不等。
### Go (Gin)
代码直观,逻辑从上到下,没有魔法。
```
package main
import "github.com/gin-gonic/gin"
func main() {
r := gin.Default()
r.GET("/hello", func(c *gin.Context) {
name := c.Query("name")
c.String(200, "Hello, %s", name)
})
r.Run() // 监听 0.0.0.0:8080
}
```
编译成二进制文件后,只有十几MB,没有任何依赖,启动耗时毫秒级。
## 核心思维转变:从"对象"到"组合"
Java工程师转Go,最大的障碍不是语法,而是思维。
Java喜欢**层层封装**:`Controller -> Service -> Manager -> DAO -> Entity`
Go喜欢**简单直接**:`Handler -> Logic -> Repo`
Java喜欢**继承**:`BaseController -> UserController`
Go喜欢**组合**:
```
type UserHandler struct {
*BaseHandler // 组合
UserService *UserService
}
```
一旦你习惯了Go的这种"乐高积木"式的组合思维,你会发现代码变得异常清晰,维护起来也轻松很多。
## 结语:技多不压身
最后,我想说的是:**学习Go并不是要你抛弃Java。**
- **做复杂业务系统**,Java依然是首选,生态无敌。
- **做中间件、工具、高并发网关、K8s插件**,Go是神兵利器。
作为一名资深Java工程师,拥有Java的架构思维,再加上Go的工程效率,你将成为团队中不可或缺的"全栈基础设施专家"。
别犹豫了,今天就下载Go,写下你的第一个 `fmt.Println("Hello World")` 吧。
我整理了有2千多人加入的[升职加薪知识星球](/uploads/shares/4/assets/笔记同步助手/attachments/升职加薪知识星球-20260211192800-rj3u432)和辅导到就业为止的[就业陪跑训练营](/uploads/shares/4/assets/笔记同步助手/attachments/就业陪跑训练营-20260211192800-o8oz7lr)里,**最高频、最伤人**的AI/Go/Java面试真题与解析,做成了一份**高密度PDF面经**。
与其自己全网搜索,不如扫码备注 **【面试】** ,我直接发你。

> wangzhongyang.com 也欢迎大家直接访问我的官网,里面有Go / Java / AI 的资料,**免费学习**!
>
---

Original 地鼠哥 王中阳
Read more
继续滑动看下一个

王中阳
向上滑动看下一个[^26]: # 干掉 Vite ?尤雨溪开始 -强推- Vize ?
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260224091931-cxrbptz)
## 正文
公众号名称:前端开发爱好者
作者名称:认真努力的小四子
发布时间:2026-02-24 08:33
🔥 **Vue** 工具链要被重写了?
**Rust** 打造的 **Vize** 正在掀桌子!
前端这两年有一个明显**趋势**:
> **用 Rust 重写前端工具链。**
>
从打包器到编译器,从 `Lint` 到格式化,底层正在被全面`“原生化”`。
而这一次,轮到了 `Vue`。

一个正在快速演进的项目 ——**Vize**, 正在尝试用 `Rust` 重构整套 `Vue` 工具体系。
它不仅仅是“更快一点”, 而是想把 **Vue** 的`编译`、`分析`、`格式化`、`类型检查`、
```
IDE
支持
```
全部统一进一个高性能内核。
## 🧠 Vize 到底是什么?

> **Vize** = 用 **Rust** 重写 **Vue** 工具链。
>
它是一个 **非官方的高性能 Vue.js 工具体系**,覆盖:
- `SFC 编译`
- `Lint`
- `Formatter`
- `Type Check`
- `CLI`
- `LSP`
- `组件画廊`(类似 Storybook)
- `Vite 插件`
- `Nuxt 集成`
- `WASM 浏览器运行`
- `MCP / AI 集成`
你没看错—— 它不是一个插件,而是一整套 **“Vue 开发底层重构计划”** 。
## ⚔️ 它和 Vite 是什么关系?
很多人第一反应:
> 那它是不是要干掉 **Vite**?
>
答案:**不是同一个层级。**
- **Vite** 是通用构建平台
- **Vize** 是 `Vue` 编译与分析引擎
更准确理解:
```
Vite = 构建平台
Vize = Vue 的高性能编译核心
```
**Vize** 可以通过 `@vizejs/vite-plugin` 无缝接入 `Vite`, 作为 **Vue** 编译后端替换默认实现。
这更像是:
> 给 **Vite** 换一颗`“性能级引擎”`。
>
## 🚀 快速安装使用
安装 `CLI`:
```
npm install -g vize
```
核心`命令`:
```
vize build
vize lint
vize fmt
vize check
```
它试图替代:
- `@vue/compiler-sfc`
- `eslint-plugin-vue`
- `prettier`
- `vue-tsc`
关键点在于:
> 所有能力共享同一个 `AST` 与解析器。
>
这意味着`更一致的语义分析`和`更少工具间不一致`问题。
## 🏗 架构设计:它为什么不只是“快一点”?
**Vize** 采用典型的 `Rust crate` 分层架构:

#### 第一层:基础解析层
- `Token 化`
- `Span 位置系统`
- `AST 构建`
#### 第二层:编译与转换核心
- `SFC 解析`
- `模板编译`
- `JS/TS 转换`
- `CSS scoped 处理`
- `Vapor 高级编译模式`
#### 第三层:开发工具层
- `Lint`
- `Formatter`
- `Type Check`
- `LSP`
- `CLI`
- `Musea` 组件画廊
这种结构带来一个巨大优势:
> 统一语义引擎驱动所有工具。
>
传统 **Vue** 工具链是“拼装车”:
- `编译器一套`
- `ESLint 一套`
- `Prettier 一套`
- `vue-tsc 一套`
而 **Vize** 是`“一体化引擎”`。
## ⚡ 性能:不是优化,是碾压
官方基准测试(`15,000` 个 `SFC` 文件):
#### 编译速度

- 官方 **compiler**:`10.52s`
- **Vize** 单线程:`3.82s`
- **Vize** 多线程:`0.38s`
👉 多线程下接近 **27× 提升**
#### Lint

- **ESLint**:`65.30s`
- **Vize**:`5.45s`
👉 约 12× 提升
#### 格式化

- **Prettier**:`82.69s`
- **Vize**:`0.036s`
👉 理论上数千倍差距(极端场景)
#### Type Check

- **vue-tsc**:`35.69s`
- **Vize**:`0.369s`
👉 约 `50~90×` 提升
为什么这么快?
- 无 `GC`
- 无 `JIT` 预热
- `Rust` 零成本抽象
- `Rayon` 原生多线程
- `Arena` 内存分配
- `更高缓存命中率`
这不是微调,是底层模型差异。
## 🤖 更疯狂的是:AI 集成
**Vize** 还支持 `MCP(Model Context Protocol)`集成。
这意味着什么?
> **AI** 不再“猜”你的组件 `API`。
>
通过 **MCP Server**:
- **列出组件**
- **查询 props**
- **获取 slots**
- **获取默认值**
- **生成真实可运行示例**
配合 **Visual Studio Code** 的 `Agent` 模式,`AI` 可以:
- 直接理解你的组件库
- 自动生成准确示例
- 辅助重构
- 理解设计 `token`
## 🧩 与 Nuxt / WASM 的结合
**Vize** 支持:
- `Nuxt` 模块接入
- 浏览器内 `WASM` 编译
- 在线 `Playground` 场景
- `多环境`运行
这意味着它不仅是 `CLI`, 也是一个可嵌入式 `Vue 编译引擎`。
## ❗ 现在能生产使用吗?
还不行。
它仍处于`实验阶段`,`API` 可能变化。
但趋势往往在成熟之前就已经确定方向。
## 📌 总结一句话
如果说:
- **Vite** 解决了`“开发速度”`
- 那 **Vize** 正在解决`“工具链底层重构”`
它可能不会明天取代所有东西,
但它已经说明了一件事:
> **Vue** 的未来,不止是框架升级,而是工具链升级。
>
如果你是:
- **Vue 深度使用者**
- **工具链爱好者**
- **编译器技术关注者**
- **或对 AI + 前端感兴趣**
这个项目值得关注。
- **GitHub**:[https://github.com/ubugeeei/vize](/uploads/shares/4/assets/笔记同步助手/attachments/https---github-20260224091933-95wmsqm.com-ubugeeei-vize)
- **官网**:[https://vizejs.dev](/uploads/shares/4/assets/笔记同步助手/attachments/https---vizejs-20260224091934-jvt7r13.dev)
---

Original 认真努力的小四子 前端开发爱好者
继续滑动看下一个[^27]: # MiniCPM-o 4.5 开源了,登上了开源热榜。
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260214154557-rqfyjml)
## 正文
公众号名称:逛逛GitHub
作者名称:逛逛
发布时间:2026-02-13 15:05
# MiniCPM-o 4.5 开源了。
这是面壁智能 OpenBMB 在 2 月正式开源的新一代全模态旗舰模型,参数量只有 9B。
却对标甚至在多项任务上追平乃至超越一些闭源大模型,被很多人称为端侧 GPT‑4o 平替。
目前 MiniCPM-o 4.5 开源模型已经登上了 Hugging Face 的热榜第 2。

MiniCPM-o 4.5 能同时看图/视频、听声音、说话和输出文字。
并且支持全双工,也就是一边看一边听的同时还能主动说话,目标是把接近 GPT‑4o / Gemini 2.5 Flash 水平的多模态能力,塞进手机、PC、车机等端侧设备上运行。
**
01
**开源项目简介**
**
# 
**MiniCPM-o 4.5 = 9B 参数的开源全模态大模型 + 原生全双工实时交互 + 端侧友好部署**
这几个关键词听着挺炫酷的,用人话解释一下就是:
**① 全模态(Omni)**
能同时处理图像、视频、文本、音频输入,输出文本和语音。
**② 全双工(Full Duplex)**
**能做到边看、边听、边说,不是回合制问答。**
传统对话式 AI 是对讲机模式,你说完一句,它才开始想、然后再回一句。MiniCPM‑o 4.5 的思路是:让 AI 像人一样,一直在看和听,同时决定什么时候说。
**听起来容易,做起来难。**
**除了要做到输入输出并行**,互不阻塞。模型在说话时,**眼睛和耳朵还不能关机**,还得继续看视频、听你说话。
甚至你可以随时打断、随时插话,它能立刻切换话题或调整回应。
**③ 端侧优先(Edge-native)**
只有 9B 参数,却在视觉理解、文档解析、语音交互等方面,做到接近 Gemini 2.5 Flash 级别,同时又适合在本地设备上跑,比如手机、车机、机器人、平板等。
```
开源地址:https://github.com/OpenBMB/MiniCPM-o
Hugging Face:https://huggingface.co/openbmb/MiniCPM-o-4_5
```
**
02
**它是怎么做到又全又小的?**
**
从技术结构看,MiniCPM-o 4.5 可以粗略理解为:
在 Qwen3‑8B 语言底座上,接入 SigLIP2 视觉编码、Whisper 语音理解、CosyVoice2 语音生成,
再用统一全模态架构打通,做成一个端到端的全模态大脑。

几个关键点值得展开说一下:
① 统一的全模态架构
不再是视觉模型 → 丢给语言模型的松散拼接,而是从输入编码到输出解码,都由一个统一系统协调
文本、语音、图像、视频会在一个共享的语义空间里被理解,这让跨模态推理更自然,比如:
一边看视频、一边听声音时,能理解谁在说话、刚刚发生了什么,而不是分别对待音轨和画面
② 全双工语音解码
语音解码器采用文本 token + 语音 token 交错建模的方式
这带来两个直接好处:在输出语音时,仍然可以持续读入新输入,实现真正意义上的全双工,长语音时音色更统一、语气更自然,不容易越说越飘。
③ 高效视觉/视频处理
借鉴了 MiniCPM-V 4.5 的设计:
使用高效视觉 backbone + token 压缩策略,把高分辨率图像和多帧视频压缩到极少的视觉 token 数量
结果是:视频理解的性价比极高,在同样的算力预算下,它能看的内容比同类模型多得多,特别适合端侧设备上做长视频分析、实时摄像头理解。
**
03
**如何使用**
**
最简单的,你可以在 Hugging Face 上直接使用搭建好的 Demo,获取语音和摄像头权限就行了。

```
Demo:https://huggingface.co/spaces/openbmb/MiniCPM-o-4_5-Demo
```
MiniCPM-o 4.5 之所以在开源社区讨论度极高,一个很大的原因是:它不是只活在论文里的模型,而是从一开始就被设计为要在设备上跑。

具体部署方式,可以看下面这个链接:
```
部署指引:https://github.com/OpenSQZ/MiniCPM-V-CookBook/blob/main/demo/web_demo/WebRTC_Demo/README_zh.md
```
官方已经给出了一整套开源部署方案,包括但不限于:
llama.cpp-omni:
- 面壁自研的开源流式全模态推理框架
- 主打端侧/边缘设备上的低延迟推理,支持全双工交互
常见推理框架适配:
- vLLM、SGLang、Ollama、LLaMA-Factory 等
多种量化模型:
- 原始 bf16 约需要 19GB 显存
- int4 量化后内存可降到 约 11GB 或更低,速度可超过 200 tokens/s
在一块主流消费级 GPU 上,跑起一个会看会听会说的全模态 AI。
另外在国产算力生态方面,MiniCPM-o 4.5 通过 FlagOS 系统软件栈,已经适配了多家国产芯片,包括:天数智芯、华为昇腾、平头哥、海光、沐曦等
对于想在国产硬件上落地 AI 应用的团队,MiniCPM-o 4.5 已经是一个拿来就能跑的成熟选项,而不是停留在 PPT 阶段。
04
**点击下方卡片,关注逛逛 GitHub**
这个公众号历史发布过很多有趣的开源项目,如果你懒得翻文章一个个找,你直接关注微信公众号:逛逛 GitHub ,后台对话聊天就行了:
---

Original 逛逛 逛逛GitHub
继续滑动看下一个

逛逛GitHub
向上滑动看下一个[^28]: # Vue3 开发效率翻倍!VueUse 工具库从入门到实战
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260214154541-18rw7iz)
## 正文
公众号名称:Ai懒人码农
作者名称:JackChen007
发布时间:2026-02-13 08:08
做 Vue3 开发的你,是不是总在重复踩这些坑?每次新项目都要手写响应式逻辑、封装浏览器 API,处理个复制功能还要考虑跨浏览器兼容,写个监听事件又担心忘记销毁导致内存泄漏…… 明明是重复劳动,却占了开发中大半的时间。
如果你想摆脱这些繁琐的底层实现,把精力全放在核心业务上,那一定要试试**VueUse**—— 这款 Vue3 专属的组合式工具库,由 Vue 核心团队成员 Anthony Fu 主导维护,汇集了 200 + 开箱即用的 Composition API 函数,能让你省去 80% 的重复代码,开发效率直接拉满!它就像 Vue3 世界的 Lodash,专为响应式和 Vue 生态打造,是每个 Vue3 开发者都该入手的效率神器。
## 🌟 认识 VueUse:Vue3 的 “超能力” 工具箱
VueUse 是一套基于 Vue3 Composition API 的实用函数集合,由社区共同维护,经过了严格的测试和跨平台验证,如今已是 Vue 生态中最受欢迎的工具库之一。
简单来说,VueUse 把开发中**常用但繁琐**的功能全封装成了以`use`开头的组合式函数,小到鼠标位置监听、本地存储同步,大到元素懒加载、网络请求处理,你能想到的前端开发场景,几乎都能在里面找到对应的解决方案。
### 核心特性:兼顾易用性与专业性
VueUse 能成为开发者标配,离不开这些亮眼特性,不管是新手还是资深开发者,都能快速适配:
1. **Vue3 原生适配**:所有函数遵循 Composition API 规范,`setup`语法糖 /`setup()`函数中直接使用,上手无压力
2. **类型安全全覆盖**:完全基于 TypeScript 开发,自带精准类型提示,开发时少踩坑、少查错
3. **模块化按需引入**:支持 Tree-Shaking,只导入用到的函数,不增加项目打包体积
4. **跨平台多环境**:兼容浏览器 / Node.js,支持 SSR 服务端渲染,还能通过 CDN 快速引入
5. **细节拉满**:自动处理 Vue3 生命周期,比如定时器清理、事件监听器移除,从根源避免内存泄漏
6. **中文生态友好**:拥有详尽的官方中文文档,每个函数都有交互式演示,学习成本极低
## 🔧 快速上手:三步搞定 VueUse
VueUse 的使用方式极其简单,核心包轻量且无冗余依赖,全程无需复杂配置,新手也能一键上手。
### 第一步:安装核心包
VueUse 包含一个核心包`@vueuse/core`和多个扩展包(如动画`@vueuse/motion`、组件`@vueuse/components`),日常开发安装核心包即可:
```
# npm
npm install @vueuse/core
# pnpm
pnpm install @vueuse/core
# yarn
yarn add @vueuse/core
```
### 第二步:基础使用示例
在 Vue3 组件的`</code><span leaf="">块或</span><code style="color: rgb(14, 138, 235);font-size: 14px;line-height: 1.8em;letter-spacing: 0em;background-attachment: scroll;background-clip: border-box;background-color: rgba(27, 31, 35, 0.05);background-image: none;background-origin: padding-box;background-position-x: 0%;background-position-y: 0%;background-repeat: no-repeat;background-size: auto;width: auto;height: auto;margin-top: 0px;margin-bottom: 0px;margin-left: 2px;margin-right: 2px;padding-top: 2px;padding-bottom: 2px;padding-left: 4px;padding-right: 4px;border-top-style: none;border-bottom-style: none;border-left-style: none;border-right-style: none;border-top-width: 3px;border-bottom-width: 3px;border-left-width: 3px;border-right-width: 3px;border-top-color: rgb(0, 0, 0);border-bottom-color: rgba(0, 0, 0, 0.4);border-left-color: rgba(0, 0, 0, 0.4);border-right-color: rgba(0, 0, 0, 0.4);border-top-left-radius: 4px;border-top-right-radius: 4px;border-bottom-right-radius: 4px;border-bottom-left-radius: 4px;overflow-wrap: break-word;font-family: 'Operator Mono', Consolas, Monaco, Menlo, monospace;word-break: break-all;">setup()</code><span leaf="">函数中,直接导入所需函数即可使用,所有函数返回的都是响应式对象,无需手动封装</span><code style="color: rgb(14, 138, 235);font-size: 14px;line-height: 1.8em;letter-spacing: 0em;background-attachment: scroll;background-clip: border-box;background-color: rgba(27, 31, 35, 0.05);background-image: none;background-origin: padding-box;background-position-x: 0%;background-position-y: 0%;background-repeat: no-repeat;background-size: auto;width: auto;height: auto;margin-top: 0px;margin-bottom: 0px;margin-left: 2px;margin-right: 2px;padding-top: 2px;padding-bottom: 2px;padding-left: 4px;padding-right: 4px;border-top-style: none;border-bottom-style: none;border-left-style: none;border-right-style: none;border-top-width: 3px;border-bottom-width: 3px;border-left-width: 3px;border-right-width: 3px;border-top-color: rgb(0, 0, 0);border-bottom-color: rgba(0, 0, 0, 0.4);border-left-color: rgba(0, 0, 0, 0.4);border-right-color: rgba(0, 0, 0, 0.4);border-top-left-radius: 4px;border-top-right-radius: 4px;border-bottom-right-radius: 4px;border-bottom-left-radius: 4px;overflow-wrap: break-word;font-family: 'Operator Mono', Consolas, Monaco, Menlo, monospace;word-break: break-all;">ref</code><span leaf="">/</span><code style="color: rgb(14, 138, 235);font-size: 14px;line-height: 1.8em;letter-spacing: 0em;background-attachment: scroll;background-clip: border-box;background-color: rgba(27, 31, 35, 0.05);background-image: none;background-origin: padding-box;background-position-x: 0%;background-position-y: 0%;background-repeat: no-repeat;background-size: auto;width: auto;height: auto;margin-top: 0px;margin-bottom: 0px;margin-left: 2px;margin-right: 2px;padding-top: 2px;padding-bottom: 2px;padding-left: 4px;padding-right: 4px;border-top-style: none;border-bottom-style: none;border-left-style: none;border-right-style: none;border-top-width: 3px;border-bottom-width: 3px;border-left-width: 3px;border-right-width: 3px;border-top-color: rgb(0, 0, 0);border-bottom-color: rgba(0, 0, 0, 0.4);border-left-color: rgba(0, 0, 0, 0.4);border-right-color: rgba(0, 0, 0, 0.4);border-top-left-radius: 4px;border-top-right-radius: 4px;border-bottom-right-radius: 4px;border-bottom-left-radius: 4px;overflow-wrap: break-word;font-family: 'Operator Mono', Consolas, Monaco, Menlo, monospace;word-break: break-all;">computed</code><span leaf="">。</span></p><h4 data-tool="mdnice编辑器" style="margin-top: 30px;margin-bottom: 15px;margin-left: 0px;margin-right: 0px;padding-top: 0px;padding-bottom: 0px;padding-left: 0px;padding-right: 0px;display: block;"><span style="display: none;"></span><span style="font-size: 18px;color: rgb(0, 0, 0);line-height: 1.5em;letter-spacing: 0em;text-align: left;font-weight: bold;display: block;"><span leaf="">示例 1:一行代码监听鼠标位置</span></span><span style="display: none;"></span></h4><pre data-tool="mdnice编辑器" style="border-radius: 5px;box-shadow: rgba(0, 0, 0, 0.55) 0px 2px 10px;text-align: left;margin-top: 10px;margin-bottom: 10px;margin-left: 0px;margin-right: 0px;padding-top: 0px;padding-bottom: 0px;padding-left: 0px;padding-right: 0px;"><code><script setup> import { useMouse } from '@vueuse/core' // 直接获取响应式的鼠标x、y坐标,自动监听/销毁事件 const { x, y } = useMouse()`
**原生实现对比**:如果手写需要手动绑定`mousemove`事件,还要在`onUnmounted`中销毁,足足需要 8 行代码,而 VueUse 只需 1 行搞定!
#### 示例 2:响应式同步本地存储
开发中最常用的本地存储,VueUse 帮你处理了`JSON.parse/stringify`和数据同步,修改值自动更新 localStorage,页面刷新数据不丢失:
```
import { useLocalStorage } from '@vueuse/core'
// 第一个参数为localStorage键名,第二个为默认值
const username = useLocalStorage('my-username', 'VueUse开发者')
```
## 🗺️ 核心功能分类:按需选用,抄作业即用
VueUse 的 200 + 函数覆盖了开发全场景,按功能划分为 7 大类,每类都有高频实用的 API,以下是核心分类及典型使用场景,直接按需取用即可:
表格
|分类|高频组合式函数|典型使用场景|
| -----------------------| ----------------| ---------------------------------------------------------------|
|State(状态)|`useToggle`、`useCounter`、`useDark`|布尔值切换(弹窗 / 菜单)、数字计数(商品数量)、暗黑模式切换|
|Elements(DOM 元素)|`useElementVisibility`、`useIntersectionObserver`|检测元素是否可见、图片懒加载、滚动加载更多|
|Sensors(传感器)|`useMouse`、`useWindowScroll`、`useGeolocation`|鼠标 / 滚动条监听、获取地理位置、窗口大小响应式|
|Time(时间)|`useTimeout`、`useInterval`、`useDateFormat`|定时器管理、倒计时、响应式日期格式化|
|Utilities(工具)|`useDebounceFn`、`pausableWatch`、`createEventHook`|函数防抖节流、可暂停的监听、自定义事件钩子|
|Browser(浏览器 API)|`useLocalStorage`、`useClipboard`、`useFetch`|本地存储、一键复制、响应式网络请求|
|Animation(动画)|`useTransition`、`useMotion`|数值过渡动画、元素动效控制|
### 高频 API 小实战:抄作业就能用
给大家整理了 3 个开发中最常用的 API 实战示例,直接复制到项目中就能运行:
1. **`useClipboard`****一键复制**:无需手动处理剪贴板 API 兼容,自带复制状态反馈
```
import { useClipboard } from '@vueuse/core'
const { copy, copied } = useClipboard()
```
2. **`useIntersectionObserver`****图片懒加载**:元素进入视口才加载,提升页面性能
```
import { ref } from 'vue'
import { useIntersectionObserver } from '@vueuse/core'
const imgRef = ref(null)
const isShow = ref(false)
// 元素进入视口,修改isShow为true
useIntersectionObserver(imgRef, ([{ isIntersecting }]) => {
isShow.value = isIntersecting
})
```
3. **`useToggle`****暗黑模式切换**:一行代码实现布尔值切换,语义清晰更易读
```
import { useDark, useToggle } from '@vueuse/core'
const isDark = useDark() // 自动检测系统暗黑模式
const toggleDark = useToggle(isDark) // 切换暗黑模式函数
```
## ✨ VueUse 的核心优势:为什么值得全员使用?
很多开发者以为 VueUse 只是 “少写几行代码”,但其实它的价值远不止于此,更是团队开发的**代码标准化工具**,能从根本上提升开发效率和代码质量。
### 1\. 极致开发效率,告别重复造轮子
开发中 80% 的基础功能,VueUse 都已封装完成,比如复制、防抖、本地存储,你无需再手动封装工具函数,一行导入语句就能解决,把时间花在核心业务逻辑上。
### 2\. 完美响应式封装,适配 Vue3 生态
VueUse 的函数返回的都是`ref`/`computed`响应式对象,和 Vue3 原生语法无缝衔接,窗口大小、鼠标位置等变化会自动更新,组件也会随之重渲染,无需手动监听事件。
### 3\. 从根源避免 bug,代码更健壮
VueUse 内部处理了所有浏览器 API 的兼容性问题,还会自动适配 Vue3 的生命周期:组件销毁时,自动清理定时器、移除事件监听器,从根源避免内存泄漏,比手写代码更可靠。
### 4\. 模块化设计,项目体积无负担
支持按需引入,你只需要导入实际使用的函数,打包工具会自动剔除未使用的代码,保证项目体积最小化,即使引入整个核心包,体积也仅有几十 KB,对项目毫无影响。
### 5\. 活跃的社区与完善的文档
VueUse 拥有全球活跃的开发社区,持续更新新的函数和功能,官方提供**中文 + 英文**双文档,每个函数都有**交互式演示**,可以在线修改参数查看效果,学习和调试都极其方便。
## 📌 开发小技巧:用好 VueUse 的 3 个关键点
1. **按需引入是标配**:即使 VueUse 支持全局引入,也建议按需导入,比如`import { useMouse } from '@vueuse/core'`,减少打包体积
2. **善用官方交互式演示**:每个函数的文档页都有在线演示,开发前先在线调试参数,再复制代码到项目中,大幅减少试错时间
3. **搭配 Vue 生态使用**:VueUse 可无缝搭配 Vue Router、Pinia、Element Plus 等 Vue 生态插件,比如用`useRoute`结合`useFetch`实现路由联动请求
## 🎯 写在最后
VueUse 从来都不是 “花里胡哨” 的工具,而是 Vue3 开发的**刚需标配**,它把前端开发中所有 “常用但繁琐” 的功能做了极致封装,让开发者不用再关注底层实现,只需专注业务本身。
对于个人开发者,它能让开发效率翻倍,少写 80% 的重复代码;对于团队开发,它能标准化代码逻辑,降低维护成本,让新人快速上手。如果你还在手动封装 Vue3 的基础函数,不妨从今天开始试试 VueUse,它会让你感受到 “开挂式” 的开发体验。
**VueUse 官方中文文档**:https://vueuse.nodejs.cn/
从文档的「快速开始」入手,结合本文的分类和示例,相信你能很快掌握这款神器,让 Vue3 开发更轻松!
---

Original JackChen007 Ai懒人码农
继续滑动看下一个[^29]: # Vue3实现手写签名:Vue3-signature的快速应用
## 来源
[原文链接](https://mp.weixin.qq.com/s?__biz=MzU1NDQ4ODIxMA==&mid=2247485400&idx=1&sn=77c5360676c7e3caad50ae41fc749998&chksm=fa9bc8f4b2c4ebd058bf7e7b6d59d568099fa7cd0431f9f4712d813593c3e677cf19d35055d4&mpshare=1&scene=1&srcid=0214gbUF8Qwlk8eQLM3V3nqI&sharer_shareinfo=9a12a26a4c5cecf0ac678b8958207da4&sharer_shareinfo_first=9a12a26a4c5cecf0ac678b8958207da4#rd)
## 正文
公众号名称:尔嵘
作者名称:尔嵘
发布时间:2026-02-11 01:00
# 一个分享 技术 | 生活 | 社会 | 科技 | 经济 | 情感 的前端爱好者!(联系V: HC106888888)
---
在公务办理、电子合同、在线审批等场景中,手写签名的电子化需求越来越常见。基于 Vue3 开发的 vue3-signature 组件,能快速帮我们实现浏览器端的手写签名功能,无需复杂的 canvas 原生开发,今天就带大家从零掌握这个实用组件的使用。
# 一、什么是 vue3-signature?
vue3-signature是专门适配 Vue3 生态的手写签名组件,底层基于 canvas 实现,支持鼠标、触摸(移动端)手写,提供了签名保存、清空、回退、更换颜色 / 粗细等核心功能,体积轻量、API 简洁,完美兼容 Vue3 的组合式 API 和语法,是 Vue3 项目实现电子签名的首选方案。
# 二、快速上手:5 分钟集成到 Vue3 项目
## 1\. 安装依赖
首先在 Vue3 项目中安装组件(支持 npm/yarn/pnpm):
```
npmnpm install vue3-signature --save# yarnyarn add vue3-signature# pnpmpnpm add vue3-signature
```
## 2\. 基础使用示例
在 Vue3 单文件组件中引入并使用,这是最核心的基础用法:
```
import { ref } from 'vue'
import Vue3Signature from 'vue3-signature'
// 获取组件实例
const signatureRef = ref(null)
// 清空签名
const clearSignature = () => {
signatureRef.value.clear()
}
// 撤销上一步书写
const undoSignature = () => {
// 先判断是否有可撤销的步骤
if (signatureRef.value.canUndo()) {
signatureRef.value.undo()
} else {
alert('已无可撤销的步骤!')
}
}
// 保存签名(支持Base64/Blob格式)
const saveSignature = () => {
// 获取Base64格式的签名图片
const base64 = signatureRef.value.getDataUrl('image/png', 1.0)
// 也可获取Blob格式(适合上传)
// const blob = signatureRef.value.getBlob('image/png', 1.0)
console.log('签名Base64:', base64)
// 可将base64/blob上传到后端,或展示在页面上
}
.signature-container {
width: 500px;
margin: 20px auto;
}
.signature-canvas {
border: 1px solid #e5e5e5;
border-radius: 4px;
}
.signature-btns {
margin-top: 15px;
display: flex;
gap: 10px;
}
.signature-btns button {
padding: 6px 12px;
background: #409eff;
color: #fff;
border: none;
border-radius: 4px;
cursor: pointer;
}
.signature-btns button:hover {
background: #66b1ff;
}
```
下面是签名的效果展示:

# 三、核心配置与常用 API
## 1\. 核心属性(Props)
|属性名|类型|默认值|说明|
| -----------------| ---------| ---------| --------------------------|
|width|Number|400|画布宽度(px)|
|height|Number|200|画布高度(px)|
|penColor|String|#000000|画笔颜色(支持十六进制)|
|penWidth|Number|2|画笔粗细(px)|
|disabled|Boolean|false|是否禁用签名|
|backgroundColor|String|#ffffff|画布背景色|
## 2\. 常用方法(通过 ref 调用)
|方法名|参数说明|功能|
| ---------------------------| --------------------------------------------------------| ----------------------------------|
|clear()|无|清空整个签名画布|
|undo()|无|撤销上一步书写|
|canUndo()|无|判断是否可撤销(返回布尔值)|
|getDataUrl(type, quality)|type:图片格式(如 image/png);quality:清晰度(0-1)|获取签名的 Base64 编码|
|getBlob(type, quality)|同 getDataUrl|获取签名的 Blob 对象(适合上传)|
# 四、实战优化:解决常见问题
## 1\. 适配移动端
vue3-signature天然支持触摸事件,只需保证画布宽度适配移动端:
## 2\. 校验是否签名
提交前判断用户是否完成签名,避免空签名提交:
```
const checkSignature = () => {
// isEmpty() 判断画布是否为空
if (signatureRef.value.isEmpty()) {
alert('请完成手写签名!')
return false
}
return true
}
// 保存前先校验
const saveSignature = () => {
if (!checkSignature()) return
// 后续保存逻辑...
}
```
## 3\. 图片跨域问题
若需在签名画布中插入背景图(如合同模板),需确保图片资源支持跨域,否则会导致getDataUrl/getBlob报错,可要求后端配置跨域头,或使用同域图片。

# 五、总结
- vue3-signature是 Vue3 项目实现电子签名的高效组件,基于 canvas 封装,无需原生 canvas 开发,API 简洁易上手;
- 核心流程:安装 → 引入组件 → 配置基础属性 → 通过 ref 调用方法实现清空、保存、撤销等功能;
- 实际开发中需注意移动端适配、签名非空校验、图片跨域等细节,满足不同场景的签名需求。
组件几乎覆盖了电子签名的所有基础场景,无论是简单的表单签名,还是复杂的合同签署,都能快速落地。赶紧在你的 Vue3 项目中试试吧!更多参考地址:https://www.npmjs.com/package/vue3-signature
---

Original 尔嵘 尔嵘
继续滑动看下一个

尔嵘
向上滑动看下一个[^30]: # 【软件推荐】开源 Web 现代富文本编辑器——支持富文本、块、markdown 编辑,高效且开箱即用
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260214154545-nazrbwa)
## 正文
公众号名称:鹏魔王
作者名称:鹏魔王
发布时间:2025-12-30 08:00
**我能为你提供什么服务?**
**网站建设 | 小程序开发 | 软件定制**
我是鹏魔王,一个做网站、小程序的程序员,记录生活日常、及技术分享。
本欲起身离红尘,奈何影子落人间,欢迎关注,祝大家早日实现财务自由!
什么是 isle-editor?

isle-editor 是一款开源 Web 编辑器,支持富文本、块、markdown 编辑,高效且开箱即用,基于 prosemirror 和 tiptap。
我们希望通过 isle-editor 让开发人员能够轻松地为他们的应用添加文本编辑,相对于市面上的开源编辑器,isle-editor 是 新 的,它除了支持普通的富文本风格外,还支持流行的 Notion Style 风格。
您可以输出 HTML 将它作为一个普通的富文本编辑器,也可以输出 JSON 将它作为一个块编辑器。
考虑到可扩展性,您可以使用我们内置的组合扩展包快速搭建编辑器,也可以选择性使用我们的核心扩展一步一步的定制您的编辑器,同时您还可以自定义扩展丰富编辑器的功能。

Vue3 中使用 isle-editor
```
npm install @isle-editor/core @isle-editor/vue3
# or
yarn add @isle-editor/core @isle-editor/vue3
# or
pnpm add @isle-editor/core @isle-editor/vue3
```
引入样式
```
import "@isle-editor/vue3/dist/style.css";
```
使用组件
```
import { ref } from "vue";
import { IsleEditor, BasicKit } from "@isle-editor/vue3";
const content = ref("");
const extensions = [
BasicKit.configure({
placeholder: {
placeholder: "写点什么...",
},
}),
];
```
详细使用教程自己去看看文档
项目地址:https://editor.islenote.com/zh/
在线演示:https://playground.islenote.com/
---

鹏魔王 鹏魔王
继续滑动看下一个

鹏魔王
向上滑动看下一个[^31]: # 告别死记硬背!HTTP请求方法速查表让你秒懂
## 来源
[原文链接](https://mp.weixin.qq.com/s?t=pages/image_detail&scene=1&__biz=MzYzNTU4NjgxMA==&mid=2247484060&idx=1&sn=8532e9e2b21b5126246e4eea432d34f5&from_masonry=1&sharer_shareinfo_first=8579e66600138a5f48a301619cdde654&sharer_shareinfo=8579e66600138a5f48a301619cdde654#wechat_redirect)
## 正文
公众号名称:阿秋学网安
发布时间:2026-02-10 18:08
还在混淆 GET 和 POST?这张图把 9 种 HTTP 请求方法一网打尽,从用途、示例到响应状态一目了然,后端开发不再踩坑!#高效学习方法分享#程序员成长之路#网络协议入门#代码实战技巧#编程学习笔记
[^32]: # vue-qqmap:Vue 项目中快速集成腾讯地图的实用插件
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260215154233-9zad148)
## 正文
公众号名称:尔嵘
作者名称:尔嵘
发布时间:2026-02-06 08:12
你想要了解vue-qqmap这个插件的核心信息,我会用简短且准确的内容,从插件定位、使用方式、核心价值三个维度介绍它,方便你快速掌握这个插件的核心用法和优势。
# 一、插件核心定位
vue-qqmap是专为 Vue.js(支持 Vue 2/3)开发的腾讯地图(QQ 地图)SDK 封装插件,它简化了原生腾讯地图 API 在 Vue 项目中的集成流程,无需手动引入地图 JS 文件、处理异步加载等问题,让前端开发者能以 Vue 组件 / 指令的形式快速调用腾讯地图的定位、逆地理编码、地址解析等核心能力。
# 二、快速使用步骤
## 1\. 安装插件
通过 npm 一键安装,这是你提到的核心命令:
```
npm install vue-qqmap --save
或 yarn/pnpmyarn add vue-qqmappnpm add vue-qqmap
```
申请key: https://lbs.qq.com/
## 2\. 全局注册(Vue 2 示例)
```
// main.ts
import { createApp } from 'vue'
import App from './App.vue'
import VueQqmap from 'vue-qqmap' // 统一命名,避免混淆
const app = createApp(App)
// 全局注册:传入腾讯地图开发者Key(无需在组件内重复写key)
app.use(VueQqmap, {
key: '你的腾讯地图Key' // 替换成你在腾讯地图开放平台申请的key
})
app.mount('#app')
```
## 3\. 组件内使用(核心功能示例)
以 “逆地理编码(根据经纬度获取地址)” 为例,直接通过this.$qqmap调用 API:
```
import { defineComponent, reactive } from 'vue'
// 响应式数据:存储经纬度、地址
const location = reactive({
lat: '', // 纬度
lng: '', // 经度
address: '' // 详细地址
})
// 地图选择/地址变化的回调函数(核心:接收插件返回的完整数据)
function mapChange(data: any) {
console.log('地图选择回调数据:', data)
// data 包含完整的地址、经纬度、省市区等信息,可按需解构
// 示例:手动解构赋值(插件已做双向绑定,此步骤可选)
// const { lat, lng, address } = data
// location.lat = lat
// location.lng = lng
// location.address = address
}
export default defineComponent({
setup() {
return { location, mapChange }
}
})
```
## 4.回调数据:
```
{
address: "北京市东城区天安门广场", // 完整地址
lat: 39.908823, // 纬度
lng: 116.397470, // 经度
province: "北京市", // 省
city: "北京市", // 市
district: "东城区" // 区/县
}
```
# 
# 三、核心优势与注意事项
轻量化封装:仅对腾讯地图核心 API 做 Vue 适配,无冗余代码,不增加项目体积;
API 全覆盖:支持地址解析、逆地理编码、定位、距离计算等腾讯地图核心接口;
必备前提:使用前需在腾讯地图开放平台申请开发者密钥(key),且需配置合法的域名白名单,否则接口调用会失败;
版本兼容:Vue 3 项目使用时需注意插件版本,建议安装最新版以适配 Vue 3 的 Composition API。
# 总结
vue-qqmap是 Vue 项目集成腾讯地图的便捷工具,核心作用是简化原生 API 的调用流程;
使用前需安装插件并配置腾讯地图开发者 key,核心功能可过this.$qqmap直接调用;
该插件轻量化且覆盖腾讯地图核心 API,是 Vue 项目实现地图相关功能的高效选择。
---

原创 尔嵘 尔嵘
继续滑动看下一个

尔嵘
向上滑动看下一个[^33]: # 给 Vue3 项目添点 “情绪”!vue3-emoji-picker 优雅实现表情包选择器
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260215154234-c61iyk7)
## 正文
公众号名称:尔嵘
作者名称:尔嵘
发布时间:2026-02-12 00:03
# 一个分享 技术 | 生活 | 社会 | 科技 | 经济 | 情感 的前端爱好者!(联系V: HC106888888)
---
在社交聊天、评论互动、内容编辑等场景中,表情包(Emoji)是提升用户体验的重要元素。基于 Vue3 生态的vue3-emoji-picker组件,能让我们无需从零开发,快速集成高颜值、功能完善的表情包选择器,今天就带大家玩转这个实用组件。
# 一、什么是 vue3-emoji-picker?
vue3-emoji-picker是专为 Vue3 设计的轻量级表情包选择组件,支持 Vue3 的组合式 API 和语法,具备以下核心特性:
# 二、快速上手:3 分钟集成到 Vue3 项目
## 1\. 安装依赖
支持 npm/yarn/pnpm 三种包管理工具,任选其一即可:
```
npmnpm install vue3-emoji-picker --save# yarnyarn add vue3-emoji-picker# pnpmpnpm add vue3-emoji-picker
```
## 2\. 基础使用示例
这是最核心的基础用法,实现 “点击按钮弹出表情包选择器,选择后插入输入框” 的经典场景:
```
import { ref } from 'vue'
import Vue3EmojiPicker from 'vue3-emoji-picker'
// 引入组件样式(必须)
import 'vue3-emoji-picker/css'
// 输入框内容
const inputValue = ref('')
// 是否显示表情包选择器
const showEmojiPicker = ref(false)
// 切换表情包选择器显示/隐藏
const toggleEmojiPicker = () => {
showEmojiPicker.value = !showEmojiPicker.value
}
// 选中表情包后的回调
const onEmojiSelect = (emoji) => {
// emoji对象包含 emoji(表情符号)、label(名称)、category(分类)等属性
inputValue.value += emoji.emoji
// 可选:选择后自动关闭选择器
showEmojiPicker.value = false
}
.emoji-demo {
width: 500px;
margin: 50px auto;
}
.input-group {
display: flex;
align-items: center;
gap: 8px;
}
.input {
flex: 1;
padding: 10px;
border: 1px solid #e5e5e5;
border-radius: 4px;
font-size: 14px;
}
.emoji-btn {
padding: 10px 16px;
border: 1px solid #e5e5e5;
border-radius: 4px;
background: #f5f5f5;
cursor: pointer;
font-size: 16px;
}
.emoji-picker {
margin-top: 8px;
z-index: 100;
}
.preview {
margin-top: 20px;
font-size: 14px;
}
.preview-content {
color: #409eff;
margin-left: 8px;
}
```
# 三、核心配置与常用 API
## 1\. 核心属性(Props)
|属性名|类型|默认值|说明|
| --------------| ---------| ---------------------------------------------------------------------------------------------------------| ---------------------------------------------------------------------------------------|
|position|String|bottom-start|选择器弹出位置,可选:top/top-start/top-end/bottom/bottom-start/bottom-end/left/right|
|categories|Array|\['smileys', 'people', 'animals', 'food', 'activities', 'travel', 'objects', 'symbols', 'flags'\]|显示的表情包分类,可自定义筛选|
|showSearch|Boolean|true|是否显示搜索框|
|showRecents|Boolean|true|是否显示 “最近使用” 分类|
|recentCount|Number|12|“最近使用” 分类显示的表情包数量|
|customEmojis|Array|\[\]|自定义表情包列表(格式见下文)|
## 2\. 核心事件(Events)
|事件名|回调参数|说明|
| --------| ---------------| ----------------------------------|
|select|emoji: Object|选中表情包时触发,返回表情包对象|
|close|\-|选择器关闭时触发|
|search|query: String|搜索表情包时触发,返回搜索关键词|
# 四、进阶用法:自定义表情包
如果内置表情包满足不了需求,可通过customEmojis属性添加自定义表情包(支持图片 / 自定义符号):
```
// 自定义表情包列表
const customEmojis = ref([
{
emoji: '🐶', // 表情符号/图片地址
label: '小狗', // 名称
category: 'custom', // 分类(固定为custom)
keywords: ['狗', '宠物'] // 搜索关键词
},
{
emoji: 'https://xxx.com/custom-emoji.png', // 自定义图片表情包
label: '自定义图片',
category: 'custom',
keywords: ['自定义', '图片']
}
])
const onEmojiSelect = (emoji) => {
console.log('选中自定义表情包:', emoji)
}
```
# 五、实战优化:解决常见问题
## 1\. 适配移动端
vue3-emoji-picker天然适配移动端,只需调整选择器宽度即可:
## 2\. 自定义样式
组件支持通过 CSS 覆盖默认样式,比如修改选择器背景、字体大小:
```
/* 覆盖选择器整体样式 */
:deep(.emoji-picker) {
background: #f8f8f8 !important;
border-radius: 8px !important;
}
/* 覆盖表情包项样式 */
:deep(.emoji-item) {
font-size: 20px !important;
}
```
## 3\. 限制表情包输入数量
在评论、聊天场景中,可限制表情包的输入数量:
```
const onEmojiSelect = (emoji) => {
// 统计已输入的表情包数量
const emojiReg = /[\u{1F600}-\u{1F64F}\u{1F300}-\u{1F5FF}\u{1F680}-\u{1F6FF}\u{1F1E0}-\u{1F1FF}]/gu;
const emojiCount = (inputValue.value.match(emojiReg) || []).length;
if (emojiCount >= 5) {
alert('最多只能输入5个表情包哦!');
return;
}
inputValue.value += emoji.emoji;
}
```
# 
# 六、总结
1. vue3-emoji-picker是 Vue3 项目集成表情包选择器的最优解之一,开箱即用,无需复杂开发;
2. 核心流程:安装 → 引入组件 + 样式 → 配置基础属性 → 通过 select 事件处理选中的表情包;
3. 支持自定义表情包、自定义样式、移动端适配等进阶能力,能满足社交、评论等多场景需求。
无论是简单的评论框加表情包,还是复杂的聊天系统,vue3-emoji-picker 都能快速落地,让你的项目交互更生动!
---

Original 尔嵘 尔嵘
继续滑动看下一个

尔嵘
向上滑动看下一个[^34]: # vue-ai-migrator:AI赋能,解锁Vue项目迁移新效率
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260216170130-oltethr)
## 正文
公众号名称:尔嵘
作者名称:尔嵘
发布时间:2026-02-14 01:02
# 一个分享 技术 | 生活 | 社会 | 科技 | 经济 | 情感 的前端爱好者!(联系V: HC106888888)
---
在Vue生态迭代加速的当下,不少开发者正面临一个共性难题:老旧Vue项目(Vue 2.x)升级迁移、跨版本适配,或是Vue项目向其他前端框架迁移时,繁琐的代码改写、兼容性调试、逻辑校验,不仅耗时费力,还容易出现遗漏和报错,成为项目迭代路上的“绊脚石”。而vue-ai-migrator的出现,正是为了破解这一痛点——一款以AI为核心驱动力的Vue项目迁移工具,让原本需要数天甚至数周的迁移工作,变得高效、精准、省心。
不同于传统的手动迁移或简单的代码转换工具,vue-ai-migrator的核心亮点的在于“AI智能赋能”,它深度融合了Vue生态的最佳实践与AI的自动分析、生成能力,并非单纯的代码替换,而是能实现“理解逻辑、适配场景、优化代码”的全流程智能化迁移,彻底摆脱了“机械转换+手动补漏”的低效模式,让开发者从繁琐的重复劳动中解放出来,聚焦核心业务逻辑的优化。
聊起vue-ai-migrator的核心能力,最让开发者惊喜的,莫过于它的「全场景适配+精准迁移」。无论是最常见的Vue 2.x到Vue 3.x的跨版本迁移,还是Vue项目向Nuxt.js、React等框架的跨框架迁移,它都能无缝适配,覆盖绝大多数开发场景。借助AI的代码解析能力,它能自动识别老旧代码中的废弃API、不兼容语法、全局配置差异,比如Vue 2中的Vue.prototype、filter过滤器、生命周期钩子变更等,无需开发者逐行排查,就能精准定位需要修改的内容,并自动生成符合目标版本/框架规范的代码,迁移准确率高达90%以上,大幅降低人工纠错成本。
举个最常见的Vue 2到Vue 3迁移示例,AI会自动转换核心语法差异:
```
// Vue 2 旧代码(自动识别废弃语法)
Vue.prototype.$http = axios
filters: {
formatTime(time) {
return new Date(time).toLocaleString()
}
}
// vue-ai-migrator 自动生成的 Vue 3 新代码
import { createApp } from 'vue'
const app = createApp(App)
app.config.globalProperties.$http = axios
// 过滤器替换为全局函数(符合Vue 3最佳实践)
app.config.globalProperties.$formatTime = (time) => {
return new Date(time).toLocaleString()
}
```
高效便捷,更是vue-ai-migrator的核心竞争力之一。对于开发者而言,无需掌握复杂的迁移语法规则,也无需熟悉目标版本/框架的所有细节,只需简单配置迁移源(原有项目)和迁移目标(目标版本/框架),vue-ai-migrator就能自动启动AI分析、代码转换、兼容性校验全流程,全程自动化运行,无需人工干预。原本需要3-7天的Vue 2转Vue 3迁移工作,借助它可缩短至数小时,甚至更短时间,大幅提升项目迭代效率,尤其适合中小型项目的快速迁移和大型项目的批量模块迁移。
只需3行核心配置,即可启动全自动化迁移:
```
// vue-ai-migrator 核心配置示例(极简上手)
const migrator = require('vue-ai-migrator')
// 配置迁移源、目标版本,启动迁移
migrator.start({
source: './src', // 原有Vue 2项目源码目录
target: 'vue3', // 迁移目标(vue3/nuxt/react可选)
output: './dist-vue3' // 迁移后代码输出目录
})
```
更值得一提的是,它的「AI智能优化」能力,让迁移不仅是“完成转换”,更是“优化升级”。在迁移过程中,AI会结合Vue生态的最佳实践,自动优化代码结构,剔除冗余代码,规范代码格式,甚至能识别可复用逻辑,进行组件化重构;同时,针对迁移后的代码,它会自动进行兼容性校验和报错提示,生成详细的迁移报告,标注未自动处理的细节的和需要手动微调的部分,既保证了迁移质量,也降低了开发者的后续调试成本——这也是它区别于普通代码转换工具的核心优势,真正实现了“迁移即优化”。
对于不同需求的开发者,vue-ai-migrator都能给出贴合场景的解决方案,门槛极低,上手即用。如果你是前端新手,面对Vue版本迁移无从下手,无需担心,它的自动化流程和详细报告,能让你轻松完成迁移工作,同时还能通过迁移报告学习Vue新版本的语法差异和最佳实践;如果你是资深开发者,它能帮你省去繁琐的重复编码和排查工作,让你更专注于项目架构优化、性能提升等更有价值的事情,尤其适合多项目、多模块的批量迁移场景,大幅提升团队开发效率。
在实际应用场景中,vue-ai-migrator的优势更是展现得淋漓尽致。比如企业内部的老旧Vue 2项目,需要升级到Vue 3以适配新的业务需求和依赖包,借助vue-ai-migrator,无需组建专门的迁移团队,单个开发者就能快速完成迁移,同时完成代码优化,缩短项目迭代周期;再比如前端团队需要将Vue项目迁移到Nuxt.js以实现更好的SSR渲染效果,它能自动适配Nuxt.js的目录结构、路由配置和生命周期,避免手动改写带来的逻辑错乱;还有开源项目的版本迭代,借助它能快速完成跨版本迁移,减少维护成本,提升项目活跃度。
相较于市面上其他同类迁移工具,vue-ai-migrator的核心竞争力,在于它“AI驱动+生态深度融合”的产品逻辑。它不是一款孤立的代码转换工具,而是深度贴合Vue生态的迁移解决方案,能精准识别Vue项目的核心逻辑、组件依赖、路由配置,甚至能适配第三方Vue组件库(如Element UI、Ant Design Vue)的跨版本迁移,避免出现“迁移后组件失效、样式错乱”的问题;同时,它的AI模型会持续迭代,紧跟Vue生态的更新节奏,及时适配新的语法、新的API,保证迁移的兼容性和时效性。
第三方组件库迁移示例(Element UI → Element Plus):
```
// Vue 2 + Element UI 旧代码
import { Button } from 'element-ui'
Vue.use(Button)
// vue-ai-migrator 自动生成 Vue 3 + Element Plus 代码
import { ElButton } from 'element-plus'
import 'element-plus/dist/index.css'
export default {
components: { ElButton }
}
```
随着Vue 3的普及和前端生态的不断发展,项目迁移、版本升级将成为开发者的常态化工作,而“高效、精准、省心”的迁移工具,无疑会成为开发者的必备利器。vue-ai-migrator始终立足开发者需求,以AI赋能简化迁移流程,以生态适配提升迁移质量,以极简操作降低使用门槛,打破了传统迁移模式的局限,重新定义了Vue项目迁移的效率与体验。
如果你还在为Vue项目迁移的繁琐工作而困扰,还在为跨版本适配、代码报错而头疼,不妨试试vue-ai-migrator——AI智能驱动,全程自动化迁移,精准适配多场景,让项目迁移不再费力,让你把更多时间和精力,投入到更有价值的核心业务开发中,轻松解锁Vue项目迭代的新可能。
未来,vue-ai-migrator也将持续迭代升级,结合开发者的实际迁移需求,新增更多适配场景,优化AI识别精度和代码生成质量,完善迁移报告和调试辅助功能,同时拓展更多跨框架迁移能力,努力成为每一位Vue开发者的“项目迁移好帮手”,陪伴大家高效完成每一次项目迭代,解锁前端开发的新效率。
---

原创 尔嵘 尔嵘
继续滑动看下一个

尔嵘
向上滑动看下一个[^35]: # Vue3 实用 npm 库:VueRouter 4 快速入门
## 1. 简介
VueRouter 4 是 Vue3 官方专属的路由管理器,也是 Vue 生态核心库之一。它专为 Composition API 设计,实现了单页应用(SPA)的路由跳转、组件按需渲染、路由守卫等核心功能,是 Vue3 项目实现页面导航的必备库。
## 2. 核心亮点
- **官方维护**:与 Vue3 深度兼容,支持 `<script setup>` 语法;
- **性能优化**:体积轻量化,路由匹配速度更快;
- **API 设计**:完全适配 Composition API,提供组合式路由钩子;
- **功能全面**:支持路由懒加载、嵌套路由、动态路由、路由守卫;
- **开发体验**:TypeScript 支持完善,开发时智能提示友好。
## 3. 快速安装
适配 Vue3 的版本为 VueRouter 4,请根据包管理器执行以下命令:
```bash
# npm
npm install vue-router@4 -S
# yarn
yarn add vue-router@4
# pnpm
pnpm add vue-router@4
```
## 4. 核心使用步骤
### 4.1 定义路由组件
创建两个基础页面作为示例:
```xml
<!-- src/views/Index.vue (首页) -->
<template>
<div>
<h1>首页</h1>
<p>VueRouter 4 基础演示</p>
</div>
</template>
<!-- src/views/About.vue (关于页) -->
<template>
<div>
<h1>关于我们</h1>
<p>这是 Vue3 + VueRouter 4 的路由示例</p>
</div>
</template>
```
### 4.2 配置路由并全局注册
在 `src/router/index.js` 中进行配置(已包含懒加载优化):
```javascript
import { createRouter, createWebHistory } from 'vue-router'
// 导入路由组件(支持懒加载,优化首屏加载速度)
const Index = () => import('@/views/Index.vue')
const About = () => import('@/views/About.vue')
// 路由规则配置
const routes = [
{
path: '/', // 路由路径
name: 'Index', // 路由名称(可选)
component: Index // 对应组件
},
{
path: '/about',
name: 'About',
component: About
}
]
// 创建路由实例
const router = createRouter({
history: createWebHistory(), // 历史模式(无#号,推荐)
routes // 注入路由规则
})
export default router
```
### 4.3 入口文件挂载
在 `src/main.js/ts` 中挂载路由:
```javascript
import { createApp } from 'vue'
import App from './App.vue'
import router from './router' // 导入路由实例
const app = createApp(App)
app.use(router) // 全局挂载路由
app.mount('#app')
```
### 4.4 组件中使用路由
在 `src/App.vue` 中使用核心标签和组合式 API:
```html
<template>
<div class="app">
<!-- 路由导航链接:替代a标签,无刷新跳转 -->
<nav>
<router-link to="/">首页</router-link>
<router-link to="/about">关于我们</router-link>
</nav>
<!-- 路由出口:匹配的路由组件会渲染到这里 -->
<router-view></router-view>
</div>
</template>
<script setup>
import { useRouter, useRoute } from 'vue-router'
// 路由实例:用于编程式导航
const router = useRouter()
// 路由信息:用于获取当前路由参数、路径等
const route = useRoute()
// 编程式跳转示例(可在按钮点击等事件中调用)
const toAbout = () => {
router.push('/about') // 路径跳转
// 也可通过名称跳转:router.push({ name: 'About' })
}
</script>
<style scoped>
nav { margin: 20px 0; }
router-link { margin-right: 20px; font-size: 16px; color: #333; text-decoration: none; }
router-link.active { color: #42b983; font-weight: bold; }
</style>
```
## 5. 高频实用功能
### 5.1 路由懒加载
通过箭头函数 `() => import('@/views/Index.vue')` 导入组件,实现组件按需加载,仅当访问对应路由时才加载代码,优化首屏性能。
### 5.2 动态路由参数
配置带参数的路由,通过 `useRoute` 获取参数:
```javascript
// 路由规则添加
{ path: '/user/:id', component: () => import('@/views/User.vue') }
// 组件中获取参数
const route = useRoute()
console.log(route.params.id) // 获取动态参数id
```
### 5.3 全局路由守卫(鉴权/拦截)
在 `src/router/index.js` 中配置,实现全局路由跳转拦截(如登录鉴权):
```javascript
// 全局前置守卫:路由跳转前执行
router.beforeEach((to, from, next) => {
// 示例:判断是否需要登录
const isLogin = localStorage.getItem('token')
if (to.path === '/user' && !isLogin) {
next('/') // 未登录跳转到首页
} else {
next() // 正常放行
}
})
```
## 6. 核心注意点
> [!Warning] 版本兼容
> Vue3 必须使用 **VueRouter 4.x** 版本,3.x 版本仅支持 Vue2。
>
> [!Tip] 路由模式选择
> - `createWebHistory()`:HTML5 历史模式(无 `#` 号,URL 美观),需后端配置重定向;
> - `createWebHashHistory()`:哈希模式(带 `#` 号),无需后端配置即可使用。
>
1. **样式高亮**:`<router-link>` 会自动添加激活类 `router-link-active`,可直接设置 CSS 样式实现导航高亮;
2. **组合式 API 限制**:必须在 `<script setup>` 或 `setup()` 函数顶层中使用 `useRouter` / `useRoute`,无法在普通函数(如定时器回调)中直接调用。
## 7. 总结
VueRouter 4 是 Vue3 单页应用的**官方路由标准**,上手简单、功能完善。核心只需完成「配置路由规则 → 全局挂载 → 组件中使用导航/出口」三步即可实现基础路由功能。其支持的懒加载、动态路由、路由守卫等特性,能满足从简单到复杂的项目导航需求,是 Vue3 生态中不可或缺的核心库。
[^36]: # 免费 Websocket 服务器
---
id: 20260221092307-nzbpm64
title: 免费 Websocket 服务器
---
## 元信息
- **来源**:[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260221092305-egt7p5n)
- **公众号**:胡言乱码
- **作者**:dubox
- **发布时间**:2026-02-12
---
## 前言
之前发过一篇[【免费】终于白嫖到支持 websocket 的云服务了!](/uploads/shares/4/assets/笔记同步助手/attachments/【免费】终于白嫖到支持websocket的云服务了!-20260221092305-oap674h),但是 Render 家的有个缺点:一段时间不访问服务会进入睡眠,再访问冷启动时间比较久,免费额度也少。
最近搞一个联机小游戏,发现 **CloudFlare 通过 Worker + DurableObjects** 也可以实现 WebSocket 服务,而且效果不错:
- 额度高
- 国内访问友好
- 适合做轻量游戏服务端或实时消息推送
> [!Tip] 方案对比
> DurableObjects 相比传统 Serverless WebSocket 方案的优势在于支持状态保持和 WebSocket 休眠/唤醒,适合需要长连接的场景。
>
---
## 搭建步骤
### 1. 创建 CloudFlare 账号
首先需要有一个 [cloudflare.com](https://cloudflare.com) 账号。
### 2. 创建本地 Wrangler 项目
```bash
npm create cloudflare@latest -- ws-test
```
> [!NOTE]
> `ws-test` 是项目名,未来也会作为 Worker 的名称。
>
第一次运行会安装 Wrangler,还有一个登录授权。
按方向键选择,回车确认:


这个根据你的需要,`yes` 会帮你初始化 Git 本地仓库以及创建忽略配置:

### 3. 编辑 `src/index.ts`
将以下代码替换原有代码:
```typescript
import { DurableObject } from 'cloudflare:workers';
// Worker
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
if (request.url.endsWith('/websocket')) {
// 期望收到 WebSocket 升级请求
const upgradeHeader = request.headers.get('Upgrade');
if (!upgradeHeader || upgradeHeader !== 'websocket') {
return new Response('Worker expected Upgrade: websocket', { status: 426 });
}
if (request.method !== 'GET') {
return new Response('Worker expected GET method', { status: 400 });
}
// 所有请求发送到同一个 Durable Object 实例
let stub = env.WEBSOCKET_HIBERNATION_SERVER.getByName("foo");
return stub.fetch(request);
}
return new Response(
`Supported endpoints:\n/websocket: Expects a WebSocket upgrade request`,
{ status: 200, headers: { 'Content-Type': 'text/plain' } }
);
},
};
// Durable Object
export class WebSocketHibernationServer extends DurableObject {
sessions: Map<WebSocket, { id: string }>;
constructor(ctx: DurableObjectState, env: Env) {
super(ctx, env);
this.sessions = new Map();
// 唤醒休眠的 WebSocket 并恢复状态
this.ctx.getWebSockets().forEach((ws) => {
const attachment = ws.deserializeAttachment();
if (attachment) {
this.sessions.set(ws, { ...attachment });
}
});
// 设置自动响应
this.ctx.setWebSocketAutoResponse(new WebSocketRequestResponsePair('ping', 'pong'));
}
async fetch(request: Request): Promise<Response> {
const webSocketPair = new WebSocketPair();
const [client, server] = Object.values(webSocketPair);
this.ctx.acceptWebSocket(server);
const id = crypto.randomUUID();
server.serializeAttachment({ id });
this.sessions.set(server, { id });
return new Response(null, { status: 101, webSocket: client });
}
async webSocketMessage(ws: WebSocket, message: ArrayBuffer | string) {
const session = this.sessions.get(ws)!;
// 回复给发起客户端
ws.send(`[Durable Object] 消息: ${message}, 来自: ${session.id}, 发送给: 发起客户端. 总连接数: ${this.sessions.size}`);
// 广播给所有客户端
this.sessions.forEach((attachment, connectedWs) => {
connectedWs.send(`[Durable Object] 消息: ${message}, 来自: ${session.id}, 发送给: 所有客户端. 总连接数: ${this.sessions.size}`);
});
// 广播给除发起客户端外的所有客户端
this.sessions.forEach((attachment, connectedWs) => {
if (connectedWs !== ws) {
connectedWs.send(`[Durable Object] 消息: ${message}, 来自: ${session.id}, 发送给: 除发起客户端外的所有客户端. 总连接数: ${this.sessions.size}`);
}
});
}
async webSocketClose(ws: WebSocket, code: number, reason: string, wasClean: boolean) {
ws.close(code, reason);
this.sessions.delete(ws);
}
}
```
### 4. 编辑 `wrangler.jsonc`
```jsonc
{
"$schema": "node_modules/wrangler/config-schema.json",
"name": "ws-test",
"main": "src/index.ts",
"compatibility_date": "2026-02-05",
"durable_objects": {
"bindings": [
{
"name": "WEBSOCKET_HIBERNATION_SERVER",
"class_name": "WebSocketHibernationServer"
}
]
},
"migrations": [
{
"tag": "v1",
"new_sqlite_classes": ["WebSocketHibernationServer"]
}
],
"observability": {
"enabled": true
},
"compatibility_flags": ["nodejs_compat"]
}
```
> [!Note] 配置说明
> `WEBSOCKET_HIBERNATION_SERVER` 将作为 Durable Objects 实例的名称。
>
### 5. 本地运行测试
```bash
cd ws-test
npx wrangler dev
```
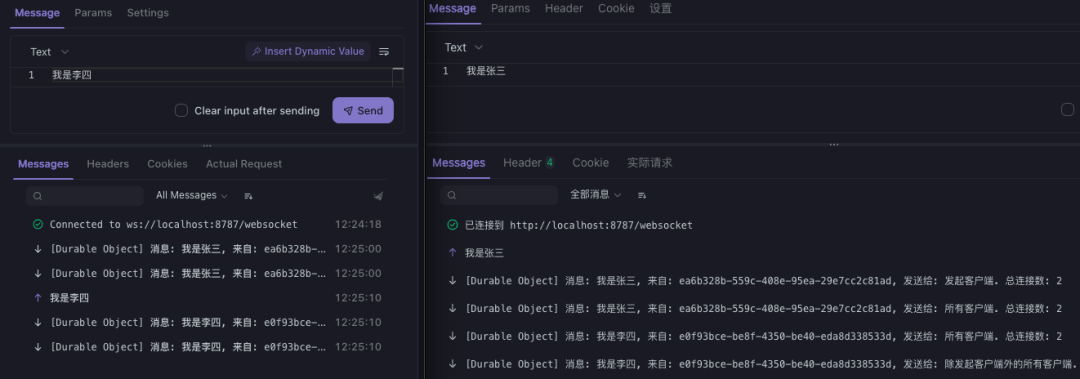
测试成功 ✓
### 6. 发布到 CloudFlare
```bash
npx wrangler deploy
```
发布成功后,在 CloudFlare 控制台会看到:
- 新创建的 Worker
- 新建的 Durable Objects 命名空间
系统会自动完成绑定。
### 7. 绑定域名
CloudFlare 分配的免费域名在国内访问不太友好,最好绑定自己的域名。
> [!Tip] Tip
> 有在 CloudFlare 托管的域名会方便很多。
>
进入 Worker 设置:
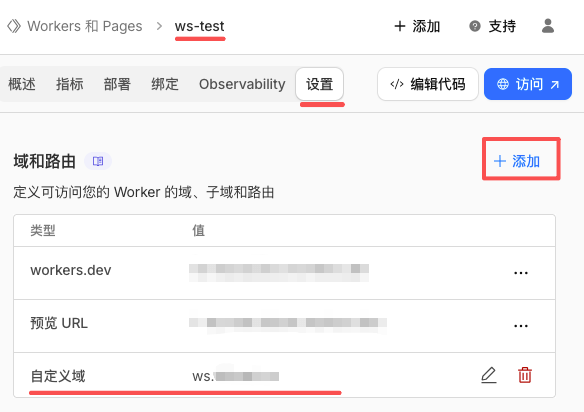
### 8. 测试远程 WebSocket
使用 WebSocket 测试工具连接 `wss://your-worker.your-subdomain.workers.dev/websocket`:
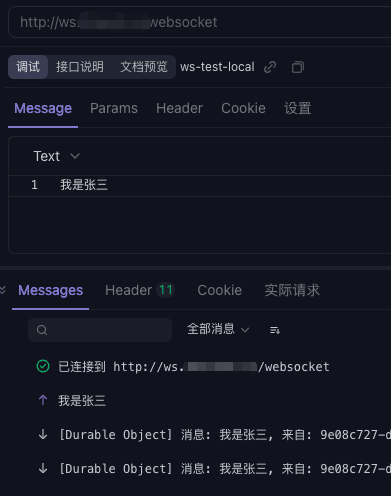
[^37]: # 推荐 4 个神级 SKills 开源 GitHub 项目,非常实用。
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260221092321-9xufv87)
## 正文
公众号名称:逛逛GitHub
作者名称:逛逛
发布时间:2026-02-18 14:46
**
01
**营销人的 Claude Code 技能库**
**
这个是专门为营销同学准备的 skill 包,已经有 7.5k 的 Star 了。
作者是个叫 Corey Haines 的营销大佬,他在 X 上说这是他发布过的最有价值的东西,而且完全免费。

我看了一下,里面包含了 26 个营销相关的 skill,覆盖了转化率优化、文案写作、SEO、数据分析、增长黑客这些领域。
比如说 page-cro 这个 skill:当你想让 Claude 帮你优化落地页的转化率时,会自动应用各种转化率优化的框架和最佳实践。
还有 copywriting skill 可以帮你写各种营销页面的文案,包括首页、落地页、产品页啥的。
对于搞 SEO 的同学,有 seo-audit skill 可以做技术和页面 SEO 审计,programmatic-seo skill 可以帮你规模化生成 SEO 页面。
付费广告这块也有 paid-ads skill,支持 Google Ads、Meta、LinkedIn、Twitter/X 这些平台。
说白了,装上这套 skill 之后,Claude Code 就变成了一个懂营销的 AI 助手,能帮你干各种营销相关的活。
```
开源地址:https://github.com/coreyhaines31/marketingskills
```
**
02
**AI 自动生成 PPT 的王炸工具**
**
这个是 AI 大佬歸藏开源的一个项目,用来自动生成 PPT 的。真的挺强的。
它能智能分析你的文档,自动提取核心要点,规划 PPT 的结构。
然后用 Google 的 Nano Banana Pro 模型生成高质量的 PPT 图片,支持 2K 和 4K 分辨率。
最厉害的是,它还能用可灵 AI 自动生成页面之间的转场视频,让整个 PPT 看起来特别流畅。
内置了两种视觉风格,一种是渐变毛玻璃卡片风格,走的是 Apple Keynote 的极简路线,适合科技产品和商务演示。
另一种是矢量插画风格,温暖扁平化设计,适合教育培训和创意提案。

用起来也很简单,你只需要准备一个内容规划文件,告诉它每页要展示什么内容,然后运行一个命令,它就能帮你把整个 PPT 生成出来。
生成的 PPT 还自带一个交互式播放器,支持键盘控制、循环预览、智能转场,甚至还能导出成完整视频。
对于经常要做 PPT 的同学来说,这个工具能省下不少时间。

```
开源地址:https://github.com/op7418/NanoBanana-PPT-Skills
```
**
03
**自媒体内容创作全家桶**
**
这个是宝玉老师开源的一套 skills,专门用来提升日常工作效率的。
看了一下,里面有很多跟自媒体内容创作相关的工具。
比如说 xhs-images 这个 skill,能把你的内容拆解成 1-10 张小红书风格的卡通信息图,支持 9 种视觉风格和 6 种布局方式。
infographic skill 更强,能生成专业的信息图,内置了 20 种布局类型和 17 种视觉风格,可以根据内容自动推荐合适的组合。
cover-image skill 可以给文章生成封面图,支持 9 种配色方案和 6 种渲染风格,总共有 54 种独特组合。

slide-deck skill 能从文章内容生成专业的幻灯片图片,支持 16 种预设风格,适合不同的使用场景。
还有个 comic skill,能创作知识漫画,支持多种画风和色调组合,可以用来做教育类的内容。
比较实用的是 post-to-wechat skill,能把内容直接发布到微信公众号,支持图文和文章两种模式。
如果你想发 Twitter,也有个 post-to-x skill,支持发布带图片的推文和 X Articles 长文。
这些 skill 对于做自媒体的同学来说,能帮你把从内容创作到发布的整个流程都自动化了,非常方便。
```
开源地址:https://github.com/JimLiu/baoyu-skills
```
**
04
**处理文档 SKill**
**
这个叫 awesome-claude-skills 开源项目已经有 34.9k 的 Star 了,说白了就是各种 Claude Skills 的大合集。

看了一下,里面有很多实用的Skill,特别是文档处理这块做得特别专业。
比如说处理 PDF 文件的 skill,不仅能提取文本和表格,还能读取元数据、合并多个 PDF、甚至能给 PDF 加注释。
处理 Word 文档的 skill 也很强,支持追踪修改、添加评论、格式化,基本上 Word 能干的事它都能干。
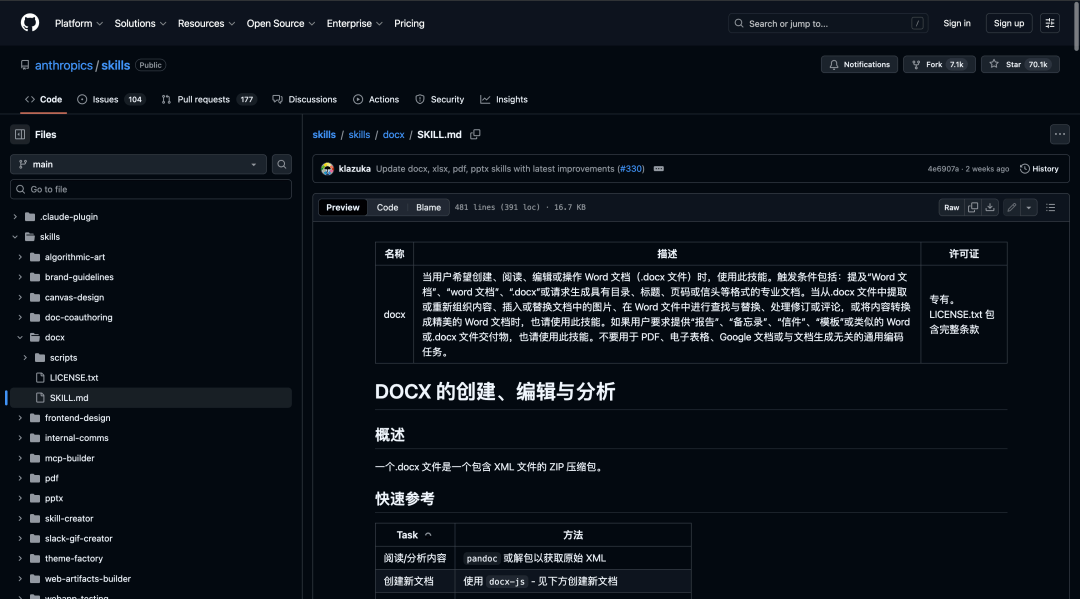
还有处理 Excel 的 skill,可以写公式、生成图表、做数据转换,对于经常要处理表格的同学来说非常方便。
PPT 也有对应的 skill,能读取、生成、调整幻灯片布局和模板。

这些 skill 最大的好处就是,装上之后 Claude 就能按照你的要求,以标准化的方式处理各种文档,不会每次都得重新教它怎么干。
```
开源地址:https://github.com/ComposioHQ/awesome-claude-skills
```
05
**点击下方卡片,关注逛逛 GitHub**
这个公众号历史发布过很多有趣的开源项目,如果你懒得翻文章一个个找,你直接关注微信公众号:逛逛 GitHub ,后台对话聊天就行了:

---

原创 逛逛 逛逛GitHub
继续滑动看下一个

逛逛GitHub
向上滑动看下一个[^38]: # RuoYi 全栈 AI 平台开源了!真香!!
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260224091959-8n6vxzb)
## 正文
公众号名称:JavaGuide
作者名称:Guide
发布时间:2026-02-15 17:45
大家好,我是 Guide。国内开源的 RuoYi 系列从最早的 RuoYi 到重构增强版 RuoYi-Vue-Plus,这套基于 Spring Boot 的快速开发脚手架已经服务了大量企业和个人开发者。
但今天要介绍的不是传统的后台管理系统,而是在 RuoYi-Vue-Plus 基础上**扩展 AI 功能**的开源项目 —— **RuoYi-AI(JavaGuide 所有开源项目分享都无商务性质,纯分享,欢迎自荐,地址: https://github.com/CodingDocs/awesome-java)** 。
## 项目介绍
RuoYi-AI 是一个开箱即用的智能 AI 平台,深度集成了 FastGPT、扣子(Coze)、DIFY 等主流 AI 平台,支持 MCP 协议,提供 RAG 技术、知识图谱、数字人、 AI 流程编排和 AI 编程能力。
RuoYi-AI 不是从零开始构建的新项目,而是在 RuoYi-Vue-Plus 这个成熟的企业级后台管理系统基础上扩展而来的。这意味着你得到的不仅有 AI 平台功能,还有一整套企业应用该有的用户体系、权限管理等能力。

### 为什么需要 RuoYi-AI?
在介绍项目之前,先聊聊当前 AI 应用开发面临的真实困境。
- **技术选型复杂**:市面上有太多 AI 相关技术栈 —— Spring AI、LangChain4j、LangChain、LlamaIndex……每个都有自己的定位和适用场景。对于初次接触 AI 开发的 Java 开发者来说,选择本身就是一道门槛。
- **集成成本高昂**:想接入 OpenAI、通义千问、智谱 AI 等模型,每个平台的 API 规范都不一样。想用 FastGPT 的知识库、DIFY 的流程编排、Coze 的 Bot 能力,又要分别研究各自的 SDK。
- **学习曲线陡峭**:想做一个能用的 AI 应用,不仅要懂大模型调用,还要掌握向量数据库、RAG 检索、流式响应、知识图谱……这些概念堆在一起,很容易让人望而却步。
RuoYi-AI 的出现,本质上是要**降低 Java 开发者构建 AI 应用的门槛** —— 它把主流 AI 平台的能力封装好了,把复杂的 AI 技术栈整合好了,你只需要关注自己的业务逻辑。
### 技术架构
```
┌─────────────────────────────────────────────────────────┐
│ 用户层 │
├──────────────┬──────────────┬──────────────────────────┤
│ Web 用户端 │ Admin 管理端│ 微信小程序 │
│ Vue 3 │ Vue 3 │ UniApp │
│ Naive UI │ Element UI │ │
└──────┬───────┴──────┬───────┴──────────┬───────────────┘
│ │ │
└──────────────┴────────────────────┘
│
┌──────────────▼──────────────────────┐
│ API Gateway / Sa-Token │
└──────────────┬──────────────────────┘
│
┌──────────────▼──────────────────────┐
│ Spring Boot 3.4 应用层 │
├──────────────┬──────────────────────┤
│ Spring AI │ Langchain4j │
├──────────────┴──────────────────────┤
│ AI 服务编排层 │
├──────────────────────────────────────┤
│ FastGPT │ Coze │ DIFY │ OpenAI ... │
└──────────────┬──────────────────────┘
│
┌──────────────▼──────────────────────┐
│ 数据存储层 │
├──────────────────────────────────────┤
│ MySQL 8.0 │ Redis │ Milvus/Qdrant │
└──────────────────────────────────────┘
```
**核心技术栈:**
|层次|技术选型|说明|
| ----------| --------------------------------------------| ----------------------------------------|
|后端框架|Spring Boot 3.4 + Spring AI + Langchain4j|双 AI 框架集成设计|
|前端技术|Vue 3 + Vben Admin + Naive UI|管理端用 Element UI,用户端用 Naive UI|
|数据存储|MySQL 8.0 + Redis + Milvus/Weaviate/Qdrant|支持多种向量数据库|
|安全认证|Sa-Token + JWT|双重安全保障|
|文档处理|Apache Tika|支持 PDF、Word、Excel 解析|
## 核心功能
RuoYi-AI 提供了完整的在线演示:
|访问端|地址|账号密码|
| --------| ------| ------------------|
|用户端|**https://web.pandarobot.chat**|admin / admin123|
|管理端|**https://admin.pandarobot.chat**|admin / admin123|
### 1\. 智能 AI 引擎
RuoYi-AI 的核心价值在于它不是简单接入几个模型 API,而是构建了一个**统一的 AI 能力抽象层**。
**多模型接入能力**:开箱即支持 OpenAI GPT-4、Azure OpenAI、ChatGLM、通义千问、智谱 AI 等主流模型。你可以在后台统一管理这些模型的 API Key,配置不同模型用于不同场景。
更值得关注的是它对 **AI 应用平台的深度集成** —— 这不是简单的 API 调用封装,而是真正把平台的能力接入进来了:
|平台|集成方式|核心能力|
| -----------| ----------------------| ------------------------------------|
|FastGPT|原生 API 支持|知识库检索、工作流编排、上下文管理|
|扣子 Coze|官方 SDK 集成|Bot 对话、流式响应|
|DIFY|Java Client 完整兼容|应用编排、工作流、知识库管理|
**Spring AI MCP 集成**:这是 RuoYi-AI 在技术前瞻性上的一个亮点。
**MCP (Model Context Protocol)** 是 Anthropic 在 2024 年 11 月推出并开源的开放协议标准,定义了 AI 应用与外部数据源/工具的交互方式。可以把它理解为"**AI 时代的 HTTP**" —— 就像 HTTP 标准化了 Web 通信,MCP 正在标准化 AI 模型与工具生态的交互方式。
**流式对话体验**:采用 SSE(Server-Sent Events)和 WebSocket 双模式支持。
|技术|适用场景|优势|
| -----------| --------------------| -------------------------------|
|SSE|单向推送、简单场景|基于 HTTP、兼容性好、自动重连|
|WebSocket|双向通信、复杂交互|实时性强、支持双向消息传递|
### 2\. 本地化 RAG 方案
RAG (Retrieval-Augmented Generation,检索增强生成) 是当前解决大模型"幻觉"问题的主流技术方案。RuoYi-AI 的特色在于它提供了一个**完整的本地化 RAG 落地方案**。
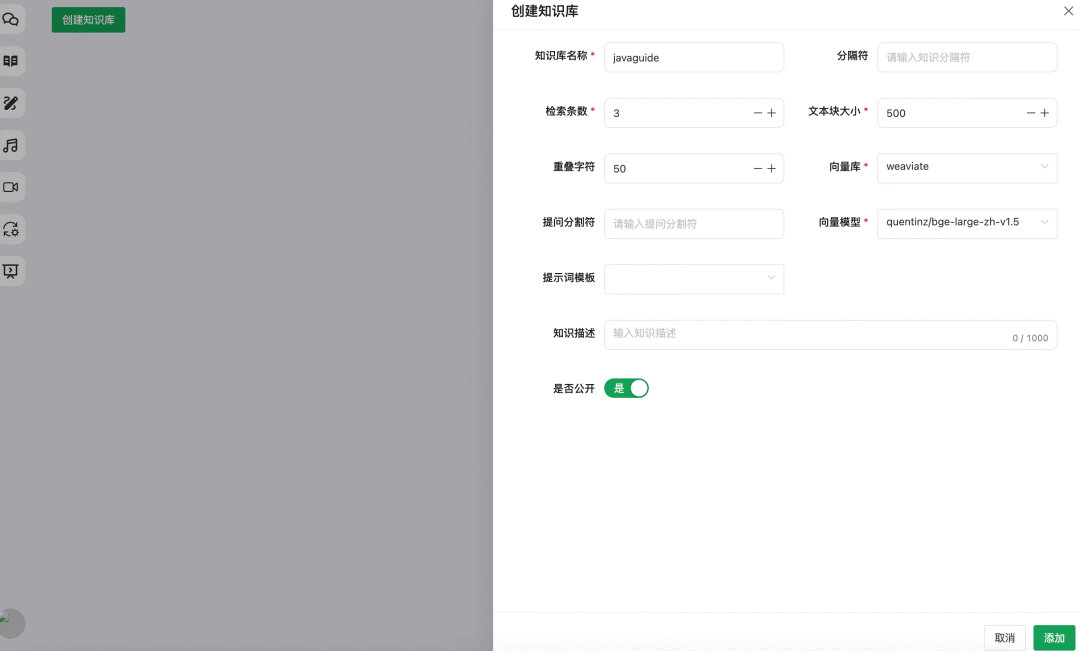
**为什么需要本地化 RAG?**
传统的云服务 RAG 方案(如直接调用 OpenAI API)存在几个现实问题:
1. **数据隐私风险**:企业的核心知识库、内部文档上传到第三方平台,存在数据泄露隐患。
2. **网络依赖性强**:实时检索需要稳定网络,内网环境难以使用。
3. **成本不可控**:每次调用都需要消耗 API 配额,高频场景成本激增。
4. **响应延迟**:数据传输到云端再返回,延迟明显高于本地处理。
我的[星球](/uploads/shares/4/assets/笔记同步助手/attachments/星球-20260224091959-irkocpy)目前正在更新 [《SpringAI 智能面试平台+RAG 知识库》](/uploads/shares/4/assets/笔记同步助手/attachments/《SpringAI智能面试平台+RAG知识库》-20260224091959-5i82jaf)配套实战项目教程,涉及到 Prompt Engineering、大模型集成、RAG(检索增强生成)、高性能对象存储与向量数据库。Spring AI 和 RAG 面试题已更新,两篇加起来接近 60 道题目。
RAG 面试题
**RuoYi-AI 的本地化 RAG 架构:**
```
用户上传文档
│
▼
┌─────────────────┐
│ 文档解析层 │ Apache Tika
└────────┬────────┘
│
▼
┌─────────────────┐
│ 文本分块 │ 智能切分 + 重叠保留
└────────┬────────┘
│
▼
┌─────────────────┐
│ 向量嵌入 │ BGE-large-zh-v1.5
└────────┬────────┘
│
▼
┌─────────────────┐
│ 向量数据库 │ Milvus / Weaviate
└─────────────────┘
│
▼
检索返回 Top-K
```
**技术选型亮点:**
- **Embedding 模型**:采用 BGE-large-zh-v1.5 中文向量模型,这是目前在中文语义理解任务上表现优异的开源模型。
- **向量数据库**:支持 Milvus、Weaviate 两种主流选择,你可以根据数据规模和性能要求灵活切换。
- **本地推理**:兼容 Ollama、vLLM 等本地推理框架,可以完全离线运行。
### 3\. 知识图谱与智能编排
单纯依靠向量检索的 RAG 方案在面对复杂推理问题时仍有局限 —— 这就是为什么 RuoYi-AI 还集成了知识图谱能力。
**知识图谱在 AI 系统中的作用:**
知识图谱以"实体-关系-属性"的结构化形式组织信息,能够为大模型提供三层增强:
|增强维度|向量检索|知识图谱|融合效果|
| ----------| ------------| ----------| --------------|
|语义理解|模糊相似度|精确关联|互补|
|多跳推理|较弱|强|拓展推理深度|
|可追溯性|分数参考|路径可视|双重溯源|
|幻觉控制|中等|强|显著降低|
RuoYi-AI 采用了 **GraphRAG 方法** —— 这是牛津大学等机构在 ACL 2025 提出的创新方案,通过利用 LLM 从原始文档中构建知识图谱,并基于图谱检索知识来增强回答。
**AI 流程编排器:**
对于复杂场景,RuoYi-AI 提供了可视化的工作流设计器。你可以像设计业务流程一样设计 AI 任务的处理流程。这种可视化编排能力,让你不需要写代码就能设计复杂的 AI 应用逻辑。
### 4\. AI 创作工具
除了对话能力,RuoYi-AI 还集成了多种 AI 创作工具。
- **AI 绘画**:深度集成 DALL·E-3、MidJourney、Stable Diffusion,支持文生图、图生图等多种模式。
- **智能 PPT 生成**:一键将文本内容转换为结构化的演示文稿。
- **多模态理解**:支持文本、图片、文档等多种格式的智能处理。
这些能力的集成,让 RuoYi-AI 成为一个**全能型 AI 内容创作中心**。
## 快速上手
### 系统要求
|软件|版本要求|说明|
| ---------| -------------| ----------------------------|
|JDK|17+|OpenJDK 或 Oracle JDK 均可|
|MySQL|8.0+|数据持久化存储|
|Redis|5.0+|缓存和会话管理|
|Node.js|20.18.0 LTS|前端构建依赖|
|Maven|3.9.9+|后端构建工具|
### 安装步骤概览
**1.** **克隆项目**
```
git clone https://gitee.com/ageerle/ruoyi-ai
```
**2.** **后端配置**
在 IDEA 中导入项目后,主要配置 `application.yml`:
```
spring:
datasource:
url:jdbc:mysql://localhost:3306/ruoyi_ai?useUnicode=true&characterEncoding=utf8
username:root
password:你的数据库密码
data:
redis:
host:localhost
port:6379
```
**3.** **初始化数据库**
执行项目中的 SQL 脚本创建表结构并导入初始数据。
**4.** **启动后端服务**
运行 `RuoYiAiApplication.java` 的 main 方法即可。
**5.** **前端安装**
管理端和用户端是分开的两个项目:
```
# 管理端
git clone https://gitee.com/ageerle/ruoyi-admin
cd ruoyi-admin
pnpm install
pnpm run dev:antd
# 用户端
git clone https://gitee.com/ageerle/ruoyi-web
cd ruoyi-web
npm install
npm run dev
```
## 与同类平台的对比
为了更清晰地理解 RuoYi-AI 的定位,我们把它和 FastGPT、DIFY 做个对比:
|对比维度|RuoYi-AI|FastGPT|DIFY|
| ----------| -----------------------| ------------------| --------------------|
|**核心定位**|全栈企业 AI 平台|高精度 RAG 专用|低代码 AI 开发平台|
|**技术栈**|Java 17 + Spring Boot|Node.js + React|云原生架构|
|**后端语言**|Java|JavaScript|Go/Python|
|**企业功能**|支付/微信/权限完备|需自行开发|需自行开发|
|**RAG 能力**|本地化方案|高精度检索|可视化编排|
|**部署复杂度**|中等(Docker 支持)|简单|简单|
|**适合团队**|Java 技术栈团队|数据隐私优先场景|快速原型验证|
|**学习曲线**|Java 友好|需要学习 Node.js|需要学习云原生|
**选型建议:**
- **选择 RuoYi-AI**:如果你是 Java 技术栈,需要完整的企业功能(支付、权限、微信集成),希望快速搭建一个可商用的 AI 平台。
- **选择 FastGPT**:如果数据隐私是第一优先级,对检索精度有极高要求。
- **选择 DIFY**:如果团队希望用低代码方式快速验证想法,需要灵活的工作流编排。
## 总结
RuoYi-AI 不是又一个重复的轮子,而是精准切中了 Java 开发者构建 AI 应用时的几个核心痛点:**技术选型复杂、集成成本高、学习曲线陡峭**。
对于开发者而言,它的价值在于:
- **降低入门门槛**:不需要从零学习所有 AI 技术
- **生产级质量**:基于成熟的 RuoYi 架构,可直接商用
- **持续演进**:集成 MCP 等前瞻性技术,为未来扩展打好基础
对于企业而言,它的价值在于:
- **快速落地**:省去从零构建的时间成本
- **数据可控**:支持完全本地化部署
- **功能完备**:支付、权限、微信集成等企业能力一应俱全
如果你正在寻找一个可以快速上手的 AI 应用实战项目,或者需要为企业搭建一个完整的 AI 平台,可以了解一下 RuoYi-AI。
- Github 地址:**https://github.com/ageerle/ruoyi-ai**
- 官方文档:**https://doc.pandarobot.chat/**

**⭐️推荐阅读**:
- [《SpringAI 智能面试平台+RAG 知识库》](/uploads/shares/4/assets/笔记同步助手/attachments/《SpringAI智能面试平台+RAG知识库》-20260224091959-1sqc875)
- [JavaGuide 沉浸式阅读模式发布!](/uploads/shares/4/assets/笔记同步助手/attachments/JavaGuide沉浸式阅读模式发布!-20260224091959-vkckeks)
- [面试官:“你连Claude Code都没用过吗?”,我怼回去:“就没用过又怎么了?”](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:“你连ClaudeCode都没用过吗?”,我怼回去:“就没用过又怎么了?”-20260224092000-cedfzur)
- [IDEA 终于能爽用 Claude Code了!!](/uploads/shares/4/assets/笔记同步助手/attachments/IDEA终于能爽用ClaudeCode了!!-20260224092000-8y7zb84)
- [2025 版 Java 学习路线发布:新增 AI 开发,4w 字保姆级教程](/uploads/shares/4/assets/笔记同步助手/attachments/2025版Java学习路线发布:新增AI开发,4w字保姆级教程-20260224092000-wmv4d31)
- [阿里又开源了一个顶级 Java 项目!](/uploads/shares/4/assets/笔记同步助手/attachments/阿里又开源了一个顶级Java项目!-20260224092000-0ykok5a)
- [对标MinIO!全新一代分布式文件系统诞生!](/uploads/shares/4/assets/笔记同步助手/attachments/对标MinIO!全新一代分布式文件系统诞生!-20260224092001-o581v3m)
---

Original Guide JavaGuide
继续滑动看下一个

JavaGuide
向上滑动看下一个[^39]: # 大白话说清楚xxl-job底层定时调度的原理!技术解析文章
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260221092256-jo8q0zp)
## 正文
公众号名称:阿伟的水杯
作者名称:阿伟的水杯
发布时间:2026-02-06 11:47
xxl-job,一个很好用的定时调度工具。相信每个做web开发的都用过不少,作用是可以定时帮你调用某些任务。
先说结论:xxl-job外壳是一个springboot应用,springboot主要用于web界面显示。在springboot启动的时候,会额外创建两种重要的线程。
第一种:一个不断死循环的线程,每一秒执行一次。主要作用就是检查各个任务是否到了执行时间点。
第二种:由两个线程池构成,一个快线程池一个慢线程池,系统会记录每个任务的执行时间,合理分配到对应的两个线程池,以便任务最大程度的互不干扰。
逻辑详细解析
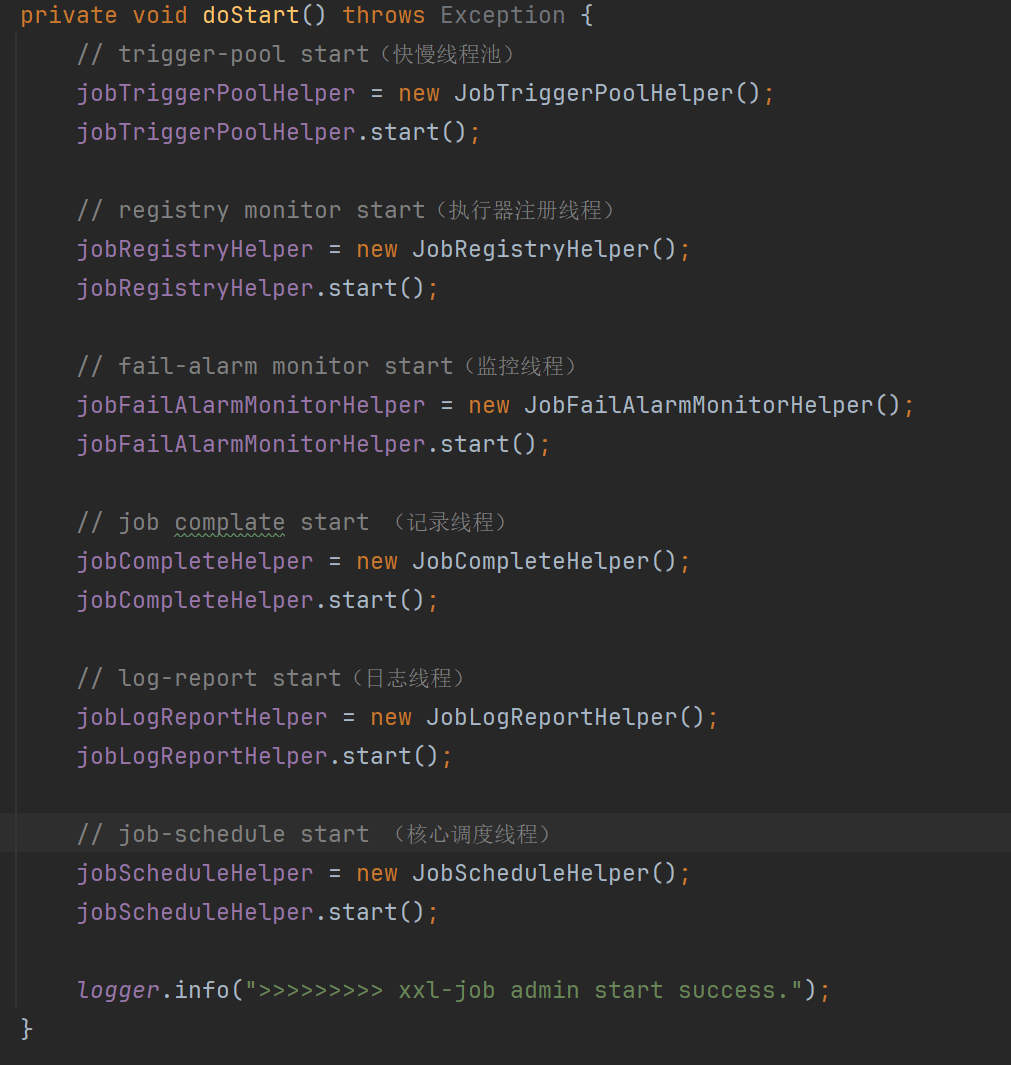
可以看到实际由很多种线程会启动,但重点聚焦于第一个和最后一个即可。
核心调度线程:总的是一个死循环。
调度第一步是获取锁,主要是xxl-job可以多机器分布式部署,所以有抢锁的这一步,用的是mysql的写入锁
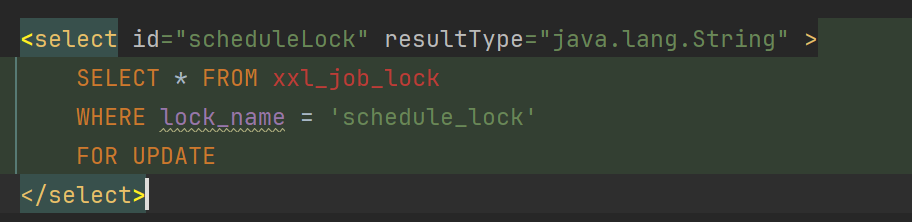
同一时间只会有一个线程可以获取到这个写入锁,多机部署的时候其他没获取到的线程会一直等待直到锁释放。
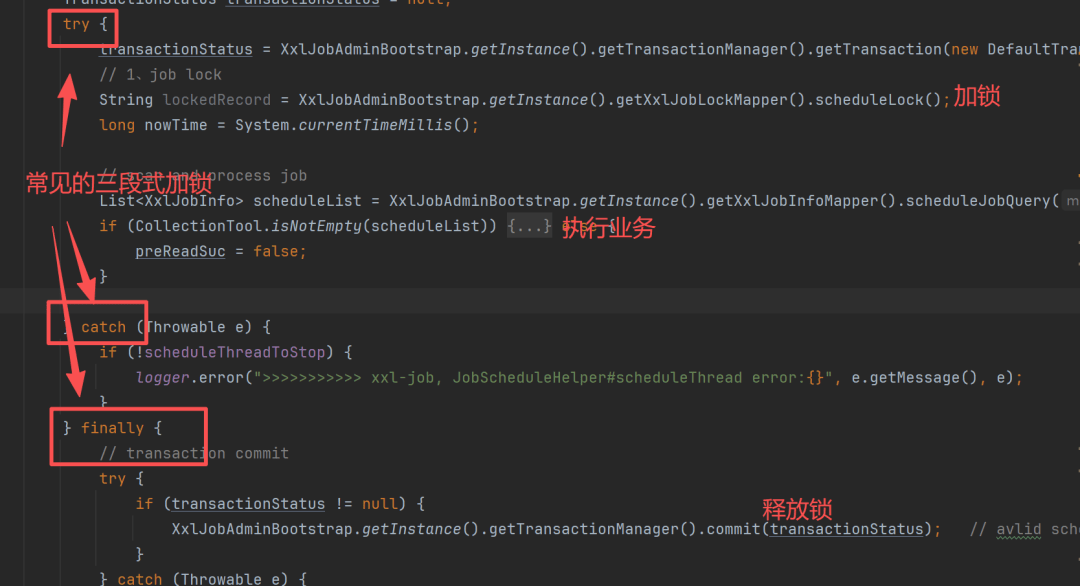
可以看到结构很常见,try加finally,常见的加锁方式。巧妙的是用了mysql的事务。
这段代码里虽然用到了事务,但是无论报不报错,事务都会提交(因为在finally里)。就算xxl-job突然挂了,mysql意识到session没了或者事务超时了都会自动回滚事务,也可以达成自动释放锁的功能。
不借助redis等,只使用mysql+事务,就实现分布式锁。
调度第二步:等待
每隔一秒需要等待一次,否则执行太快会导致cpu占用过高。
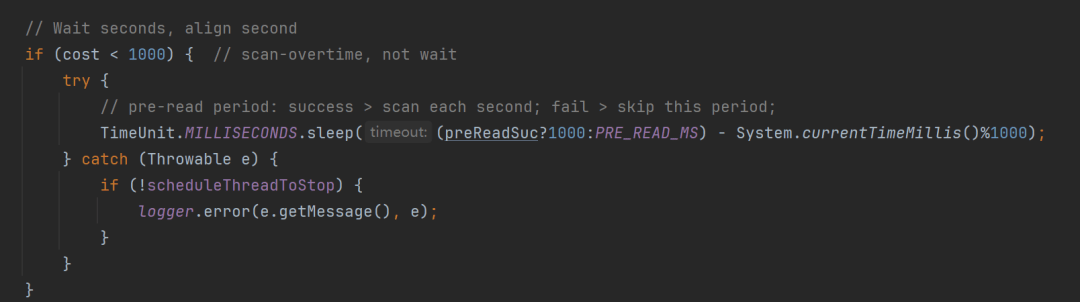
如果两个循环将耗时超过1秒,则直接继续执行不需等待。
如果小于1秒,则会等待到下一个整数秒,具体算法就是对当前毫秒数求余数得到这一秒里过了多少毫秒,比如过了400毫秒了,那么就再等600毫秒,下次执行就刚好整数秒。
这里还有个速度优化就是,调度的时候其实会一次性查询未来5秒内的任务一起执行,5秒内的任务都会预推入内存等待池子。
总结
调度的执行逻辑是:不断的查询5秒内需要执行的任务,有则推入内存等待池子,没有则等待到下一秒再继续查询。(5秒内的任务,第一次被查出来执行的时候同时会修改下次要执行的时间,所以不会重复执行)
内存等待池子还会对应再起一个线程,会把到了真正到了时间点的任务捞出,放到真正的执行用的快慢池子中(根据上次任务执行是否超时情况)
之所以设计这么三层架构,好处有几个:
1.入口的时候一次性查询5秒的,减少数据库查询压力
2.内存等待池子,主要是规避防止数据库查询没能在1秒内完成导致的超时,入口主要承接的是数据库查询的压力。内存等待池子则是纯粹的内存操作,延时风险极小。
3.快慢执行池:一进入这个池子,就不需要考虑时间了,都是需要执行的任务了。
快慢执行池
第一次的时候所有执行任务都会进入快执行池。执行完成后记录是否超时了(超过500ms)。如果1分钟内累计超过10次,则会降级进入慢执行池。
主要是为了区分高耗时任务以及高响应任务。高耗时的任务反正耗时那么高了也不用在乎准不准时了,所以就都分配到了慢池子中,起到隔离作用。
执行过程
先是获取执行器地址,获取重试策略、参数以及路由策略等基础配置。
最后通过http对对应服务发起请求。

同步等待http的结果,记录日志,完成调度完整过程。
这是快执行池的代码:

快慢线程池都分别定义了最大200、100个线程,这意味着每个池子最多同时执行200、100个任务,超出的任务将被抛弃。
整个架构围绕的一个点,就是风险隔离。每一个任务尽量单独执行的同时,又不大量占用服务器资源。

Tip:学习优秀代码
---

原创 阿伟的水杯 阿伟的水杯
继续滑动看下一个

阿伟的水杯
向上滑动看下一个[^40]: # Bitwarden 跑在 Cloudflare 上!自托管密码管理器再也不用买 VPS 了
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260224192914-7804xq1)
## 正文
公众号名称:小众软件
作者名称:青小蛙
发布时间:2026-02-22 22:29
> 字数 887,阅读大约需 5 分钟
>
> 又少了一个折腾 VPS、NAS 的理由...
>
> 但是多了一个使用 Cloudflare 的理由
>
Bitwarden 是少数客户端与服务器端都开源的密码管理系统,支持完整自托管部署。@Appinn
但有人更进一步:直接把服务器端运行在 Cloudflare Workers 上——也就是说,你连 VPS 都可以省了。

部署 NodeWarden 之后的效果,就是在无服务器的情况下,也能在手机、电脑上使用 Bitwarden 客户端来保存密码了,支持自动登陆、二次验证之类的功能。
## 目录
- • NodeWarden 与 Bitwarden 区别
- • 必要条件
- • 具体部署步骤
- • fork
- • 一键部署
- • 设置 NodeWarden
- • 在客户端登录
- \* 关于密码安全
## NodeWarden 与 Bitwarden 区别
|能力项|Bitwarden|NodeWarden|说明|
| -------------------------------------| -----------| ---------------| ----------------------------|
|单用户保管库(登录/笔记/卡片/身份)|✅|✅|基于Cloudflare D1|
|文件夹 / 收藏|✅|✅|常用管理能力可用|
|全量同步 `/api/sync`|✅|✅|已做兼容与性能优化|
|附件上传/下载|✅|✅|基于 Cloudflare R2|
|导入功能|✅|✅|覆盖常见导入路径|
|网站图标代理|✅|✅|通过 `/icons/{hostname}/icon.png`|
|passkey、TOTP|❌|✅|官方需要会员,我们的不需要|
|多用户|✅|❌|NodeWarden 定位单用户|
|组织/集合/成员权限|✅|❌|没必要实现|
|登录 2FA(TOTP/WebAuthn/Duo/Email)|✅|⚠️ 部分支持|仅支持 TOTP(通过 `TOTP_SECRET`)|
|SSO / SCIM / 企业目录|✅|❌|没必要实现|
|Send|✅|❌|基本没人用|
|紧急访问|✅|❌|没必要实现|
|管理后台 / 计费订阅|✅|❌|纯免费|
|推送通知完整链路|✅|❌|没必要实现|
## 必要条件
1. 1\. 你需要有一个 Cloudflare 账号(必须有一个域名和信用卡)
2. 2\. 一个 GitHub 账号
## 具体部署步骤
### fork
- • GitHub:https://github.com/shuaiplus/NodeWarden
### 一键部署
在你自己的 GitHub 页面上,有一个按钮:
这个步骤需要在 Cloudflare 中绑定 GitHub 账号,根据页面提示即可。
### 设置 NodeWarden
部署成功之后,Cloudflare 会提供一个临时地址,类似 1nodewarden.apipnn.workers.dev,用浏览器打开它,如果打不开,就绑定一个你自己的二级域名。
根据页面提示,一步一步进行即可。
这个步骤主要有:
1. 1\. 设置 JWT\_SECRET
2. 2\. 设置自动更新 GitHub
3. 3\. 设置主账号与密码
4. 4\. 设置启用主账号的二次验证
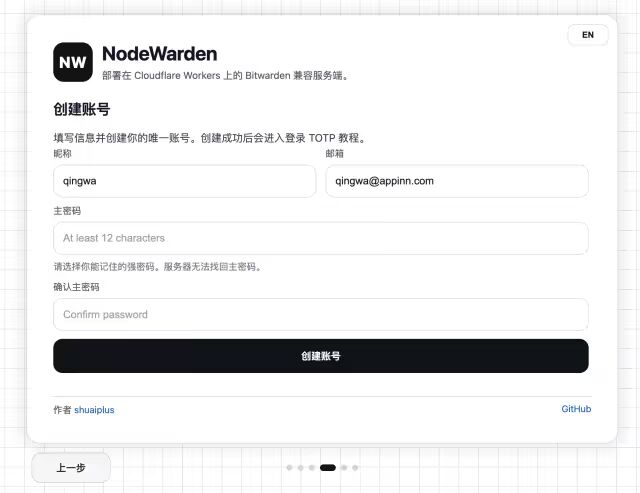
最后一步成功之后,还能选择彻底隐藏这个设置页面:
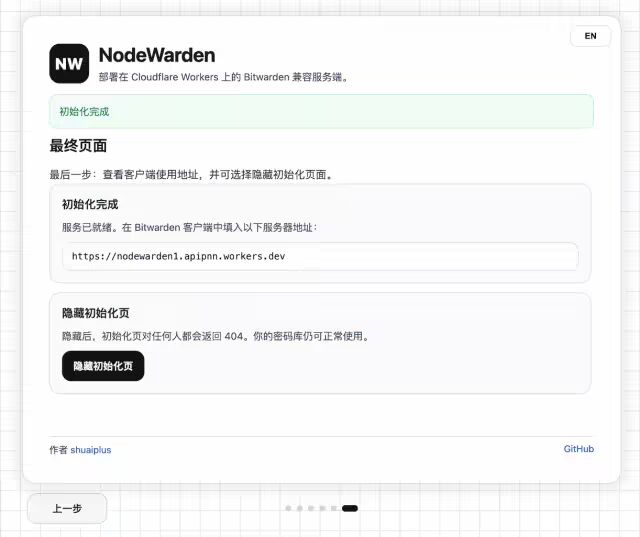
设置完成。
注意:设置完成之后,如果忘了用户名密码,只能全部删除重新来一次...
别问我为什么知道这个。
## 在客户端登录
打开你的 Bitwarden 官方客户端,在登录的地方选择自托管,并输入 **服务器 URL**:
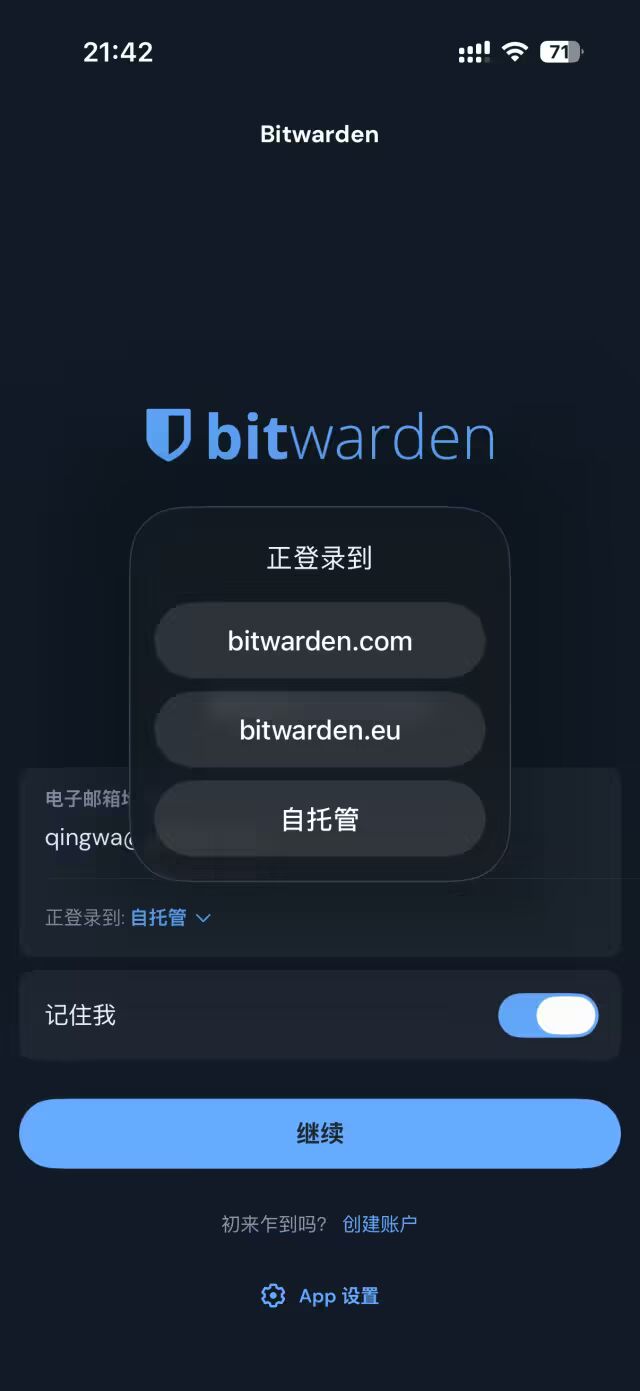
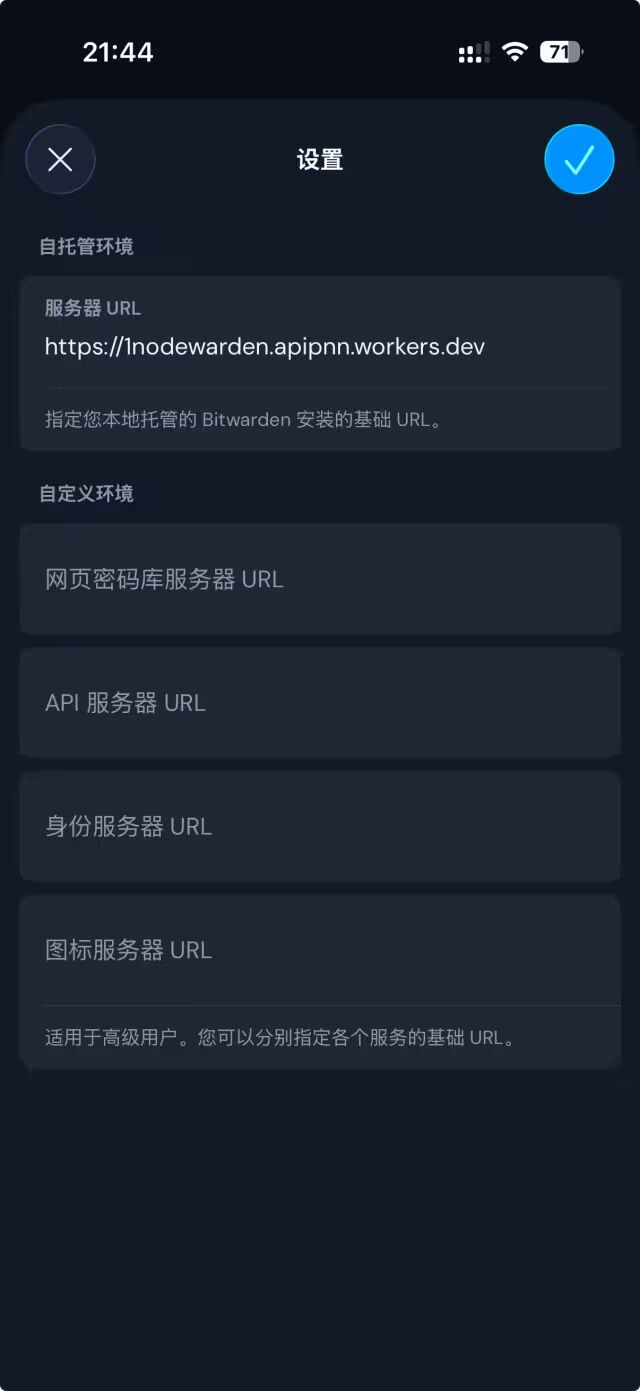
之后,在使用刚刚设置页面设置的用户名和密码(如果设置了二次验证,还会要求输入验证码),就可以正常登录啦:
趁假期最后一天,快去试试吧。
---
原文:https://www.appinn.com/nodewarden/

最后,关于密码安全:
Bitwarden 的设计是这样的:密码在本地加密,服务器只存储加密后的密文,主密码不上传服务器(服务器只保存验证值)。
所以,理论上服务器无法解密你的数据。而部署在 Cloudflare 上是相同的,只要最开始的代码没有恶意,就没有问题,所以开源很重要,如果有恶意代码,会很快被人发现。
---

Original 青小蛙 小众软件
继续滑动看下一个

小众软件
向上滑动看下一个[^41]: # 一篇 Markdown,自动生成封面、信息图、小红书风格,并发布公众号,一个 Skill 全搞定
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260224192847-kq987ys)
## 正文
公众号名称:AI源来如此
作者名称:AI源来如此
发布时间:2026-02-13 05:18
如果你经常写文章、制作信息图、幻灯片、社交媒体素材,那么 **baoyu-skills** 是一个值得收藏的宝藏工具集。它不是一个单一的工具,而是一套针对内容创作全流程的 **Claude Code 插件技能集**,覆盖从文本转视觉内容、结构化图像生成,到自动发布至社交平台的一条龙能力。
---
## 📌 什么是 baoyu-skills?
baoyu-skills 是由宝玉(JimLiu)发布的 **Claude Code 技能集**,旨在提升内容创作与发布效率。简单来说,它是一组可在 Claude Code 等终端 AI 环境中调用的插件,让你像使用命令一样操作 AI,完成下列任务:
- 📊 自动生成信息图、封面图、幻灯片
- 🖼️ 图片与视觉内容自动生成
- 📝 网页 / 推文 转换为 Markdown
- 🚀 自动发布文章或图文至微信公众号、X(Twitter)
它的核心价值是把复杂的创作工作 **模块化、标准化、自动化**。

---
## 🧰 环境准备
在正式使用 baoyu-skills 之前,你至少需要准备:
1. **Node.js 环境**(支持 `npx bun` 命令)
2. 安装 **baoyu-skills 插件技能集**(通过 CLI 或 Claude Code)
### 🚀 安装技能集
推荐通过命令一键安装:
```
npx skills add jimliu/baoyu-skills
```
或在 Claude Code 内运行:
```
/plugin marketplace add jimliu/baoyu-skills
```
也可以按需安装某个子插件:
```
/plugin install content-skills@baoyu-skills
```
安装后,技能就可在 Claude Code 或具备 Skills 环境的终端里使用了。
---
## 🧩 技能分类与核心功能
baoyu-skills 的技能大致分成 **三类**:
---
## 一、📄 内容创作技能(Content Skills)
这些技能主要根据文本或 Markdown 文件生成视觉内容与多媒体素材。
---
### 1\. `baoyu-xhs-images` — 小红书风信息图
适合把一篇文章自动拆分成 1–10 张小卡片风格的信息图,用于小红书等社交平台。
```
/baoyu-xhs-images posts/ai-future/article.md
```
⚙️ 可选参数:
- `--style notion`(指定风格)
- `--layout dense`(指定布局密度)
**示例效果图:**
---
### 2\. `baoyu-infographic` — 专业信息图自动生成
更强大的信息图生成器,支持 20 种布局+17 种风格,可根据内容自动推荐最佳组合。
```
/baoyu-infographic content.md
```
常用参数:
```
/baoyu-infographic content.md --layout funnel --style corporate-memphis --aspect portrait
```
📌 参数说明:
- `--layout`: 信息结构布局(如 funnel/venn/pyramid)
- `--style`: 视觉风格(如 craft-handmade/technical-schematic)
- `--aspect`: 输出比例(横/竖/方)
**建议配图位置:**

---
### 3\. `baoyu-cover-image` — 自动文章封面图
生成文章封面图,支持 **5 维度参数**:
- Type(内容类型,如 hero、scene)
- Palette(配色方案)
- Rendering(渲染风格)
- Text(文字密度)
- Mood(情绪氛围)
```
/baoyu-cover-image article.md --type conceptual --palette warm --rendering hand-drawn
```

---
### 4\. `baoyu-slide-deck` — 自动幻灯片生成
可将 Markdown 内容转成幻灯片图片,并直接导出为 `.pptx` 或 `.pdf`。
```
/baoyu-slide-deck article.md --slides 12 --style corporate --lang zh
```
⚙️ 参数说明:
- `--slides`:目标幻灯片数量
- `--style`:视觉风格预设
- `--audience`:针对人群(beginners / executives)
---
## 二、🤖 AI 生成支持技能(AI Generation Skills)
这些技能提供 AI 图像/文本生成的底层能力:
### ▪ `baoyu-image-gen`
通过 OpenAI、Google Gemini 等 API 生成图像:
```
/baoyu-image-gen --prompt "A stunning infographic banner" --image banner.png
```
可选参数:
- `--provider openai` 或 `google`
- `--ar 16:9`, `--quality 2k` 等
---
### ▪ `baoyu-danger-gemini-web`
通过模拟浏览器自动化调用 Gemini Web,适合无 API 秘钥时使用(不太稳定)。
---
## 三、🛠️ 实用工具技能(Utility Skills)
用于内容处理、网页抓取等辅助任务:
---
### 📌 `baoyu-url-to-markdown`
将任意网页转换成干净的 Markdown 文件:
```
/baoyu-url-to-markdown https://example.com/article -o output.md
```
可加 `--wait` 处理需要交互登录的情况。
---
### 📌 `baoyu-danger-x-to-markdown`
将 Twitter(X)推文或长文转换成 Markdown,并可下载媒体内容。
---
### 📌 `baoyu-compress-image` 和 `baoyu-format-markdown`
分别用于图片压缩和格式化 Markdown 文件。
---
## ✍️ 自动发布技能(社交平台)
baoyu-skills 还支持将内容直接 **发布给社交账号**:
---
### 📣 `baoyu-post-to-wechat` — 发布至微信公众号
支持两种模式:
📌 **图文发布**(可带多图):
```
/baoyu-post-to-wechat 图文 --markdown article.md --image img1.png --image img2.png
```
📌 **文章发布**:
```
/baoyu-post-to-wechat 文章 --markdown article.md
```
如果配置了官方 API 密钥,发布可走 API;否则使用浏览器自动化登录微信公众平台。
---
### 🐦 `baoyu-post-to-x` — 发布至 X(Twitter)
支持发布普通推文、带图推文,也支持长文章以 X Article 形式发布。
---
## 🧪 环境配置
部分技能需要 API 密钥或自定义配置。环境变量可以在 .env 文件中设置:
**加载优先级**(高优先级覆盖低优先级):
- 命令行环境变量(如 `OPENAI_API_KEY=xxx /baoyu-image-gen ...`)
- `process.env`(系统环境变量)
- `/.baoyu-skills/.env`(项目级)
- `~/.baoyu-skills/.env`(用户级)
**配置方法:**
```
# 创建用户级配置目录
mkdir -p ~/.baoyu-skills
# 创建 .env 文件
cat > ~/.baoyu-skills/.env << 'EOF'
# OpenAI
OPENAI_API_KEY=sk-xxx
OPENAI_IMAGE_MODEL=gpt-image-1.5
# OPENAI_BASE_URL=https://api.openai.com/v1
# Google
GOOGLE_API_KEY=xxx
GOOGLE_IMAGE_MODEL=gemini-3-pro-image-preview
# GOOGLE_BASE_URL=https://generativelanguage.googleapis.com/v1beta
# DashScope(阿里通义万相)
DASHSCOPE_API_KEY=sk-xxx
DASHSCOPE_IMAGE_MODEL=z-image-turbo
# DASHSCOPE_BASE_URL=https://dashscope.aliyuncs.com/api/v1
EOF
```
---
## 📌 小结:baoyu-skills 到底能帮你做什么?
|功能分类|典型技能|用途|
| -------------| ----------------------------------| --------------------------|
|内容生成|infographic / xhs-images|自动生成信息图与视觉内容|
|图片/多媒体|image-gen / cover-image|图像生成与封面图设计|
|文档处理|url-to-markdown / compress-image|内容转 MD + 图片处理|
|发布交付|post-to-wechat / post-to-x|一键发布到平台|
---
## 结语
如果你想用 AI 把内容生产流程 **自动化、标准化、可复用**,baoyu-skills 是目前最接近“一条命令搞定”的开源方案之一。
*开源项目地址:https://github.com/JimLiu/baoyu-skills*
---
**个人观点,仅供参考**,非常感谢各位朋友们的支持与**关注**!
如果你觉得这个作品对你有帮助,请不吝**点赞**、**在看**,**分享**给身边更多的朋友。如果你有任何疑问或建议,欢迎在评论区**留言**交流。
---

Original AI源来如此 AI源来如此
继续滑动看下一个

AI源来如此
向上滑动看下一个[^42]: # SQL面试题 02|怎么查连续登录N天的用户?
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260224192858-2yntyll)
## 正文
公众号名称:wood聊大数据
发布时间:2026-02-14 21:01
面试的时候如果你能提到这些实际踩坑经验,面试官会觉得你是真写过,不是背的
我之前做元宇宙社交App的时候,运营提了个需求:找出连续7天活跃的用户,给他们发一个"忠实用户"徽章。
需求听着简单,但有两个坑:
坑1:一天多次登录
用户一天可能打开App十几次,如果不先DISTINCT去重,ROW\_NUMBER的序号会被撑大,差值计算就全乱了。这就是为什么第一步一定要去重。
坑2:DATE\_SUB的引擎兼容性
在Hive里,DATE\_SUB(login\_date, rn) 没问题。但在某些引擎里(比如早期的Doris),DATE\_SUB不支持直接减整数,要用 DATE\_ADD(login\_date, INTERVAL -rn DAY)。我当时在Doris上跑这个SQL直接报错,排查了半小时才发现是函数兼容问题。
#数据分析师必备技能#SQL实战案例分享 #大数据 #大数据分析师
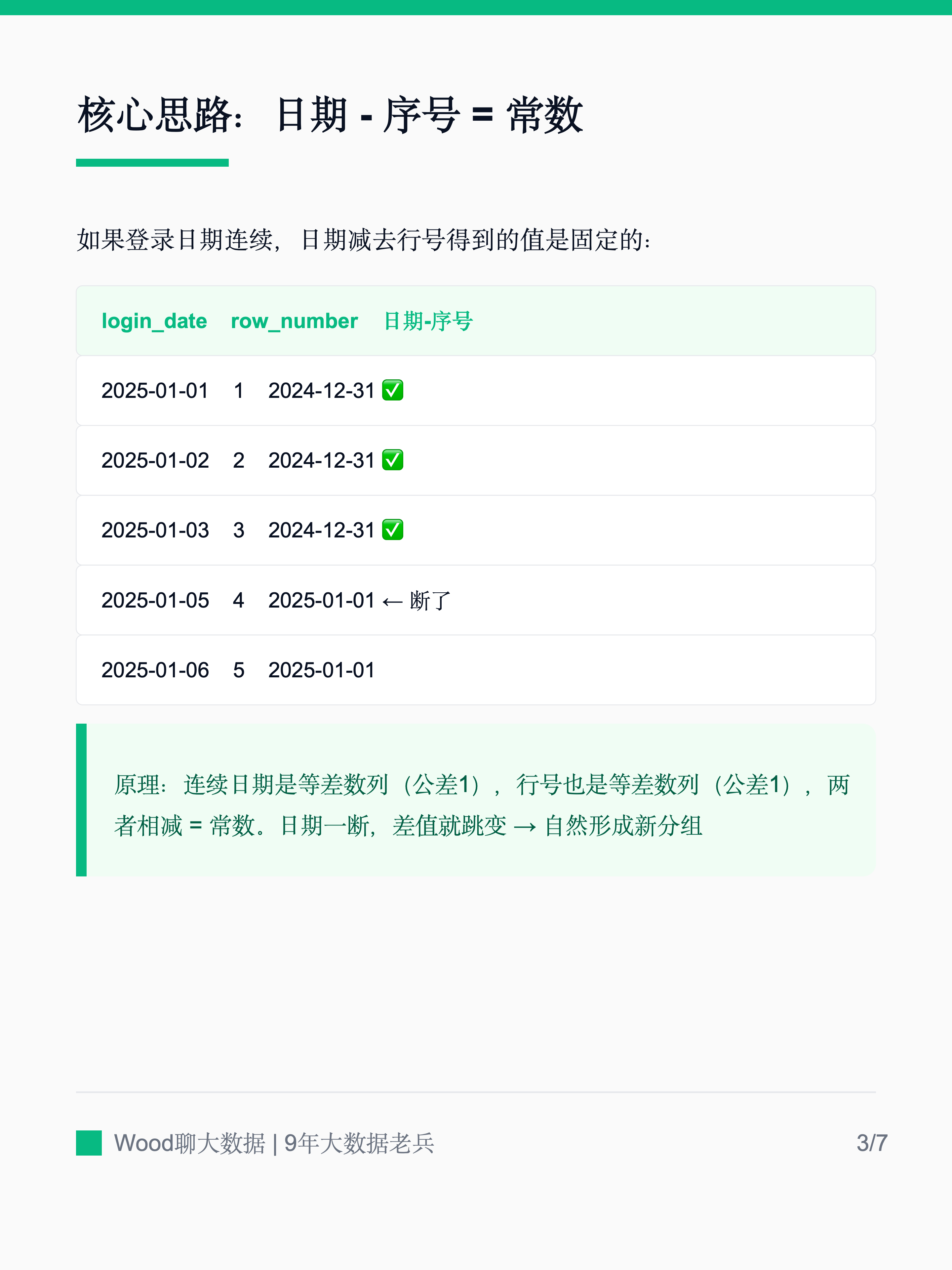[^43]: # 面试官:项目中你是采用哪种缓存模式来解决数据一致性问题的?
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260224111835-d43vdiv)
## 正文
公众号名称:IT杨秀才
作者名称:IT杨秀才
发布时间:2026-01-09 16:44
[秀才的学习网站:https://golangstar.cn/](/uploads/shares/4/assets/笔记同步助手/attachments/秀才的学习网站:https---golangstar-20260224111835-1q2dkdz.cn-)
今天我们来聊聊后端架构的缓存模式问题。在面试高阶工程师或架构师岗位时,缓存模式几乎是必考题。但90%的候选人在回答这个问题时都存在两个致命短板:一是**知识面不够全**,只知道最基础的那一两种模式;二是**理解不够深**,只能照本宣科,泛泛而谈。
特别是当面试官抛出一个杀手锏:“你怎么利用这些缓存模式来解决数据一致性问题?” 很多候选人就掉进了坑里,因为他们没意识到,**很多缓存模式本身就是一致性问题的制造者**。
这篇文章,秀才将结合多年的架构经验,带你去审视每一个缓存模式,剖析它们的优缺点,尤其是在数据一致性里的真实表现。接下来我们先从面试策略谈起。
# 1\. 面试准备
在准备面试前,你不能只靠死记硬背。作为架构师或者是资深后端开发,你需要对自己的知识库了如指掌。
首先,确保你不仅记住了这些模式的名字,还能画出它们的时序图。其次,你需要深挖一下你当前所在公司的实际情况:
1. 你们现在的系统架构中,到底落地了哪些缓存模式?
2. 在这些模式下,有没有爆发过数据不一致的生产事故?最后是怎么填坑的?
3. 在具体的业务流程中,引入缓存后,你是如何编排缓存更新与数据库更新顺序的?是否存在一致性隐患?
把缓存模式吃透,不仅能帮你应对数据一致性的难题,更是解决后续我们将会讲到的**缓存穿透**、**缓存击穿**和**缓存雪崩**这“三座大山”的基石。这两个话题紧密相连,在复习时要融会贯通。
为了让你更直观地理解,我们在脑海中构建一个简化的系统模型:你的应用服务需要同时操作缓存(Cache)和数据库(DB),所有的读写请求都在这两个组件之间周旋。
# 2\. 面试切入
在面试最开始的自我介绍环节,你就可以埋下伏笔。
> 你可以这样说:“我对高并发场景下的缓存模式有比较深刻的实践心得,在过往的项目中,我经常通过灵活运用不同的缓存模式,来解决系统面临的缓存穿透、雪崩以及热点击穿等问题。”
>
这短短一句话,既展示了你的技术深度,又自然地引出了后续的话题。面试官听到这里,大概率会顺水推舟地问:“那你详细说说,你都了解哪些缓存模式?或者在项目中用过哪些?”
这时候,你就可以如数家珍地抛出你的知识储备:
> “在业界主流的实践中,常见的缓存模式包括 Cache Aside、Read Through、Write Through、Write Back 以及 Singleflight。此外,虽然严格意义上不算标准模式,但在实际工程中,删除缓存和延迟双删也是我们经常采用的策略。”
>
这个回答既全面又接地气,覆盖了理论与实战。接下来,我们就一个个拆解这些模式。
# 3\. Cache Aside
Cache Aside可以说是业界应用最广泛的缓存模式了。Cache Aside的核心在于应用程序在数据流转中的定位。在这种模式下,缓存仅仅是一个辅助的数据存储,应用程序直接与数据库进行交互,并全权负责维护缓存与数据库之间的数据状态。
应用程序在这里扮演了数据流转的“总指挥”或“调度员”的角色,它需要同时感知并操作 DB 和 Cache 两个数据源,而不是让缓存组件去自动代理数据库的访问。
1. **写操作流程**
当业务发起写操作时,Cache Aside Pattern 遵循以下严格的执行顺序:
1. **更新数据库**:应用程序首先将变更的数据持久化到数据库中。
2. **删除缓存**:紧接着,应用程序直接将该数据对应的缓存 Key 删除,而不是尝试去更新它。
为了更直观地理解这个过程,请看下方的流程示意图:
2. **读操作流程**
相较于写操作,读操作的链路稍微复杂一些,因为它涉及“命中”与“未命中”的分支处理:
1. **查询缓存**:应用程序首先尝试从 Cache 中获取数据。
2. **缓存命中**:如果在缓存中找到了数据(Hit),直接返回结果,流程结束。
3. **缓存回填**:如果缓存中没有数据(Miss),应用程序需要转向数据库发起查询。成功拿到数据后,**由应用程序显式地将数据写入缓存**,最后将结果返回给调用方。
读操作的详细流转逻辑如下图所示:
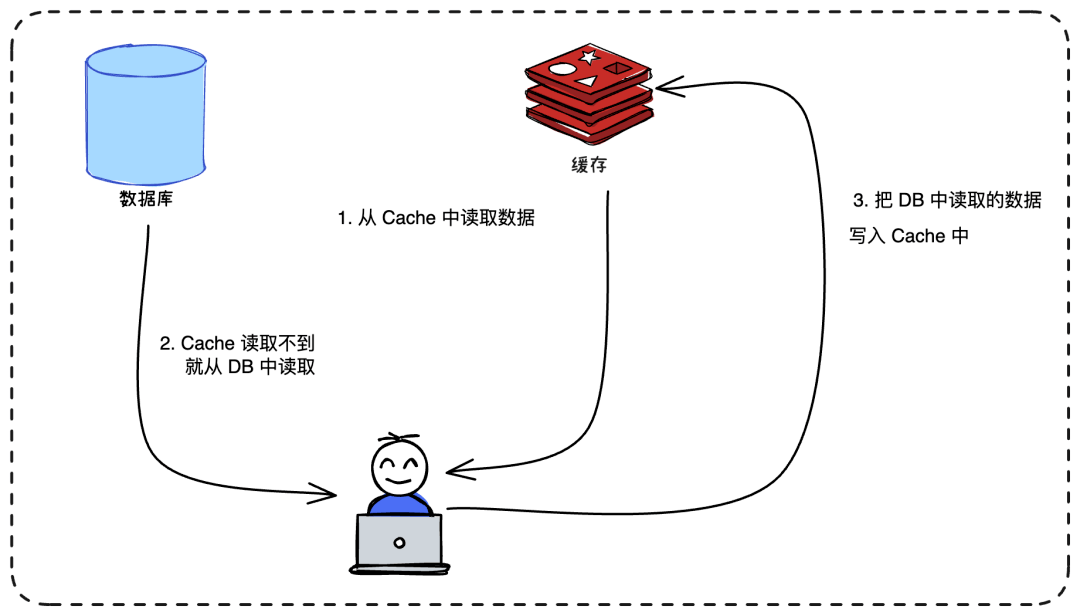
## 3.1 亮点展示
如果你仅仅掌握了上述的操作步骤,那只能算是入门。在高级技术面试中,面试官往往会针对这些“标准步骤”进行连环追问,旨在考察你对并发一致性、性能权衡的深度理解。
1. **写操作为什么必须是“先更新 DB,后删除 Cache”?顺序能不能反过来?**
这是一个非常高频的陷阱题。**结论是:绝对不能反过来。** 如果你采取“先删除 Cache,后更新 DB”的策略,在高并发场景下,极易引发严重的数据不一致问题,且该脏数据很难自动恢复。
假设我们有一个商品库存的场景,当前库存为 100。
- **线程 A(写请求)** :准备将库存修改为 99。
- **线程 B(读请求)** :并发查询该库存。
如果顺序反了(先删后写),时序可能如下:
1. **线程 A** 执行,先删除了 Cache 中的库存数据。
2. **线程 B** 进场,发现 Cache 为空(Miss)。它立即去查 DB,但此时线程 A 还没来得及更新 DB,所以线程 B 读到的是旧值 100。
3. **线程 B** 将读到的旧值 100 写入 Cache。
4. **线程 A** 终于完成了 DB 的更新,将数据改为 99。
**最终结果:** 数据库里是新的 99,但缓存里永远停留在了旧的 100。后续所有的读请求都会命中这个脏数据,直到缓存过期。这在很多业务中是不可接受的。
2. **那“先更新 DB,后删除 Cache”就能保证数据一致吗?**
结论是:从理论上讲,它也不是绝对安全的,依然存在数据不一致的概率,但这个概率极低,工程上通常可以忽略。让我们看看这种“理论上的极端情况”是如何发生的:
这种情况发生的前提是缓存刚好失效(Empty),同时发生并发读写。
1. **线程 A(读请求)** :发现缓存未命中,去查询 DB,读取到了旧值(比如 100)。
2. **线程 B(写请求)** :在线程 A 读完 DB 但还没来得及回填 Cache 的瞬间,线程 B 介入了。它迅速完成了 DB 更新(改为 99),并且完成了删除 Cache 的动作。
3. **线程 A(读请求)** :此时才开始执行“回填缓存”的动作,它拿着刚才读到的旧值 100,写入了 Cache。
**最终结果:** DB 是新值 99,Cache 是旧值 100。**为什么说概率极低?** 这就涉及到了数据库与缓存操作耗时的对比。要发生上述情况,要求“线程 A 从读完 DB 到写入 Cache”这一小段逻辑的执行时间,竟然要比“线程 B 完成整个 DB 更新 + Cache 删除”的时间还要长。
在实际生产环境中,数据库的写操作(涉及锁、磁盘 I/O)通常比纯内存的缓存操作要慢得多。读请求通常也会比写请求快。因此,读请求“卡”在中间,正好让写请求完整执行完一整套流程的情况,发生的概率微乎其微。
# 4\. 同步更新
前面说的Cache Aside 是删除缓存的一种策略,那我们可不可以再更新完数据库之后,同步更新缓存呢?说实话,同步更新很难被称为一种设计好的“模式”,因为它本质上就是我们“什么都不封装”时的自然写法。在这个模式下,业务代码把缓存视为一个与数据库平起平坐的**独立数据源**。所有的逻辑判断、读写顺序,全靠业务代码自己来掌控。
先来看**写操作**。当业务需要更新数据时,由业务代码控制写入流程。

再来看**读操作**。同样是由业务代码亲自操刀。
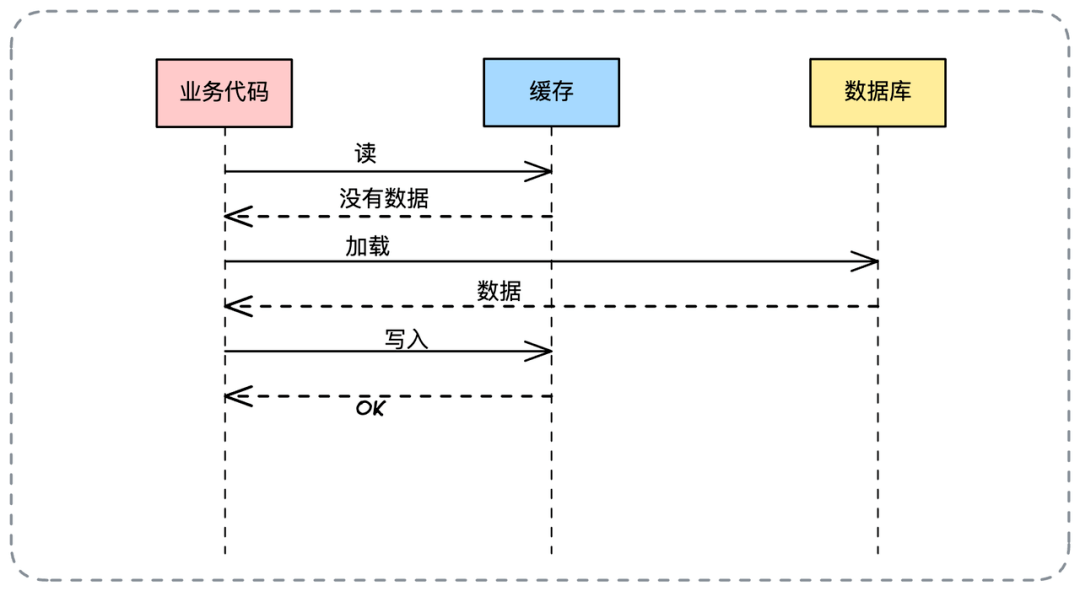
在这个环节,你需要向面试官介绍清楚读写的基本时序。它的核心逻辑是:业务代码显式地处理缓存和数据库。一般业界的最佳实践是**优先写入数据库**。
> 如果面试官追问:“为什么要先写库,而不是先写缓存?”
>
> 你要稳稳地接住:“因为在绝大多数核心业务场景中,**数据库才是数据的最终真理(Source of Truth)** 。只要数据成功写入了数据库,我们就可以认为这次业务操作是成功的。即便随后的缓存写入或更新失败了,缓存本身有过期时间,或者下次读取时发现缓存缺失会重新加载,数据最终会恢复一致。”
>
讲完这些,你必须补上一句至关重要的总结,这是体现你架构深度的关键:
> “但是,老实说,无论是先写数据库还是先写缓存,这种同步更新的模式本身都无法保证数据的强一致性。”这句话往往会激起面试官的兴趣,他可能会问:“为什么都不能解决?在什么场景下会不一致?”
>
这时,你就可以用下面这张图来做降维打击。
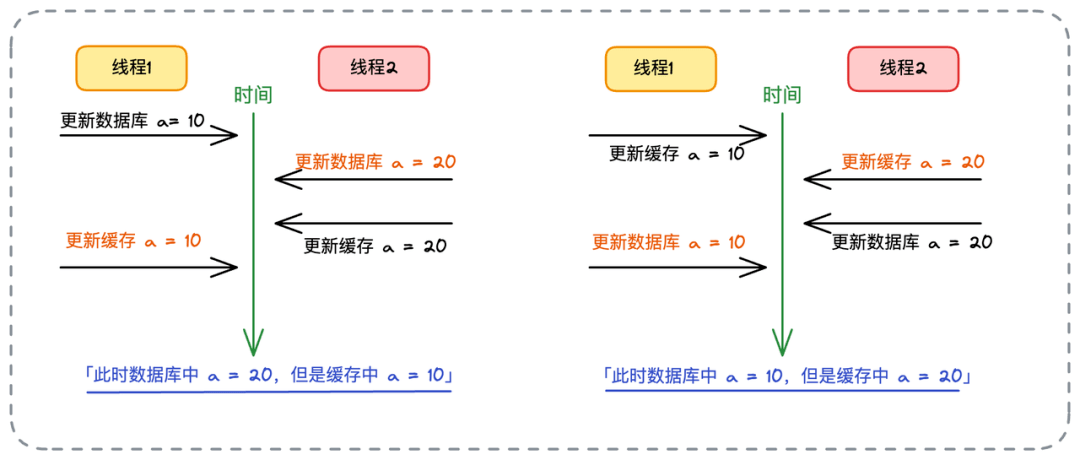
为了方便记忆,我教你一个口诀:**盯住图中的“线程2”,它总是姗姗来迟(后开始),却总是捷足先登(先结束)。**
举个具体的例子:假设我们库存原本是 100。
1. **线程1** 想要把库存更新为 10,它先更新了数据库(DB=10)。
2. 紧接着 **线程2** 想要把库存更新为 20,它动作很快,一口气更新了数据库(DB=20)并且更新了缓存(Cache=20)。
3. 这时候 **线程1** 才慢悠悠地执行它的第二步,更新缓存(Cache=10)。
结果是什么?数据库里是正确的 20,但缓存里却是过期的 10。如果不加控制,直到缓存过期前,用户看到的都是错误的库存。
# 5\. Read Through
**Cache Aside** 的问题在于业务代码太累了,既要管库又要管缓存。于是有了 **Read Through**,也就是**读穿透**模式。
它的核心理念是:**业务方你只管找缓存要数据,如果缓存里没有,缓存组件自己会去数据库加载数据,并把自己喂饱。**
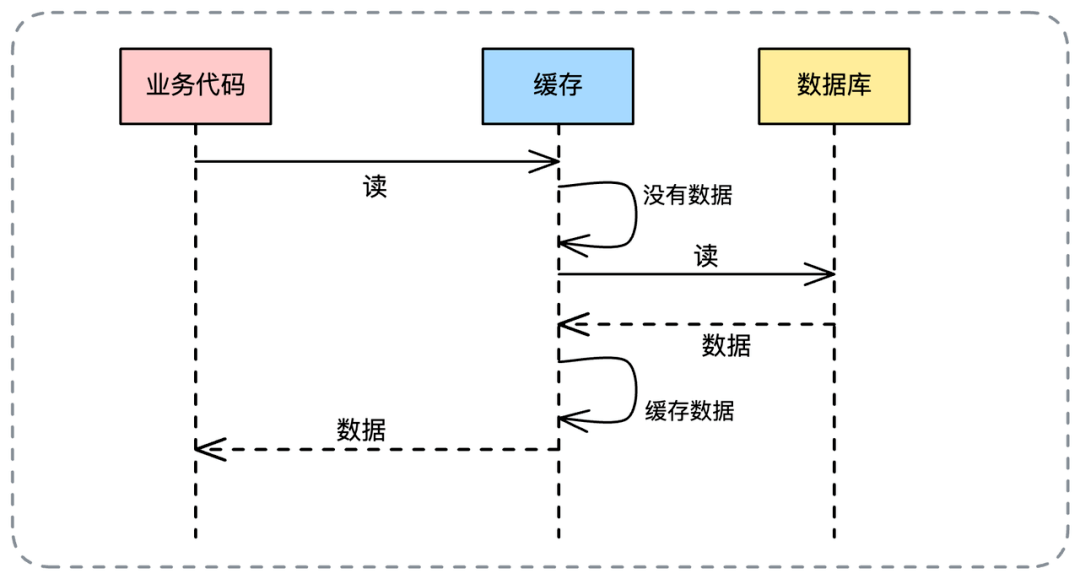
在写入方面,**Read Through** 通常和同步更新 保持一致,没有什么特殊魔法。
你可能会发现,Read Through 只是封装了“读”的逻辑,对于“写”的过程,它依然很原始。所以,它在数据一致性上的表现,和 Cache Aside 是半斤八两,依然存在并发导致的数据不一致问题。如果面试官问到这儿,你直接复用 同步更新的分析逻辑即可。
但是,Read Through 给架构师留了一个“后门”,这也是它的**高光时刻**——**异步化**。
## 5.1 亮点方案:异步加载
当 Read Through 发现缓存未命中时,标准的做法是同步去查库。但我们可以把“加载数据”和“写入缓存”这两个动作解耦,引入异步机制。
1. **变种一:异步回写**
当从数据库查到数据后,立刻把数据返回给业务方,然后启动一个后台线程,异步地把数据写入缓存。
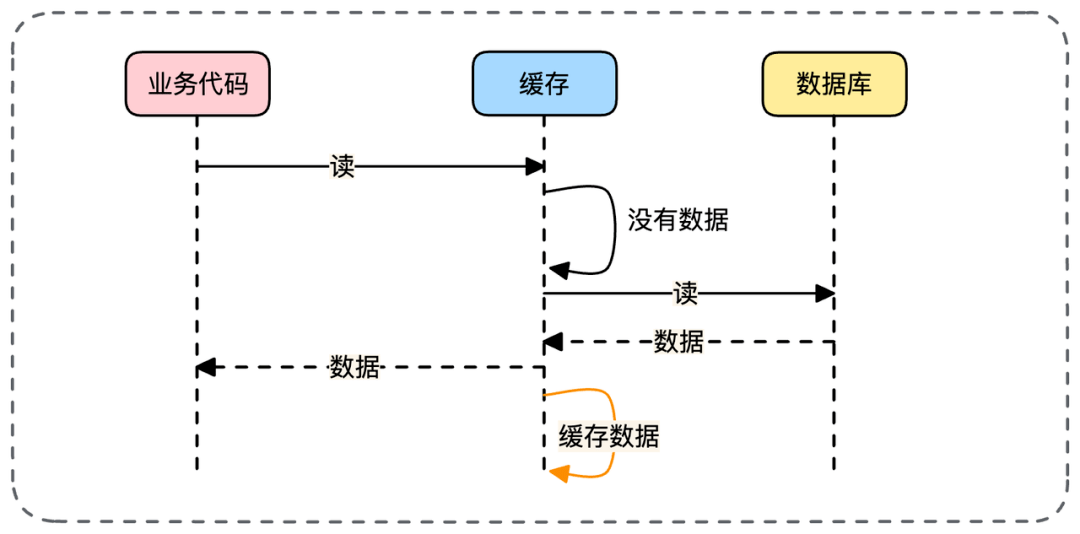
既然回写缓存可以异步,那能不能把从数据库加载数据也异步了?
2. **变种二:全异步加载**
这招更激进。当缓存未命中时,直接给业务方返回一个默认值或者错误码,然后由缓存组件在后台异步地发起数据库查询,并更新缓存。
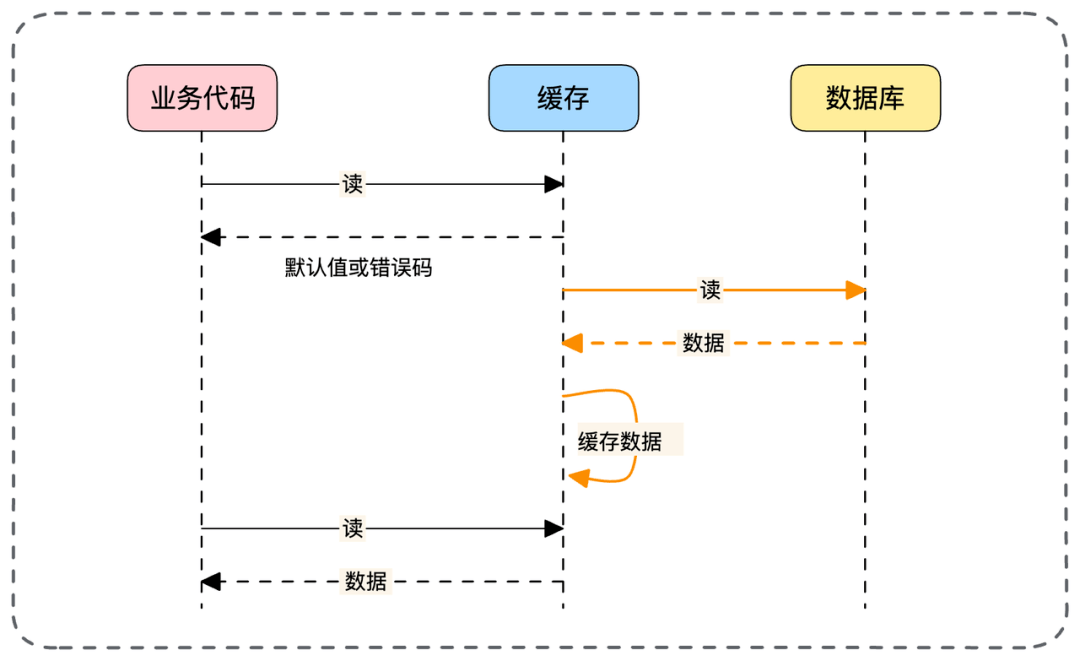
相比第一种变种,第二种的缺陷很明显:业务方在当次调用中拿不到真数据。
场景选择:
如果你的业务对**响应时间(RT)** 有着近乎变态的苛刻要求,可以考虑变种二。代价是业务方必须能容忍短暂的降级数据。而变种一的收益其实相对有限,除非你的缓存写入操作非常慢(比如要存储一个巨大的对象,或者需要进行复杂的序列化),这时候异步回写才有意义。
如果你在实际项目中用过这些变种,一定要结合具体的业务场景(比如电商的热门推荐列表、非关键配置信息等)来举例,说服力会倍增。
# 6\. Write Through
既然读可以穿透,写自然也可以。**Write Through**(写穿透)是指:当业务方需要写入数据时,**只负责写入缓存,然后由缓存组件代替业务方去更新数据库。**
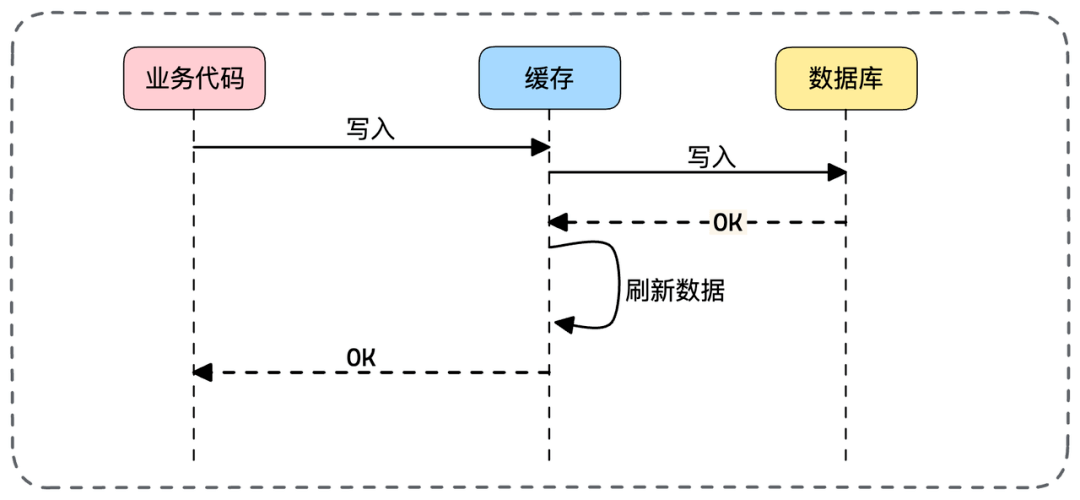
对于读操作,Write Through 和 Cache Aside 是一样的。
这里有几个细节值得注意:
1. Write Through 并没有强制规定是先刷库还是先刷缓存,但在实际落地中,为了数据安全,通常也是优先保证数据库落盘。
2. 如果缓存中原本没有这条数据,写入时要不要顺便更新缓存?一般策略是:如果预判这条数据马上会被读到,那就顺手刷新缓存;否则可以只写库,等下次读的时候再懒加载。
同样,Write Through 也没能解决并发写的一致性死结。
## 6.1 亮点方案:异步写的权衡
和 Read Through 类似,Write Through 也可以玩异步。比如,写入缓存后,立刻给业务方返回“成功”,然后后台异步去写库。
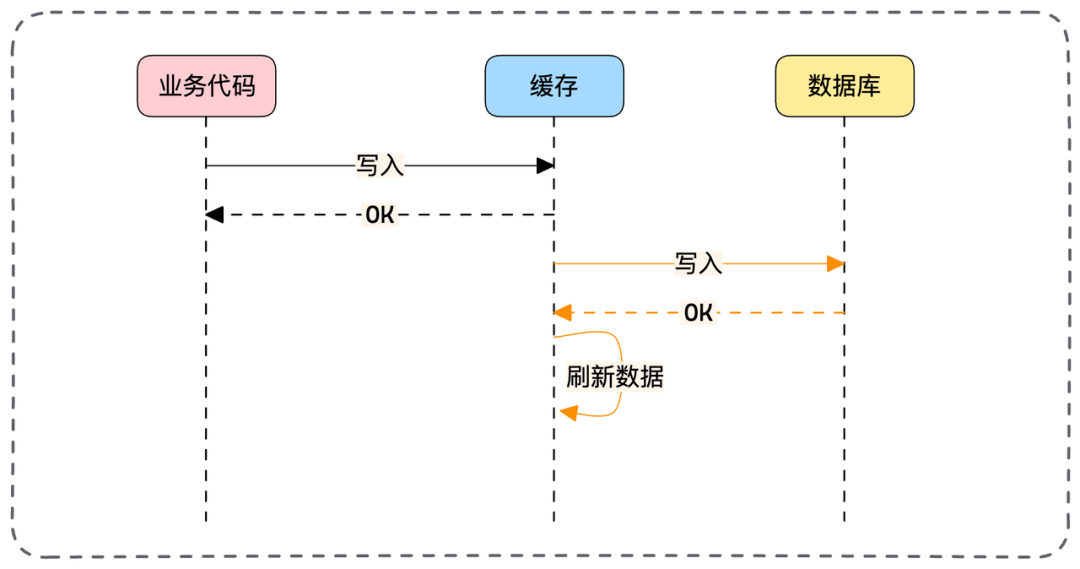
这种模式有一个致命硬伤:**丢数据**。如果缓存组件在回复“成功”后,还没来得及写库就宕机了,那这笔数据就彻底蒸发了。
稍微稳妥一点的变种是:同步写库,但是**异步刷新缓存**。
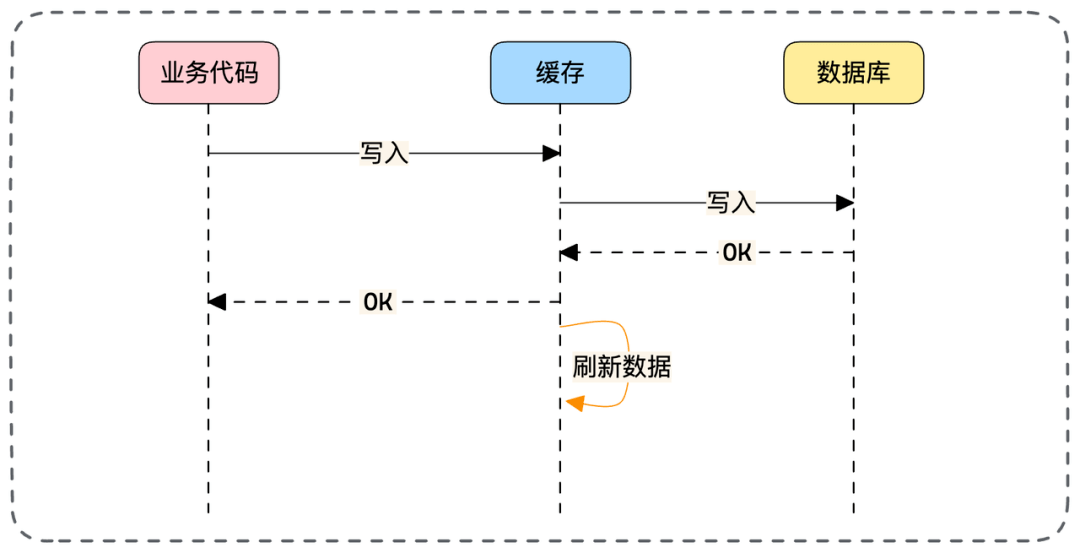
这种变种适合那种“写库很快,但刷缓存很慢”的奇葩场景(比如缓存结构非常复杂)。但无论哪种异步,风险都伴随着收益并存。
# 7\. Write Back
如果你追求极致的写性能,**Write Back**(回写)模式绝对是你的菜。它的特征非常鲜明:**写入数据时,只更新缓存,直接返回。数据库的更新被推迟到缓存数据过期或被逐出时触发。**
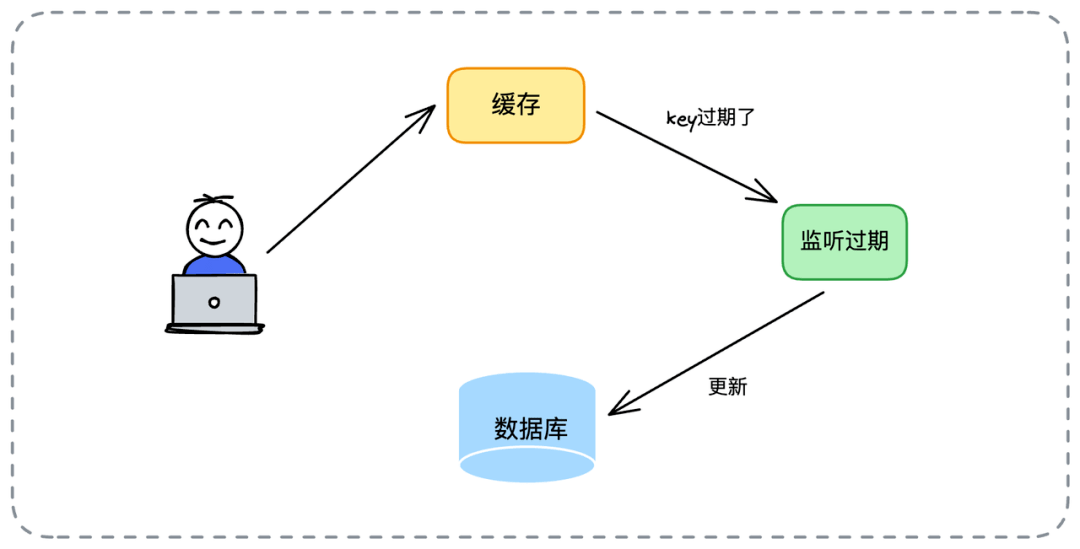
具体的流程是:业务代码只管写缓存。后台有一个守护组件监听缓存中 Key 的过期事件,一旦过期,就将最新数据刷回数据库。显而易见,这有个巨大的隐患:**如果缓存突然宕机,所有未刷回数据库的脏数据将全部丢失。** 这也注定了 Write Back 只能用于那些对数据丢失有一定容忍度,或者缓存层做到了极高可用性的场景。但这里有一个反直觉的结论,也是你可以用来惊艳面试官的亮点:
> “Write Back 虽然容易丢数据,但在数据一致性方面,它其实比 Cache Aside 表现得更好。”
>
为什么?我们需要分情况讨论。
如果是本地缓存(多节点),那肯定不一致。但如果是集中式缓存(如 Redis),在不考虑缓存崩盘导致数据丢失的前提下,它是可以做到逻辑闭环的。我们需要一步步引导面试官理解这个逻辑:
1. **第一步:写的一致性**
在使用 Redis 的场景下,因为所有的写操作都只更新缓存,对于业务方来说,读也是读缓存。在这个封闭的闭环里,业务方读到的永远是它刚刚写入的,数据是自洽的。 虽然数据库里的数据滞后了,但对业务无感。
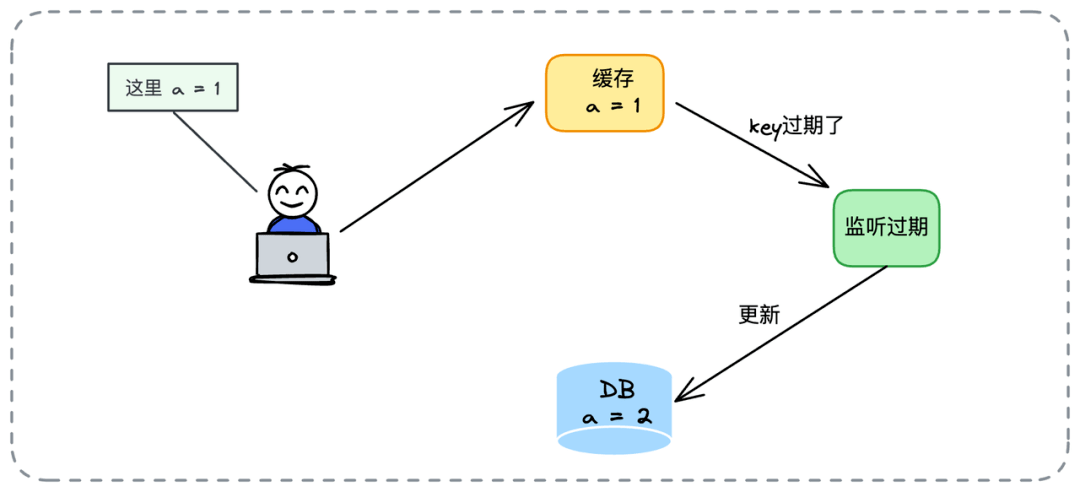
2. **第二步:读的一致性隐患**
当业务方去读数据,发现缓存没了(过期或被逐出),需要去数据库加载。这时候可能会出问题:
1. 读请求去数据库捞到了旧数据(比如 `balance=100`)。
2. 还没来得及回填缓存,突然来了一个写请求,把缓存设为了新值(`balance=200`)。
3. 读请求动作慢了半拍,把旧数据(`balance=100`)回填到了缓存,覆盖了新值。
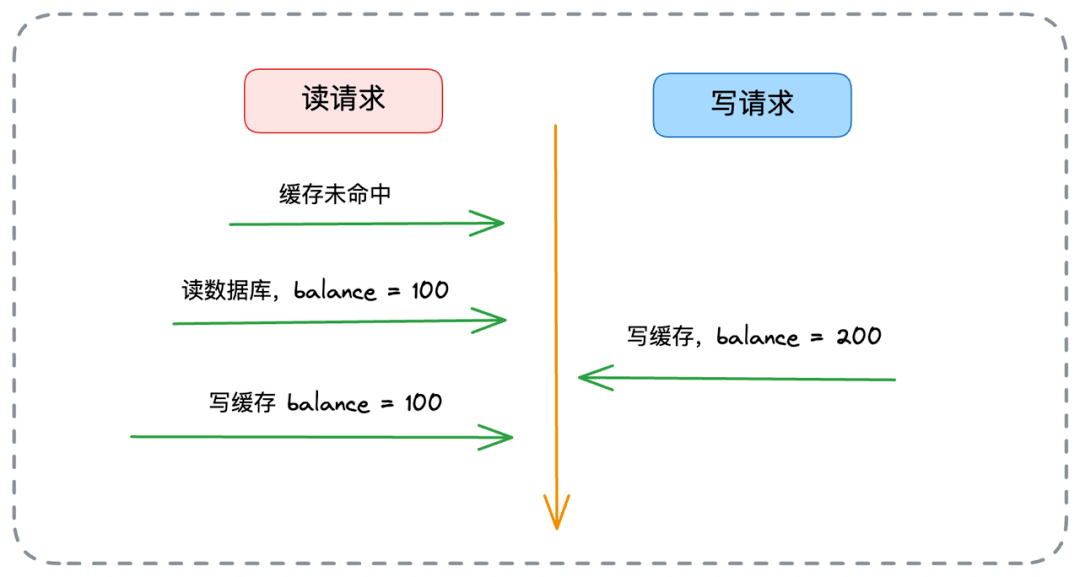
3. **第三步:解决方案**
解决思路也很经典——利用 Redis 的 SETNX 指令。
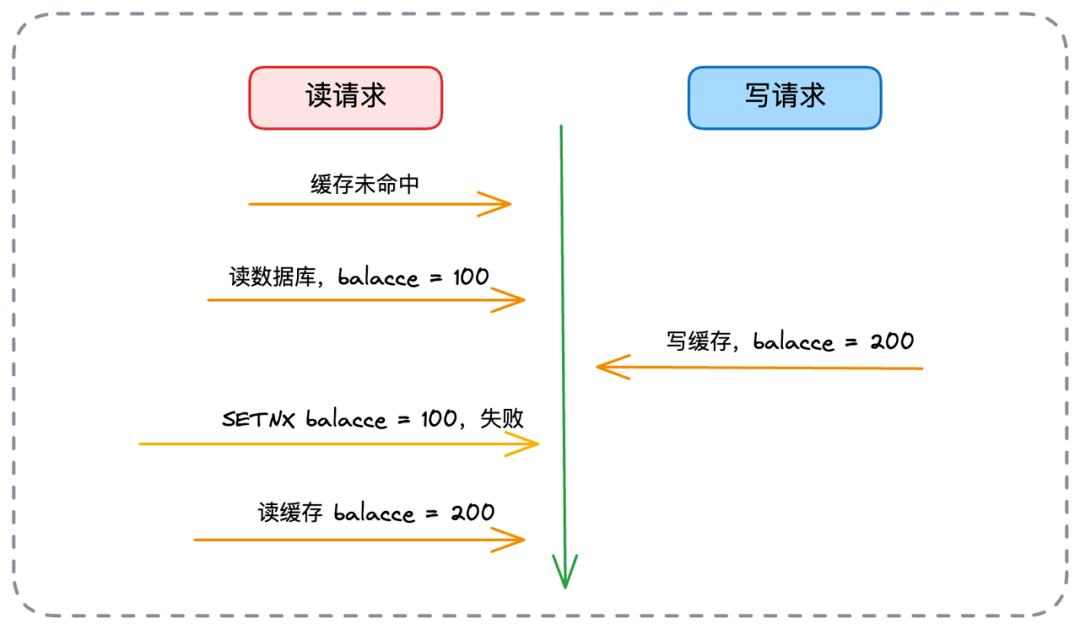
当读请求回填缓存时,不要直接 `SET`,而是用 `SETNX`(Set if Not Exists)。只有当缓存里真的没有数据时,才允许回填。如果缓存里已经有值了(说明被写请求抢先更新了),读请求就放弃回填,直接用缓存里的新值。
最后,你可以用一句总结来一锤定音:
> “因此,Write Back 除了有数据丢失的风险外,在缓存一致性的表现上,其实优于其他模式。”
>
> 这是一个比较激进的观点,使用时要观察面试官的反应。如果他比较保守,你可以改口说:“Write Back 极大地缓解了数据不一致的问题。”
>
# 8\. Refresh Ahead
**Refresh Ahead**(预刷新)模式在 **CDC**(Change Data Capture)技术普及后变得非常流行。简单来说就是:**业务方只管写数据库,通过监听数据库的 Binlog(比如利用 Canal 组件),来异步刷新缓存。**

这种模式把缓存的更新逻辑从业务代码中剥离了出来。但它同样面临并发魔咒。
在数据写入数据库之后、Binlog 被消费并刷新到缓存之前,这段时间窗口内数据是不一致的。更糟糕的是读写并发场景:
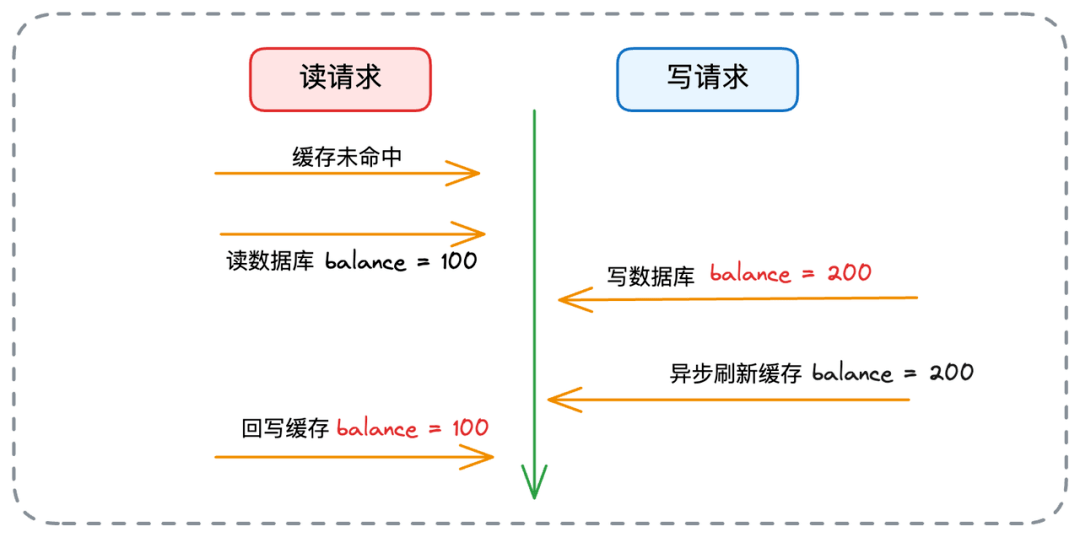
如果读请求在缓存未命中时去查库(查到旧值),恰好此时写请求改了库,并且 Binlog 异步刷新了缓存(新值)。读请求如果晚一步回填缓存,就会把新值覆盖掉。
解决方案和 Write Back 如出一辙:**在读请求回填缓存时,使用 SETNX。** 这样就能完美规避大部分并发导致的不一致。
# 9\. Singleflight
**Singleflight** 严格来说不是一种读写模式,而是一种**流量控制模式**。
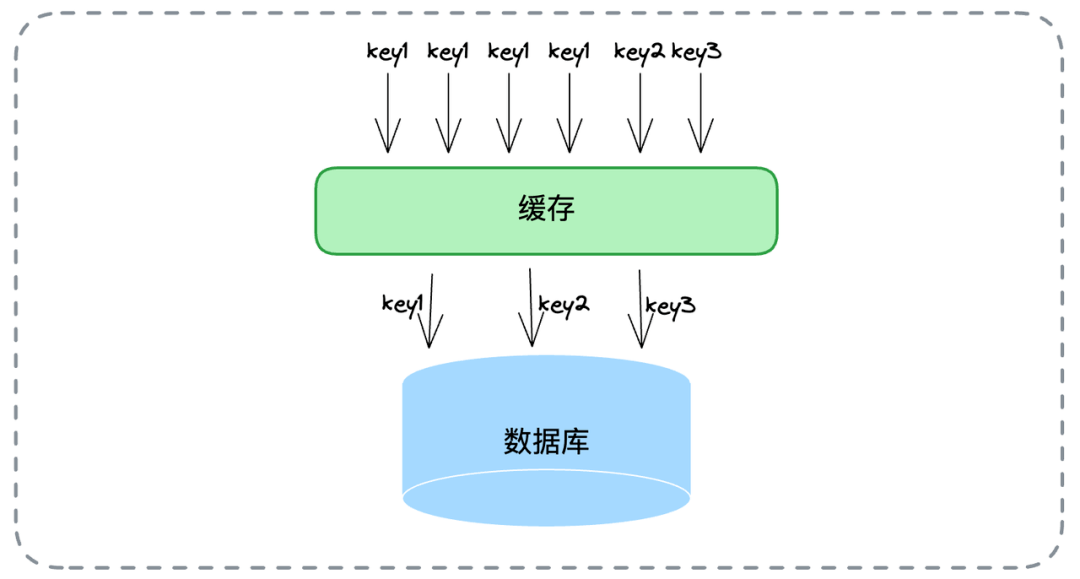
它的原理非常简单直接:**当缓存未命中时,如果同时有一万个请求去查同一个 Key(比如突发热点新闻),Singleflight 机制保证只有一个线程真正去数据库加载数据,其他 9999 个线程都在原地阻塞等待这个结果。**
这个模式的核心价值在于**保护数据库**,防止缓存击穿导致的数据库瞬间雪崩。
它最大的优点是极大地减轻了数据库的并发压力。缺点是如果并发量本来就不高,这套机制就显得有点鸡肋。所以它特别适合**热点数据(Hot Key)** 的场景。
# 10\. 删除缓存
这可能是业务开发中最常见的用法。也就是:**更新数据时,先更新数据库,然后直接把缓存删掉。**
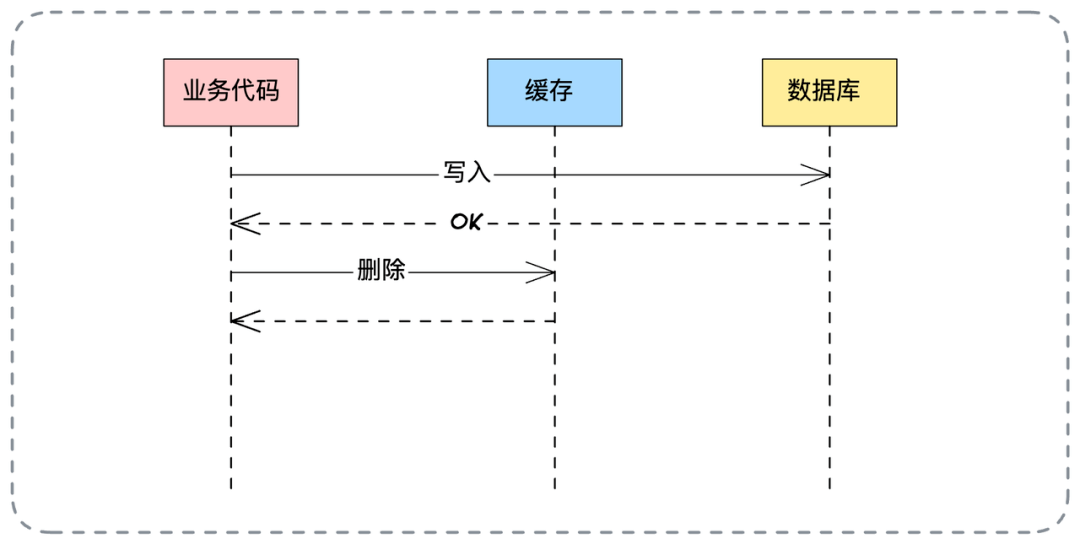
这种做法也可以结合 **Write Through** 模式来做:让缓存组件去更新数据库,然后缓存组件自己把自己删了。
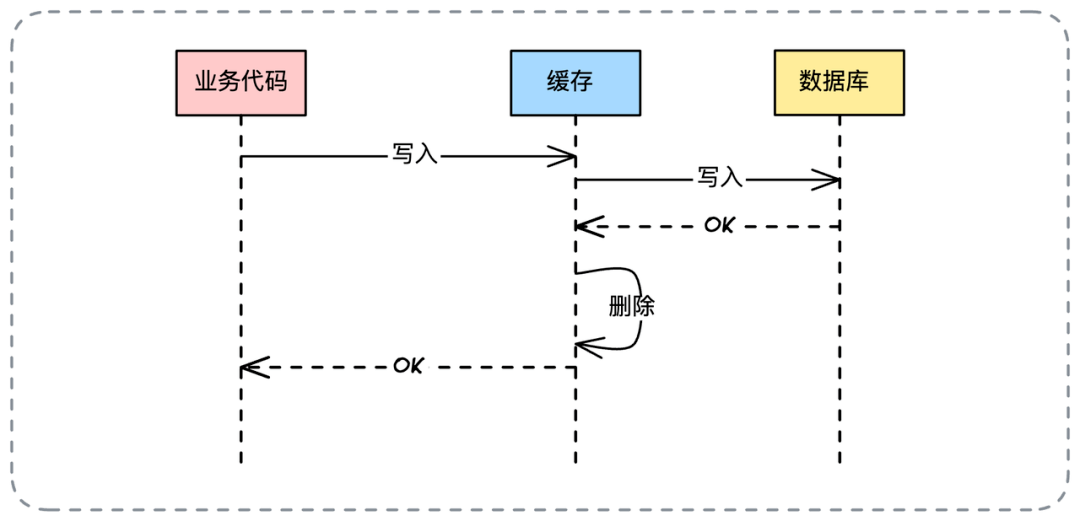
为什么是删,而不是更新?因为“更新”动作可能涉及复杂的计算,而且可能你费劲更新了缓存,结果一直没人读,浪费了性能。删除则是**懒加载**的思想。
但“先改库后删缓存”就没问题了吗?当然有。它的一致性隐患在于:**读线程缓存未命中** 撞上了 **写线程**。
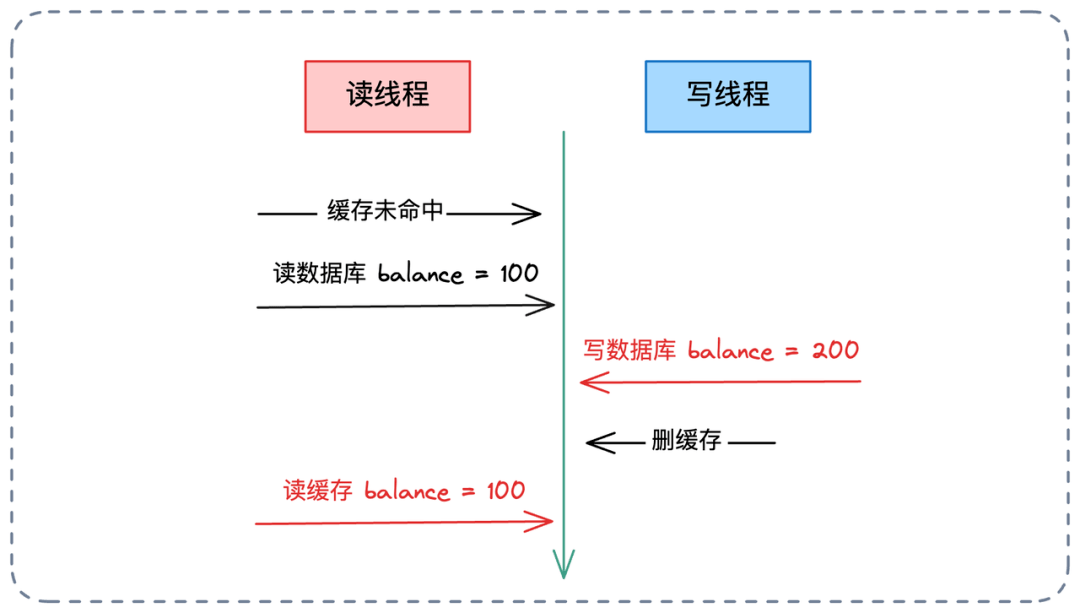
1. **读线程** 发现缓存空了,去查库,查到了旧值(`balance=100`)。
2. 在读线程回填缓存之前,**写线程** 进来了,改了库(`balance=200`)。
3. 写线程为了保证一致性,把缓存删了(虽然此时缓存本来就没数据)。
4. 这时候,**读线程** 才慢悠悠地把刚才查到的旧值(`balance=100`)写入缓存。
结果:数据库是 200,缓存是 100,脏数据出现了。
为了解决这个极低概率但理论上存在的 Bug,架构圈发明了**延迟双删**。
## 10.1 延迟双删
看名字就知道,这个模式要删两次。
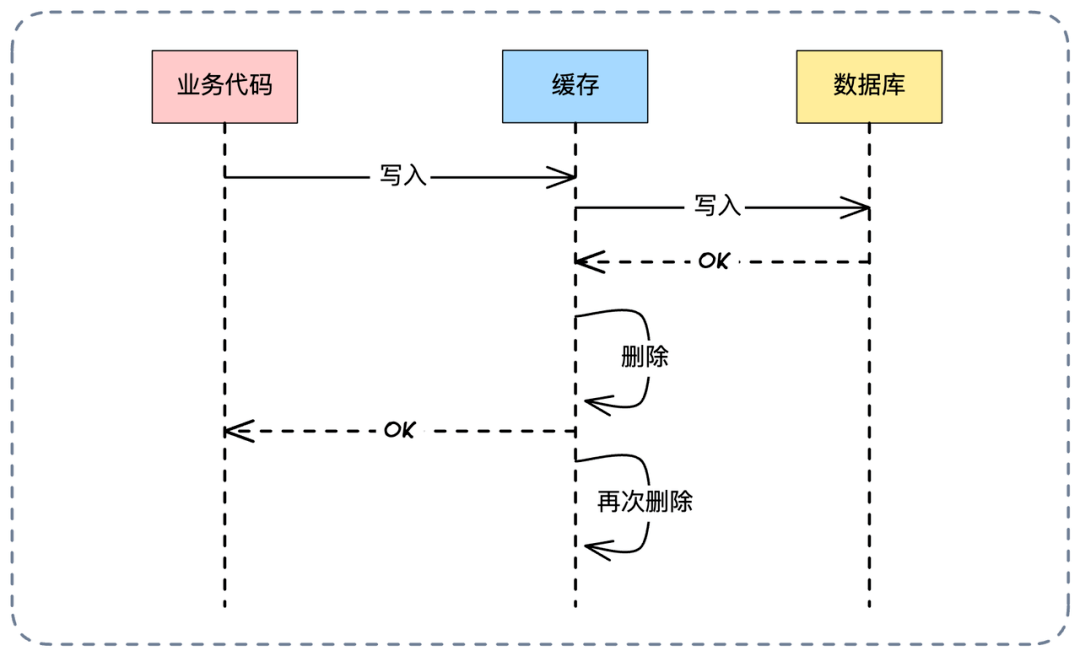
基本流程是:**先删缓存(可选) -> 写数据库 -> 删缓存 -> (休眠 N 毫秒) -> 再次删缓存。**
重点在于这**第二次删除**。为什么要有第二次删除?就是为了防备像上面提到的那个“读线程”把脏数据回写进去。

通过设定一个短暂的延迟(比如 500ms),让读线程有足够的时间把脏数据写完,然后我们再来一次“回马枪”,把这个脏数据删掉。那是不是就绝对完美了?从理论上讲,依然存在极端情况。比如读线程在第二次删除之后才回写缓存,那还是会不一致。

但在现实世界中,这种情况发生的概率比中彩票还低。因为数据库主从同步、网络传输的耗时通常远大于代码执行的耗时,只要你延迟的时间设置得当(覆盖主从同步延迟 + 几百毫秒),延迟双删基本能解决 99.99% 的问题。不过,延迟双删也有代价:
1. **降低了缓存命中率**:因为你删了两次,中间这段时间缓存是空的。
2. **增加了系统复杂度**:你需要维护延迟逻辑。
# 11\. 缓存模式到底该选哪个?
讲了这么多模式,面试官最后肯定会问你:“那在你的项目中,你建议用哪个?”
这时候切忌给出一个标准答案,因为**架构设计没有银弹**。任何一种模式都有缺陷。你可以这样回答:
> “实际上,选择哪种模式取决于业务的具体权衡。
>
>
> - 如果业务对**数据一致性要求极高**(比如金额),我们通常不走缓存,或者加**分布式锁**,但这会牺牲性能。
> - 对于大多数**常规业务**,如果你问我标准答案,我会推荐**延迟双删**。虽然它稍微降低了缓存命中率,但在我们的大部分业务并发量级下,这是一个性价比极高的方案,能覆盖绝大多数一致性问题。
> - 如果是**写多读少**,或者对数据丢失不敏感的统计类业务(如点赞数),我会尝试 **Write Back**。”
>
## 11.1 亮点:用装饰器模式落地缓存模式
光说不练假把式。如果在面试中你想进一步展示你的代码架构能力,可以提一下**装饰器模式(Decorator Pattern)** 。
> 你可以说:“在公司内部,为了避免业务团队乱用缓存模式,我设计了一套统一的缓存 SDK。我定义了一个标准的 `Cache` 接口,然后利用装饰器模式,无侵入地实现了上述的大部分模式。”
>
这里我给出一个 **Read Through** 模式的伪代码实现逻辑,供你参考:
```
// 1. 定义标准接口
type Cache interface {
Get(key string) any
Set(key string, val any)
}
// 2. 定义 ReadThrough 装饰器结构体
type ReadThroughCache struct {
c Cache // 持有基础缓存实例(如 Redis 或 本地内存)
fn func(key string) any // 数据加载函数(回源逻辑)
}
// 3. 实现 Get 方法,植入 Read Through 逻辑
func (r *ReadThroughCache) Get(key string) any {
// 先查缓存
val := r.c.Get(key)
// 缓存未命中
if val == nil {
// 调用回源函数加载数据
val = r.fn(key)
// 回写缓存
r.c.Set(key, val)
}
return val
}
```
你可以这样包装你的项目经历:
> “我把这个设计封装成了通用的中间件。对于业务开发者来说,他们只需要初始化这个装饰器,传入数据加载逻辑,就能自动获得 Read Through 甚至 Singleflight 的能力,既规范了代码,又屏蔽了底层复杂性。”
>
这话说出来,面试官对你的评价绝对会上升一个台阶。
# 12\. 小结
这篇文章我们抽丝剥茧,层层深入地分析了 **Cache Aside**、**同步更新**、**Read Through**、**Write Through**、**Write Back**、**Refresh Ahead** 和 **Singleflight**,以及 **删除缓存** 和 **延迟双删** 策略。但是你要记住,缓存模式虽然多,其核心矛盾永远是**性能与一致性的博弈**。
当你能够清晰地指出每种模式在什么极端并发下会出问题,并且给出 **SETNX** 或 **延迟双删** 这样的解决方案时,你就已经超越了绝大多数候选人。希望这篇文章能帮你打通缓存架构的任督二脉,让你在项目实践和面试过程中都能有所收获
# 学习交流
> 如果您觉得文章有帮助,点个关注哦。秀才后面会在公众号分享**高频场景面试题**的系列知识。同时,我也已经将这些面试场景题文章都整理到了我的学习网站:**https://golangstar.cn**,欢迎大家上我的网站学习,网站学习更高效哦!秀才也为大家精选了一些架构学习资料,学完后从实战,到面试再到晋升,都能很好的应付。**关注秀才公众号:IT杨秀才,回复:111,即可免费领取哦**
>

> **往期推荐**
> [面试官:说说你们分库分表后,主键是怎么生成的?](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:说说你们分库分表后,主键是怎么生成的?-20260224111835-hiuqqso)
> [面试官:微服务场景下,如何实现分布式事务来保证一致性?](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:微服务场景下,如何实现分布式事务来保证一致性?-20260224111835-24y3qzo)
> [面试官:如何保证分布式锁的高可用和高性能?](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:如何保证分布式锁的高可用和高性能?-20260224111836-mx1euhx)
> [面试官:SQL性能调优如何精准定位并解决问题?](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:SQL性能调优如何精准定位并解决问题?-20260224111836-pjzd5ku)
> [面试官:已经有锁了,Mysql为什么还要引入MVCC?](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:已经有锁了,Mysql为什么还要引入MVCC?-20260224111836-uro88om)
> [面试官:为什么MySQL的行锁有时会升级为表锁?](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:为什么MySQL的行锁有时会升级为表锁?-20260224111836-fnw3rf7)
> [面试官:系统重构,旧库数据怎样平滑地迁到新库?](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:系统重构,旧库数据怎样平滑地迁到新库?-20260224111836-earthzx)
> [面试官:高并发场景下,如何处理消费过程中的重复消息?](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:高并发场景下,如何处理消费过程中的重复消息?-20260224111837-gke7ru1)
> [面试官:在使用 MQ 的时候,怎么确保消息 100% 不丢失?](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:在使用MQ的时候,怎么确保消息100不丢失?-20260224111837-co67k7j)
> [面试官:消息队列积压百万,除了加机器还有哪些解法?](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:消息队列积压百万,除了加机器还有哪些解法?-20260224111837-q6uadlh)
> [面试官:如何设计一个十亿级的URL短链系统?](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:如何设计一个十亿级的URL短链系统?-20260224111837-0yyu87y)
> [面试官:如何设计一个百万QPS的限流器?](/uploads/shares/4/assets/笔记同步助手/attachments/面试官:如何设计一个百万QPS的限流器?-20260224111838-m4duju5)
>
> [秀才的网站上线了!](/uploads/shares/4/assets/笔记同步助手/attachments/秀才的网站上线了!-20260224111838-zuqyknt)
> [【2025新版】Go面试真题大合集(含答案)](/uploads/shares/4/assets/笔记同步助手/attachments/【2025新版】Go面试真题大合集(含答案)-20260224111838-2hm1fab)
> [2025最新Mysql面试真题(图文并茂版)](/uploads/shares/4/assets/笔记同步助手/attachments/2025最新Mysql面试真题(图文并茂版)-20260224111838-btz6o08)
> [26届秋招,这些岗位你一定要投!](/uploads/shares/4/assets/笔记同步助手/attachments/26届秋招,这些岗位你一定要投!-20260224111838-nehldc5)
>
---
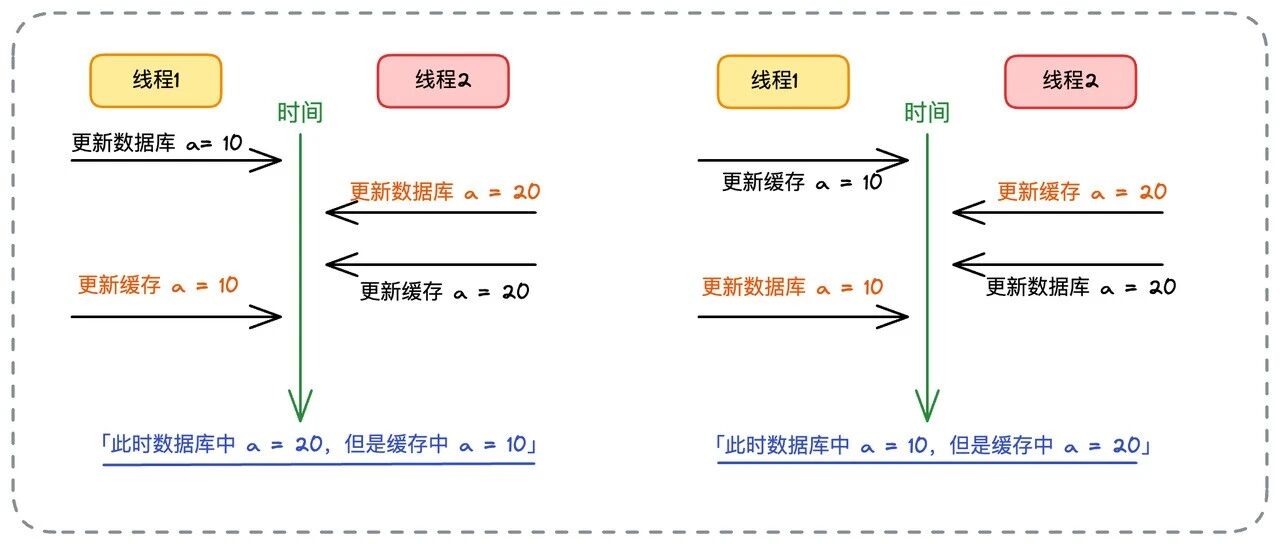
## 面试官:项目中你是采用哪种缓存模式来解决数据一致性问题的?
原创 IT杨秀才 IT杨秀才
继续滑动看下一个

IT杨秀才
向上滑动看下一个[^44]: # 盘点 3 个 AI Agent 相关神级 GitHub 开源项目。
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260224111834-fne9z3i)
## 正文
公众号名称:逛逛GitHub
作者名称:逛逛
发布时间:2026-02-23 15:05
**
01
**让不懂代码的人也能玩转 AI 工作流**
**
说实话,n8n 这种工作流自动化工具虽然强大,但对于非技术用户来说,学习成本还是挺高的。
光是要搞清楚各种节点怎么配置、怎么连接,就够折腾一阵子了。
最近在 GitHub 上发现了一个挺有意思的项目 Refly.AI,它号称是全球首个 Vibe Workflow 平台,专门面向非技术创作者。
这是一个开源的 Agent Skill 搭建神器。

说白了就是让你用自然语言描述想干啥,然后它帮你把 AI 自动化工作流搭建起来,完全不用写代码。

它最大的亮点是可干预的 Agent 执行机制。
传统的 AI Agent 就像黑盒一样,你让它干活,它就在后台自己搞,搞成啥样你也不知道,出了问题也只能干瞪眼。
但 Refly 把每一步都放在可视化画布上展示,你随时可以暂停、检查、修改,甚至重新开始,不用再担心 AI 乱来的问题。

另一个有意思的是它的极简工作流设计。
在 Refly 里,每个节点不是那种需要繁琐配置的小模块,而是一个完整的、开箱即用的 Agent。你只需要给它分配任务、把它们连起来就行。
官方的说法是,用两个节点就能完成 n8n 需要十几个节点才能搞定的事情。
```
开源地址:https://github.com/refly-ai/refly
```
**
02
**多智能体编排神器**
**
用 Claude Code 有时候处理复杂任务还是有点力不从心。特别是涉及到多文件、多模块的大项目,它容易顾此失彼,跑着跑着就跑偏了。
最近发现了一个叫 oh-my-claudecode 的开源项目,专门做 Claude Code 的多智能体编排。
它的理念挺简单的:别学 Claude Code 怎么用,直接用它就行。

它的核心是内置了 32 个专业智能体,涵盖架构设计、代码审查、测试、数据科学等各种领域。
当你给它一个任务时,它会自动判断应该调用哪些智能体,然后协调它们一起干活。
而且它有智能模型路由,简单任务用便宜的模型,复杂推理才用贵的,据说能省 30-50% 的 token 消耗。
它提供了好几种执行模式。Autopilot 是完全自主执行,丢个任务给它就不用管了;Ultrapilot 是加速版,处理多组件系统时能快 3-5 倍;
Ecomode 是省钱版,适合预算有限的情况;Swarm 适合并行处理独立任务;Pipeline 则适合多阶段的顺序处理。
```
开源地址:https://github.com/Yeachan-Heo/oh-my-claudecode
```
**
03
**管理 Claude Skills 的桌面神器**
**
Claude Code 的 Skills 生态最近发展得很快,GitHub 上已经有好几万个开源的 Skills 了。
但问题来了,这么多 Skills 怎么找、怎么装、怎么管理?总不能一个个去 GitHub 上翻吧。
有个开发者做了个 skills-desktop 的桌面应用,专门用来管理 Claude Code Skills。它能帮你浏览、安装、导入 Skills,还能做安全扫描,挺实用的。
这个项目目前支持浏览 6.7 万多个开源 Skills,而且还在持续增长。界面做得挺清爽的,搜索、过滤功能都有,找到想要的一键就能装到本地。
它支持两种导入方式:一种是通过 GitHub 仓库 URL 直接克隆,另一种是从本地文件夹导入已有的 Skills。如果你是开发者,自己写了一些 Skills,用这个工具管理也很方便。
比较贴心的是它的安全扫描功能。装 Skills 之前可以先扫描一下,看看有没有可疑的代码模式,给出安全评分和建议。毕竟 Skills 会跑在你本地环境里,谨慎一点总是好的。
它还支持配置多个项目路径,会自动扫描每个项目下的 .claude/skills 文件夹,跨平台支持 Windows 和 macOS。
技术栈用的是 Tauri v2 做桌面端,前端是 React 19 + TypeScript + Vite 7,UI 用的是 Tailwind CSS 和 DaisyUI,整体比较现代。如果你想在上面做二次开发也很方便。
```
开源地址:https://github.com/Harries/skills-desktop
```
04
**点击下方卡片,关注逛逛 GitHub**
这个公众号历史发布过很多有趣的开源项目,如果你懒得翻文章一个个找,你直接关注微信公众号:逛逛 GitHub ,后台对话聊天就行了:

---
Original 逛逛 逛逛GitHub
继续滑动看下一个

逛逛GitHub
向上滑动看下一个[^45]: # GitHub 55k Star!仅需一个文件,10分钟上线全功能后端
> 还在为部署后端折腾 Docker、配置数据库、撸 Auth 逻辑?这个“单文件”神器,可能让你再也不想写 SQL。
>
## 这玩意儿到底有啥用?
讲真,混迹 GitHub 十年,啥场面没见过?但我看现在的年轻开发者,项目八字还没一撇,就开始卷微服务、K8s、PostgreSQL 集群。结果呢?代码还没写几行,服务器月费先扣了几百块,最后烂尾在环境配置上。**这图啥呢?**
是不是特眼熟?
想给 App 加个登录,结果 OAuth 文档啃了一下午,差点睡着。
想搞个实时聊天,WebSocket 的坑深得能埋人。
就为了存几张破头像,还得去折腾阿里云 OSS 或者 AWS S3。
老铁,醒醒吧!对于 99% 的个人项目,你搞那些微服务纯属大炮打蚊子。**没必要。**
## PocketBase 到底是个啥?
简单说,**PocketBase 就是后端界的全家桶**。
它是用 Go 写的开源后端,最骚的地方在于——**它真的只有一个二进制文件**(对,就一个文件)。
下载,双击,你瞬间就拥有了一个完整的后端。
首先是**嵌入式 SQLite 数据库**(支持实时订阅,跟 Firebase 一样爽,数据一变前端立马知道)。
还有**完整的一套用户认证系统**(登录、注册、找回密码、OAuth2 全都有,不用你自己撸代码了)。
再就是**文件存储服务**(本地存或者一键连 S3,省心)。
最离谱的是它自带个**超好用的管理后台 UI**(可视化增删改查,小白也能上手)。

## 别看个头小,本事可不小
Reddit 上的网友甚至把它称为“穷人版的 Firebase”,但比 Firebase 更自由,因为你可以完全自托管,数据抓在自己手里才踏实。
**实时订阅 (Realtime API)** 这块真的好用,前端监听一下,数据库一变前端秒更新,写聊天室就像开了挂。
最近 v0.23 版本还更新了个杀手锏——**JS 逻辑扩展 (JSVM)** ,你不需要懂 Go,直接写 JavaScript 脚本就能处理复杂的业务逻辑。**牛不牛?**
别瞧不起 SQLite,PocketBase 开启了 WAL 模式,我在普通 VPS 上试过,承载万级用户轻轻松松。
部署更是离谱,Hacker News 上有哥们说,把这唯一的一个文件丢进服务器,运行一下就上线了,完全不需要折腾环境。
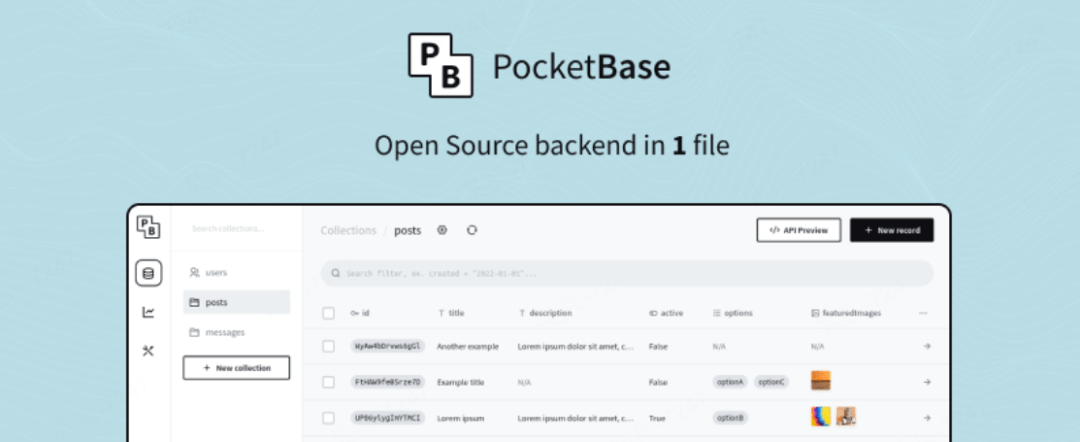
## 上手这事儿,真别想复杂了
说它是单文件,真不是吹牛。Linux/Mac 下面,你就这么搞:
```bash
# 1. 下载并解压(以 Linux 为例)
wget https://github.com/pocketbase/pocketbase/releases/download/v0.23.5/pocketbase_0.23.5_linux_amd64.zip
unzip pocketbase_0.23.5_linux_amd64.zip
# 2. 启动服务
./pocketbase serve
```
完事儿。打开浏览器访问 `http://127.0.0.1:8090/_/`,那个管理后台直接弹出来,美得不行。
前端(比如 React 或 Vue)想接?那代码简洁得我都怀疑是不是在开玩笑:
```javascript
import PocketBase from 'pocketbase';
const pb = new PocketBase('http://127.0.0.1:8090');
// 1秒搞定登录
const authData = await pb.collection('users').authWithPassword('test@example.com', '1234567890');
// 实时监听消息
pb.collection('messages').subscribe('*', function (e) {
console.log('新消息来了:', e.record);
});
```
## 最后唠两句
如果你厌倦了那种为了做一个小功能要配几小时环境的生活,PocketBase 绝对值得你试一试。不过话说在前头,官方 FAQ 里有一句特别硬气的话:“如果你连文档都不愿意扫一眼,只想靠 AI 瞎猜,那请别用 PocketBase!” **傲娇吧?** 但这种有脾气的项目,通常质量都极高。目前它在 GitHub 已经有 55.8k Star 了,火得离谱。
目前它在 GitHub 已经有 **55.8k Star**,社区非常活跃。
**项目地址**:https://github.com/pocketbase/pocketbase
觉得有用就点个 **[在看]** ,关注我获取更多 GitHub 干货,咱们下期见!
[^46]: # OpenCode 中文教程 - AI 编程助手实战指南
## 来源
[原文链接](/uploads/shares/4/assets/笔记同步助手/attachments/原文链接-20260226185329-b5srx9q)
## 正文

## 基于源码解读
不是瞎编的教程,每个功能都基于 OpenCode 官方源码分析[^47]: # 前端最 -丑- 的 UI 组件,Chrome 痛下杀手!
讲真,前端圈里有个公认的“丑八怪”,大家平时骂归骂,但离了它还真不行——就是**滚动条**。这玩意儿以前想改个样式简直难如登天,写一堆 `::-webkit-scrollbar` 还不一定能跨浏览器,搞得人心力交瘁。不过最近有个好消息,`scrollbar-color` 终于转正了,这意味着什么?意味着咱们终于能体面地改滚动条了!**真香!**
它无处不在,丑得让人不忍直视(设计师每次看到默认滚动条都要发飙),以前想优雅定制?门儿都没有。
想改个颜色?以前得写一堆 `::-webkit-scrollbar` 私有前缀,代码冗余得像裹脚布。
想跨浏览器一致?做梦去吧,Firefox 根本不吃那一套。
但现在,这问题算是解决了。

`scrollbar-color` 正式进入 Baseline Newly Available,说白了就是它已经成为跨主流浏览器可用的标准能力,可以放心大胆地在生产环境里搞了。**终于不用怕坑了。**
今天咱们就来唠唠这玩意儿怎么用,别再用那些老掉牙的写法了。
## 这玩意儿到底是啥
`scrollbar-color` 是 CSS Scrollbars 规范里的一个属性,干的事儿很简单:设置滑块(thumb)的颜色,还有轨道(track)的颜色。
- `滚动条滑块`(thumb)的颜色
- `滚动条轨道`(track)的颜色
语法简单到离谱,看一眼就会:
```css
scrollbar-color: <滑块颜色> <轨道颜色>;
```
第一个值给滑块,第二个值给轨道(别搞反了,搞反了也就是丑点,不会报错~)。
举个例子:
```css
html {
scrollbar-color: rebeccapurple green;
}
```
看,就这么直给,没有那些弯弯绕。
## 终于不用写私有前缀了
想想以前咱们怎么写的?那叫一个痛苦:
```css
::-webkit-scrollbar
::-webkit-scrollbar-thumb
::-webkit-scrollbar-track
```
问题一大堆:非标准(那是 Webkit 私自搞的)、Firefox 根本不支持、未来指不定哪天就被浏览器砍了、代码写起来冗余得要死。
- ❌ `非标准`
- ❌ `Firefox 不支持`
- ❌ `未来兼容性不可控`
- ❌ `代码冗余`
但现在看看这两个:
```css
scrollbar-color
scrollbar-width
```
成了标准方案。**终于统一了!**

这意味着啥?Chrome 支持、Firefox 支持、Safari 支持、Edge 也支持,正式进入 Baseline。这对于咱们前端来说,简直就是久旱逢甘霖。
- ✅ `Chrome 支持`
- ✅ `Firefox 支持`
- ✅ `Safari 支持`
- ✅ `Edge 支持`
- ✅ `正式进入 Baseline`
这在前端标准演进里,算是一次真正的“大统一”。
## 上手试试
### 全局搞一套
```css
:root {
scrollbar-color: #1677ff #f0f2f5;
}
```
直接写在 `:root` 里,全站风格瞬间统一,特别适合那种有品牌色要求的设计系统。
### 单独给它上个色
```css
.container {
overflow: auto;
scrollbar-color: #888 #eee;
}
```
这个场景就多了,SaaS 后台、那种密密麻麻的数据表格、左侧的侧边栏菜单,还有那些弹出来的可滚动面板,单独设置一下,体验立马提升一个档次。
- **SaaS 后台**
- **数据表格**
- **左侧菜单栏**
- **可滚动面板**
### 随它去吧
```css
scrollbar-color: auto;
```
如果你不想折腾,或者想尊重用户的系统设置(比如 Mac 用户喜欢那种隐藏式的),那就写 `auto`,别瞎改。
## 还能改粗细
除了颜色,还能控制宽度,这对于细节控来说简直是福音:
```css
* {
scrollbar-width: thin;
scrollbar-color: #1677ff #f0f2f5;
}
```
可选值也没几个:`auto`(默认)、`thin`(细一点)、`none`(隐藏——别乱用这个,用户找不到滚动条会骂人的)。
- `auto`
- `thin`
- `none`
如果你做的是那种数据密集型的后台系统,`thin` 真的能显著提升视觉精致度,不信你试试看?
## 以前那套还要不要写?
如果你的用户群体里还有那种死守着好几年前 Chrome 版本的人(这种用户真的存在吗??),那你可能得做个双写兼容:
```css
/* 标准写法 */
* {
scrollbar-color: #1677ff #f0f2f5;
}
/* 兼容旧浏览器 */
*::-webkit-scrollbar-thumb {
background: #1677ff;
}
*::-webkit-scrollbar-track {
background: #f0f2f5;
}
```
但说实话,为了那一小撮人,我宁愿让他们看默认样式。未来几年肯定是标准写法的天下。
## 这事儿其实没那么简单
`scrollbar-color` 进入 Baseline,其实传递了一个挺重要的信号:**浏览器终于开始正经搞 UI 细节了**。
> 浏览器正在逐步“**标准化 UI 细节控制能力**”。
>
以前很多 UI 微调都得靠私有实现(或者各种 Hack),写起来心累。
现在你看,`CSS Scrollbars` 有了,`Accent Color` 有了,`Color-scheme` 有了,连 `Container Queries` 都稳定了。这些能力正在慢慢变成标准。
- `CSS Scrollbars`
- `Accent Color`
- `Color-scheme`
- `Container Queries`
前端工程终于变得更“可控”了一点,不用再天天跟浏览器厂商斗智斗勇了。
前端工程正变得更 **“可控”** 。
## 最后唠两句
总结一下现状:它是标准规范的一部分了,主流浏览器都支持,进了 Baseline,生产环境随便用。
- **标准规范的一部分**
- **主流浏览器支持**
- **已进入 Baseline**
- **可以安全用于生产环境**
它解决的其实不是什么惊天动地的大功能,而是长期困扰咱们前端工程师的“细节控制权”问题。
当 UI 的每一个像素都能被你拿捏的时候,设计系统才算真的闭环了。**懂的都懂。**
MDN 文档奉上:[scrollbar-color API 文档](https://developer.mozilla.org/en-US/docs/Web/CSS/Reference/Properties/scrollbar-color)[^48]: # 稳如老狗、节省成本的 AI 编程工作流实战指南
## 引言
人工智能逐渐渗透到软件开发,很多人宣称“一行代码都不需要写”。然而,真正可持续的AI编程应当兼顾代码可维护性、成本与开发者成长。本文分享一种“稳如老狗、节省成本”的AI编程工作流程,并通过已上线的独立游戏实例进行实战演示。

视频开场标题《一个稳如老狗又省钱的AI编程工作流程》
该思路最初来源于 GitHub 上备受关注的 *SpecCoding* 项目,作者在实际工作中对其进行改进并成功用于自己的独立游戏。
SpecCoding 项目示意图
## 流程的核心优势
- 代码结构清晰、易于迭代,适合游戏等多轮玩法项目。
- Token 消耗约为传统方案的三分之一,成本显著降低。
- 通过明确的模块划分与自动化测试,提升开发者的系统设计能力。

成本对比:云模型 vs 国产 GLM 模型
## 完整工作流程概览
### 第一步:分块编写需求文档
和 SpecCoding 相同,首先撰写需求文档。但不必一次性描述完整产品,而是将需求拆分成若干独立块。例如,对一款战棋游戏,先聚焦核心的战斗场景。
在此阶段,AI 可以通过提问帮助细化需求,且不必在代码生成工具中进行,避免额外的 Token 消耗。常用免费版的 ChatGPT(如 gpt‑3.5)或 LLaMA 等都可以胜任。

需求文档分块示例
### 第二步:编写框架代码
框架代码仅包含接口与数据结构的声明,不实现业务逻辑。它为后续的 AI 自动生成代码提供明确的“规格说明书”。
在实际项目中,框架代码的写作遵循以下四条原则:
- 将项目拆分为 1000 行代码以内的可实现小模块。
- 每个模块仅关注自身功能。
- 将可独立测试的部分抽离,使 AI 能通过单元测试自行验证。
- 模块之间只能依赖接口,禁止直接依赖实现。

框架代码示例(仅接口与数据结构)
### 第三步:AI 实现与自动化测试
在拥有完整的需求块与框架代码后,指示 AI 按块生成对应实现,并同步编写相应的单元测试。借助测试用例,AI 可以自行校验代码的正确性,显著降低错误率。
测试策略如下:
- State 层(仅数据存取)几乎无需测试。
- Action 层通过独立的测试验证对 BattleState 的修改及产生的事件。
- Controller 层因涉及 UI,测试成本最高,通常在整体集成时一次性验证。
- EventHandler 层使用 Mock 替代真实的 Controller,实现全自动化测试。
自动化测试采用“Mock”技术,将依赖 UI 的组件替换为空实现,从而在纯代码环境下完成验证。
## 实战案例:卡牌+战棋游戏的模块拆分
以下示例源自作者在 Steam 上发布的试玩版独立游戏。
项目主要分为四层结构:
- **BattleState**:仅负责存储战斗状态,如棋盘格子 occupant、单位血量、双方手牌等。
- **Action**:实现具体行为(移动、攻击、使用手牌),接受 BattleState 作为参数并返回事件集合。
- **EventHandler**:根据 Action 产生的事件调用 Controller,完成 UI 更新。
- **Controller(或 UI 层)** :将屏幕组件封装为可操作的模块,提供外部接口。

游戏模块划分示意图:BattleState、Action、EventHandler、Controller
## 为何这种拆分能显著降低 AI 错误率
每个模块的职责单一、代码量有限,使得 AI 在生成代码时无需处理大量上下文信息。
此外,模块要么不需要测试(纯数据层),要么可以通过 AI 自己编写的单元测试验证(行为层),从而形成闭环,错误几乎可以在生成阶段被捕获。
## 与 AI 协作的实用技巧
- 在进入实现阶段前,务必先让 AI 完整解释其设计思路,确保你理解每个模块的实现方式。
- 通过提问确认每个模块的自动化测试方案是否可行。
- 将约束规则写入专门的约束文件(如 `cloud.md`),防止 AI 在实现过程中自行修改接口。
- 在生成代码后快速比对实现是否偏离框架规范,必要时在约束文件中加入额外限制。
## 收益与思考
该流程不仅将 Token 消耗降低至约 1/3,还帮助开发者在与 AI 互动的过程中形成系统设计与问题拆解的思维模型。这种能力是 AI 时代专业开发者与业余用户的核心差异。
未来 AI 是否会在架构层面取代专业人士仍有争议,但掌握上述工作流无疑能够提升你在 AI 辅助开发中的指挥力。
## 结语
如果你在 AI 迅猛发展的时代仍保持冷静与务实,欢迎关注作者的账号,获取更多实用且不夸张的技术分享。
[^49]: # 快速实现 Vue3 二维码生成:qrcode-vue3 使用指南
讲真,Vue3 里搞个二维码这事儿,我之前踩过不少坑。市面上那些库要么重得离谱,要么文档写得像天书(有些库的文档我看了三遍都没看懂,服了)。不过最近挖到了个宝贝——qrcode-vue3,这玩意儿用起来是真的顺手。我试了半个月,除了偶尔手滑写错参数(别笑,谁没犯过蠢),基本没出过什么幺蛾子。今天就把我踩坑的经验摊开了说。**省得你们再走我走过的弯路~**
## 这玩意儿到底是啥来头?
简单说下,这货就是专门给 Vue3 造的(Vue2 的兄弟们别凑热闹,用错了别怪我没提醒)。基于 QRCode.js 那个老牌库改造的,但作者明显是懂 Vue3 Composition API 的,用起来那叫一个丝滑。**最关键的是体积小得离谱**,我项目里加了之后打包体积涨了几乎可以忽略不计(gzip 压完才几 KB,比一张图片还小)。
还有个事儿挺爽,这组件没啥乱七八糟的依赖。我之前试过一个库,引入之后连带拽进来十几个包,差点把我整崩溃。这个就好多了,干净。
样式这块你想怎么改都行(我是挺喜欢这种自由度的)。尺寸、颜色、容错率都能调,哪怕你要做个彩虹二维码也没人拦着你~
跟 Vite、Webpack 这些工具配合得也没话说,我两个项目(分别用的两种打包方案)都试过,一次就跑通了。这点比隔壁某些库强多了(点名批评某库,配置文档写了几千字照样报错)。
数据绑定也是实时的,你改了值二维码立马跟着变。这点在做动态链接场景的时候特别有用,我上周搞了个活动页就是这么干的,体验比之前那个傻傻手动刷新的好太多了。
## 先装上再说
安装这步没啥好说的,npm 就完事了(我用的是 pnpm,速度确实快不少,推荐试试)。
首先确保你的项目是 Vue3 环境(Vue2 项目不兼容),在项目根目录执行以下命令安装:
```bash
# 我习惯用 npm
npm install qrcode-vue3 --save
# 或者你试试 pnpm(真香警告)
pnpm add qrcode-vue3
```
对了,`--save` 这个参数其实可以省了(新版 npm 默认就加 dependencies),但我还是习惯写上,算是强迫症吧~
## 环境这块提一嘴
Vue3 是必须的,3.0 以上都能跑(但我还是建议你升到 3.2+,新特性香啊)。我之前有个老项目死活装不上,折腾了半天才发现是 Vue2……**这尴尬的**。
打包工具基本不用操心,Vite、Webpack 5 都能直接用。Webpack 4 的同学……要不你考虑升级一下?都 2026 年了兄弟。
也不用额外装 QRCode.js,作者已经把核心功能打包进去了,省心。
## 搞起:怎么用
### 先说说全局注册这招(适合懒人)
在 `main.js` 里写几行就行,一次配置到处用。我那种中小项目基本都是这么干的,省得每个页面都引入一遍。
```javascript
// main.js
import { createApp } from 'vue'
import App from './App.vue'
import QrcodeVue3 from 'qrcode-vue3'
const app = createApp(App)
app.component('QrcodeVue3', QrcodeVue3)
app.mount('#app')
```
### 局部注册也行
要是就一个页面要用,那就局部引入吧。反正我现在的习惯是看项目大小决定,小项目全局,大项目局部(大项目引入太多全局东西容易炸)。
```javascript
// 组件里直接引入
import QrcodeVue3 from 'qrcode-vue3'
import { ref } from 'vue'
const qrcodeValue = ref('https://www.example.com')
```
## 那些能调的参数
这组件的参数其实挺多的,但我常用的也就那么几个(大部分时间默认值就够用了)。重点说几个你可能用得上的:
|参数|啥意思|默认值|
| -------------| ----------------------------------| ----------|
|value|二维码内容(必填,啥字符串都行)|''|
|size|尺寸(宽高一样)|128|
|color|前景色(就是那些黑块块的颜色)|'#000'|
|bg-color|背景色|'#fff'|
|error-level|容错率(L/M/Q/H,H最高)|'M'|
|margin|内边距|1|
|render-as|渲染方式(canvas/svg)|'canvas'|
### 搞个高清的 SVG 二维码
```javascript
import QrcodeVue3 from 'qrcode-vue3'
import { ref, onMounted } from 'vue'
const dynamicValue = ref('')
// 模拟异步获取二维码内容
onMounted(() => {
setTimeout(() => {
dynamicValue.value = JSON.stringify({
userId: 10086,
userName: '测试用户',
time: new Date().getTime()
})
}, 1000)
})
```
## 踩坑实录
### 改了值二维码不变??
这个问题我之前遇到过,原因挺蠢的——我直接改了变量值,忘了用 `.value`。Vue3 的 ref 你不这么写它根本没反应~
```javascript
// 错误写法(别这么干)
let qrcodeValue = '旧内容'
qrcodeValue = '新内容'
// 正确写法
const qrcodeValue = ref('旧内容')
qrcodeValue.value = '新内容'
```
### 手机上看起来糊得一批?
果断切 SVG 模式,或者把 size 调大点再用 CSS 缩小。我试过把 size 设成 512 然后缩放到 128px,效果比直接设 128 好太多了(就是稍微占点性能,看你自己取舍)。
### 安装失败了??
先看看是不是 npm 源的问题,国内建议切淘宝源:
再确认一下你是不是 Vue2 项目(很多人这坑都踩过)。Vue2 别装这个,装 `qrcode-vue`(注意名字差了后缀)。
还不行就清理下缓存:`npm cache clean --force`,重试一遍基本就好了。
## 最后唠两句
说实话,qrcode-vue3 这东西我是真用爽了。安装简单,配置灵活,关键是稳定(我用到现在还没崩过)。你要是 Vue3 项目要做二维码,闭眼选这个准没错。**省下来的时间去摸鱼它不香吗~**
### 总结一下优点(省得你们翻回去看)
轻量,干净,没那些乱七八糟的依赖
想咋改就咋改,样式参数给得很足
SVG 模式高清无敌,Canvas 模式性能好,看你需求选
[^50]: # [深度解析] 时薪48美元的赛博苦力:马斯克为何让AI洗碗?
## 来源
[原文链接](https://www.bilibili.com/video/BV1krADzMEJj/?share_source=copy_web&vd_source=332cbfef5943d5ef55ba848756ad9b81)
## 正文
作者: PlanJ\_
# 时薪48美元的赛博苦力:马斯克为何让AI洗碗?
## 引言:特斯拉异常招聘
2024年夏天,特斯拉在加州帕洛阿尔托公开了一则时薪48美元的赛博苦力职位。该岗位不要求学历或编程能力,只要求身高在1.7至1.8米之间。

视频开场:2024年夏季,加州帕洛阿尔托街景
招聘信息中列出了具体的工作内容:背负数十斤设备,穿戴动作捕捉套装与摄像头头盔,在模拟的假厨房中连续8小时进行洗碗、叠衣、做家务等任务。

特斯拉招聘页面截图,显示时薪48美元的赛博苦力职位

职位要求中的时薪48美元每小时标示

招聘要求中的身高限制:1.7至1.8米

工作任务示意:背负设备、穿动作捕捉套装、连续8小时洗碗等
## AI 与物理世界的鸿沟
在同一时空,人工智能已经能够在几秒内编写上万行代码、生成好莱坞级视频,却在真实的三维世界里表现得像一个连玻璃杯都端不稳的笨拙巨婴。

对比AI在数字世界的全能与在物理世界的笨拙表现

AI已接近神性:大模型瞬间完成复杂任务的示意

AI在物理世界的失败示例:无法稳稳端起玻璃杯
## 莫拉维克悖论:轻易与艰难的反差
20世纪80年代,汉斯·莫拉维克等人工智能先驱揭示了“莫拉维克悖论”。对计算机而言,象棋、微积分等抽象任务只需极少算力;而对人类轻易完成的抓杯子、穿针引线等动作,却需要数十亿年的进化成本。

汉斯·莫拉维克肖像,悖论提出者
捕捉杯子的动作涉及对重力、摩擦、材质形变以及空间几何的瞬时计算,这些物理常识是人类在数十亿年进化中烙印的。

人类抓取杯子背后演算的物理过程示意

机器人在执行相同任务时面临的算力天堑图示
## 规则式机器人:代码穷尽的幻梦
传统机器人试图用大量的 if‑then 规则穷举所有可能的物理情形。例如“如果摄像头看到杯壁边缘,则张开机械爪;如果杯子满,则增大电机力度”。在实验室的结构化环境中或许可行,却在真实家庭餐桌上因玻璃、塑料、热水乃至猫的干扰频频失效。

if‑then 代码示例用于机器人抓取杯子

真实厨房场景中变量导致机器人抓取失败的案例
## 长尾效应:无穷变量的挑战
真实世界充满不可预知的极端情形:万圣节深夜,一个穿霸王龙皮套、踩独轮车的醉汉横穿马路;高速公路上装满红灯的平板卡车奇怪摆动……这些稀有场景构成了长尾效应,任何有限的规则集都难以覆盖。

长尾情景演示:穿霸王龙皮套的独轮车骑手在万圣节横穿马路
## 马斯克的暴力决定:删掉30万行代码
面对规则化的失败,马斯克在2023年决定彻底抛弃既有规则。当时特斯拉自动驾驶系统FSD迭代至V12,团队一次性删除了超过30万行手写的C++控制代码,转向更为数据驱动的学习方式。

马斯克宣布删除30万行代码的新闻截图或代码编辑界面

显示删除的30万行代码量的统计图表
## 语言模型的填空学习与视频预测
ChatGPT等大型语言模型的核心是填空预测:在海量文本中学习下一词的概率分布。类似的思路被用于视频预测模型,系统通过观看成千上万的行驶视频,学习下一帧会出现什么画面。

ChatGPT填空学习示例:文字预测的示意图
例如当系统看到路边滚动的皮球时,虽然传统规则会认为无危害,但通过视频学习,它能预测球后面可能出现追逐的儿童,从而提前刹车。

视频预测模型示例:AI在看到球后预测出现儿童并做出刹车决策
## 影子模式:特斯拉车队的真实数据采集
特斯拉约900万辆在役车辆在运行时同步生成完整的感知、决策与控制数据,这一过程被称为“影子模式”。这些数据实时上传至位于德州奥斯汀的Cortex超级计算中心,构成了规模空前的真实驾驶数据飞轮。

特斯拉车队实时采集的影子模式数据示意图或全球分布地图

数据飞轮示意:从道路上传至Cortex超级计算中心的闭环过程
## 数据规模与迭代速度
截至2026年初,影子模式累计已超过1320亿公里的驾驶里程,相当于绕地球赤道约32.9万圈。每天约有3200万公里的试错经验被喂入AI大脑,使FSD迭代速度呈指数级提升。

累计1320亿公里驾驶里程的可视化图表
## 将FSD大脑移植至Optimus机器人
马斯克将特斯拉最新的FSD硬件与基于Transformer的端到端视觉模型直接植入Optimus机器人的胸腔,使其能够在三维空间中进行复杂操作,如稳稳端起摇晃的红酒或捏起脆弱的鸡蛋。

Optimus机器人胸腔内安装的FSD硬件与视觉模型示意图
## 自由度的鸿沟
FSD大脑原本只需控制方向盘、油门、刹车三个自由度;而Optimus机器人拥有28个躯干自由度和22‑27个手部自由度。要在毫秒级完成上百条神经网络运算,对硬件与算法都是极限挑战。

自由度对比图:汽车(3 DOF) vs Optimus(28+ DOF)
## 赛博苦力:用人类运动捕捉填补数据鸿沟
为获得高精度的运动学映射,特斯拉以每小时48美元的实薪雇佣身高符合要求的“赛博苦力”。他们穿戴动作捕捉皮套和触觉手套,在搭建好的假厨房中完成洗碗、叠衣等动作。传感器记录每一次手指的角度、力度与轨迹,将这些数据转化为机器人所需的22‑27自由度控制指令。

赛博苦力在假厨房中进行洗碗的动作捕捉场景[^51]: # 老板让我做搜索功能,我不屑:“一句 SQL 不就搞定了?” 结果老板下跪:“给你n+5,求你走吧!”
## 来源
[原文链接](https://mp.weixin.qq.com/s/erKUvZdnx81zZV0G9sj27w)
## 正文
公众号名称:程序员鱼皮
作者名称:程序员鱼皮
发布时间:2026-03-03 11:25
原文链接:[https://www.codefather.cn](https://www.codefather.cn)
你是小阿巴,刚入职的后端程序员。
这天,产品经理给你安排任务:阿巴阿巴,咱们网站要加一个文章搜索功能。
你心想:简单,直接写一句 SQL 查询数据库就搞定了~
```
SELECT * FROM article WHERE title LIKE '%关键词%'
```
结果上线没几天,就收到了大量用户的投诉!
- 怎么什么搜索结果都没有啊?
- 搜索结果乱七八糟,我想找的那篇内容竟然排在最后面?
- 搜索一次竟然要等好几秒才出结果?什么破系统!
你汗流浃背了:明明 SQL 写对了啊,难道是 MySQL 数据库不行?

这时,号称 "后端之狗" 的鱼皮路过。他瞄了一眼你的代码,嘲笑道:肯定要用 Elasticsearch 来做搜索功能啊!
你一脸懵:Elasticsearch?那是啥?

## 第一阶段:认识 Elasticsearch
鱼皮:**Elasticsearch** 简称 **ES**,是一个专门为搜索而生的分布式数据库,也叫 **搜索引擎数据库**。
它能存储和管理大量文本数据,提供快速、准确、灵活的全文检索功能。你刚才用 `LIKE` 查询搞不定的那些问题,用 ES 都能轻松解决。
你挠了挠头:真有这么神?
鱼皮:当然。打个比方,MySQL 就像图书馆的书架,书按照分类整整齐齐地摆放着,你想找某本书得自己一排一排去翻;而 ES 就像图书馆的电子检索系统,你输入关键词,它立刻就能告诉你书在哪儿,还会把最相关内容的排在最前面。

像全文搜索、日志分析、数据统计这些需要搜索能力的场景,ES 都能轻松搞定。

你眼前一亮:听起来有点儿夯啊,那我赶紧装一个试试。
## 第二阶段:实战应用
### 安装 Elasticsearch
机智如你,直接打开 ES 官网 下载了安装包:

并且成功安装运行:

你:安装好之后,我怎么操作它呢?
鱼皮:ES 本身提供了 RESTful API,默认在 9200 端口提供服务,你可以用 curl 命令或者 Postman 等接口测试工具直接发 HTTP 请求来操作它。

不过对新手来说,更推荐先安装一个官方的可视化工具 **Kibana**。
有了它,你可以直观地查看分析数据、对数据进行操作。
只需要到官网下载安装包并运行,启动之后访问本机的 5601 端口,就能打开 Kibana 的管理界面了。在开发工具控制台里,你可以直接输入查询语句,能够立刻看到结果,非常方便。
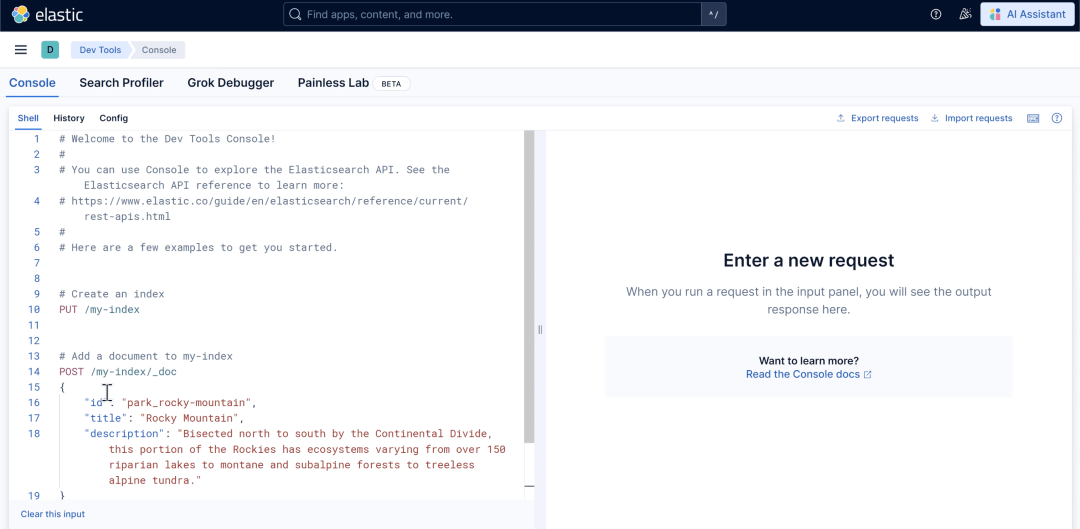
### 基本操作
下面我来带你实操一波 ES 的基本操作。
1)首先是 **创建索引**。ES 的 **索引(Index)** 相当于 MySQL 里的表,是存放数据的容器。
创建索引的时候,还要定义 **Mapping(映射)** ,类似 MySQL 的表结构,用来规定每个字段的类型、是否需要分词、使用什么分词器等等。
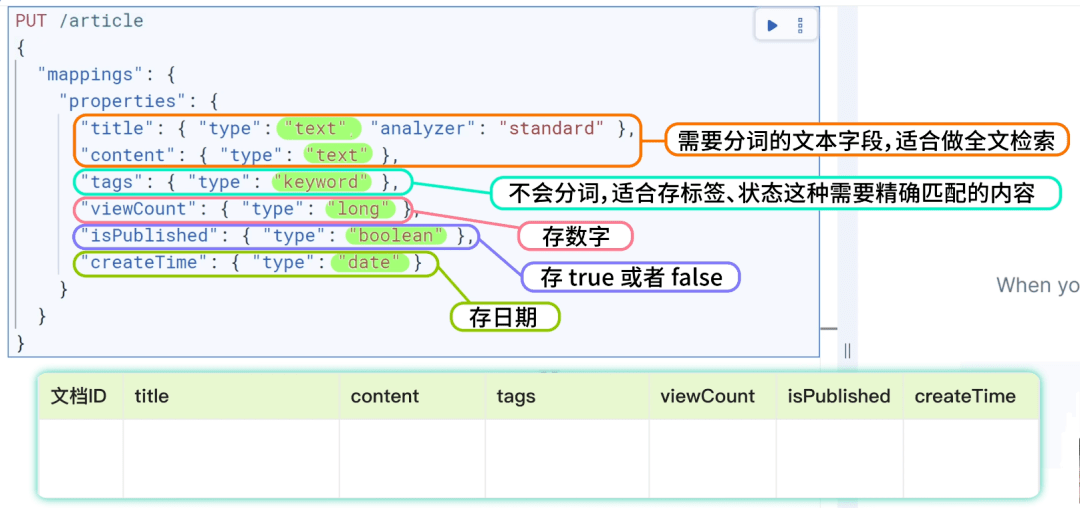
在 Kibana 开发工具中输入这段代码:
```
PUT /article
{
"mappings": {
"properties": {
"title": { "type": "text", "analyzer": "standard" },
"content": { "type": "text" },
"tags": { "type": "keyword" },
"viewCount": { "type": "long" },
"isPublished": { "type": "boolean" },
"createTime": { "type": "date" }
}
}
}
```
这段代码创建了一个叫 `article` 的索引。其中 `text` 类型表示需要分词的文本字段,适合做全文检索;`keyword` 类型不会分词,适合存标签、状态这种需要精确匹配的内容。其他的类型就比较好理解了,`long` 存数字,`boolean` 存 true 或者 false,`date` 存日期。设计索引的时候要根据业务需求合理选择字段类型。
2)然后是 **插入文档**。**文档(Document)** 相当于 MySQL 里的一行数据。ES 的文档是用 JSON 格式存储的,不需要像 MySQL 那样提前定义好所有字段,而是随时可以加新字段,非常灵活。
```
POST /article/_doc/1
{
"title": "鱼皮的 Elasticsearch 入门教程",
"content": "鱼皮带你学习 ES",
"cover": "封面图地址",
"tags": ["ES", "搜索"],
"viewCount": 1000,
"isPublished": true,
"createTime": "2025-01-30"
}
```
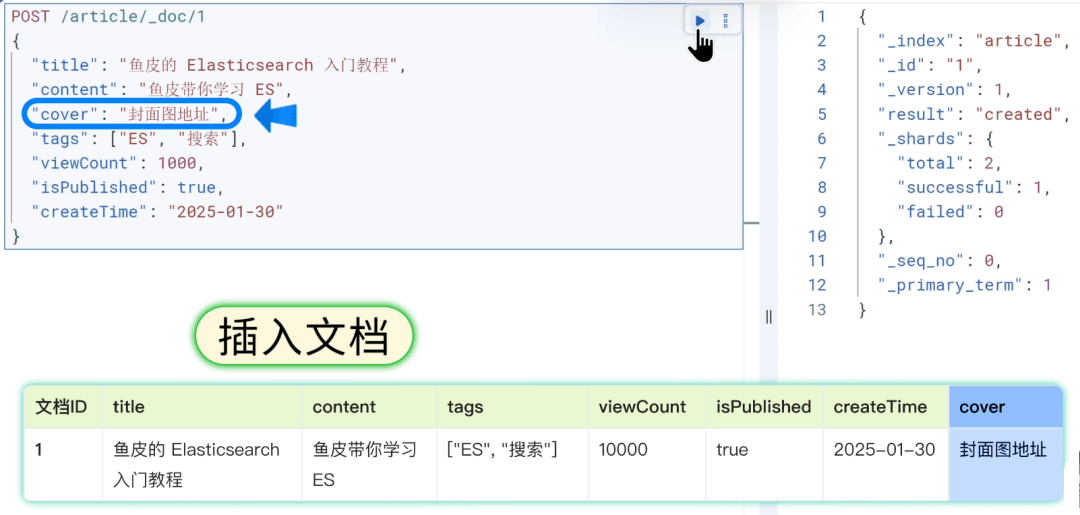
3)有了数据之后,就可以体验 ES 最核心的能力 **搜索文档**。比如在 `article` 索引中搜索标题包含 "鱼皮教程" 的文章:
```
GET /article/_search
{
"query": {
"match": { "title": "鱼皮教程" }
}
}
```
你执行完这条查询,惊喜地发现:搜 "鱼皮教程" 居然能匹配到 "鱼皮的 ES 入门教程" 这篇文章!
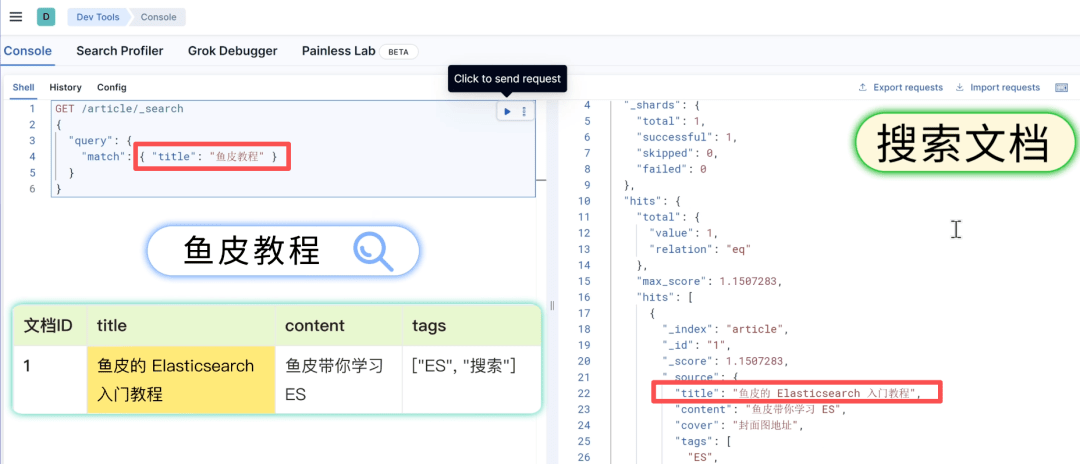
鱼皮点点头:虽然标题里并没有 "鱼皮教程" 这 4 个连着的字,但因为 ES 会自动分词,把 "鱼皮" 和 "教程" 拆开分别匹配,所以就搜到了。

你感叹道:哇,这才是搜索该有的样子啊!
### 查询语法 DSL
鱼皮:没错,ES 的搜索能力非常灵活强大。刚才你写的那些操作语句,其实用的就是 ES 的 **DSL**(Domain Specific Language 领域特定语言)。就像学数据库要学 SQL 一样,学 ES 就得学 DSL。不管是创建索引、插入文档,还是搜索查询,都是用这套 JSON 格式的语法来描述的。

其中最常用的就是查询语法,常见的查询类型有这么几种:
- `match` 是全文检索,会对搜索词分词之后再匹配
- `term` 是精确匹配,不分词,适合查 id、状态这种
- `bool` 可以组合多个条件,用 `must`(必须满足)、`should`(最好满足)、`must_not`(必须不满足)来灵活控制
- `range` 用来做范围查询,比如查某个时间段内的数据。
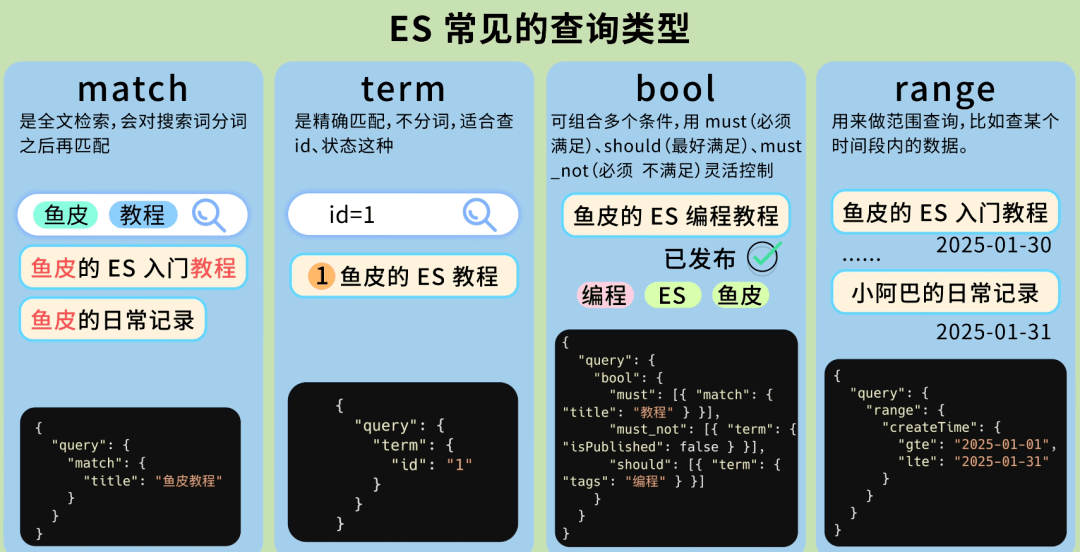
你不需要背这些语法,用到的时候问 AI 或者查文档就行,多写几次就熟了。
### 用代码操作 ES
你皱了皱眉:感觉写这些 JSON 格式的 DSL 还是有点麻烦啊,我用 Java 代码操作 ES 的时候,总不会也要手动拼这堆 JSON 吧?
鱼皮:当然不用!ES 官方提供了各种语言的客户端。比如你用 Java 语言,对应的是 **Java API Client**,支持链式调用和类型安全。
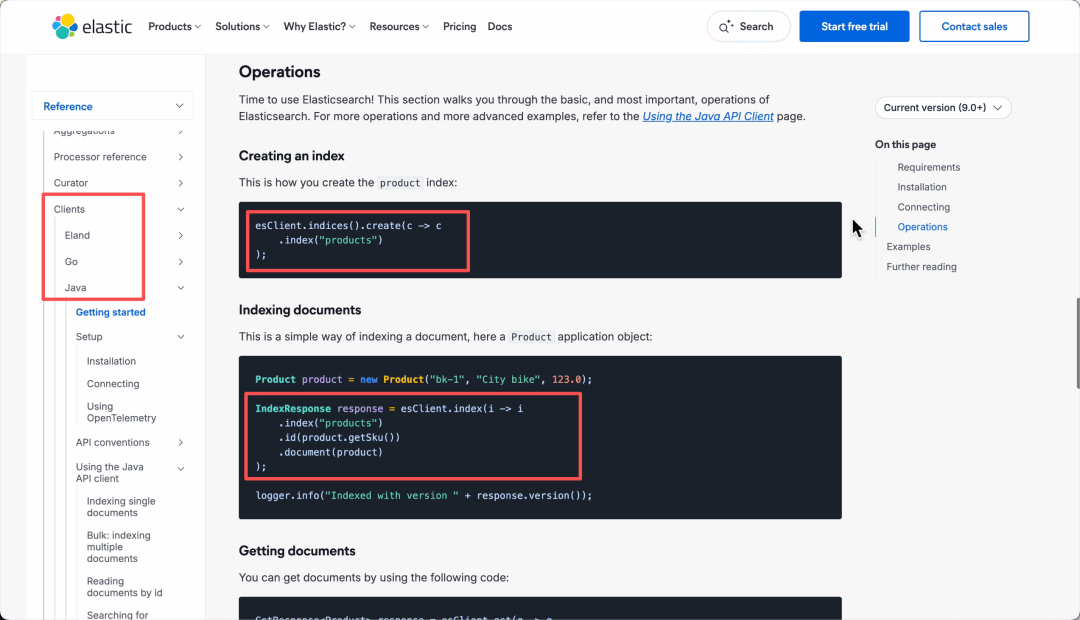
对于 Spring 项目来说,更推荐用 **Spring Data Elasticsearch**,它可以让你像用 MyBatis-Plus 操作 MySQL 一样操作 ES。只需要定义一个实体类,加上 `@Document` 注解指定要操作的索引,再写个 Repository 接口继承依赖包内置的 ES 操作接口。
```
@Document(indexName = "article")
public class Article {
@Id
private Long id;
private String title;
private String content;
}
public interface ArticleRepository extends ElasticsearchRepository {
// 根据标题搜索
List
```
框架会根据方法名自动生成查询逻辑,基本的增删改查方法就自动实现了。
```
// 使用示例
// 插入文档
articleRepository.save(article);
// 根据 id 查询
articleRepository.findById(1L);
// 根据标题搜索
articleRepository.findByTitle("鱼皮");
// 删除文档
articleRepository.deleteById(1L);
```
你感叹道:这才是人写的代码啊!优雅,真是优雅~ 我这就给 Java 代码整上 ES!
鱼皮:要注意,ES 版本更新很快,你用的客户端版本要跟安装的 ES 服务保持一致,不然会出各种奇奇怪怪的 Bug。
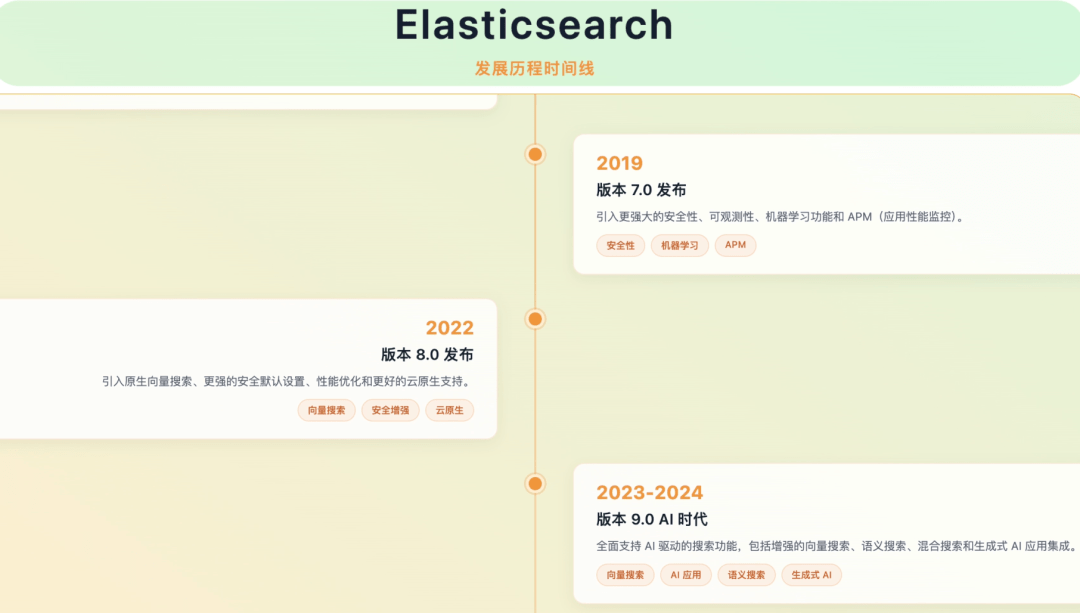
## 第三阶段:实用特性
学会了基本操作之后,你兴冲冲地把 MySQL 数据库里的文章数据全部导入到了 ES,然后把网站的搜索功能改成从 ES 查询。上线后效果立竿见影,搜索又快又准,用户好评如潮。
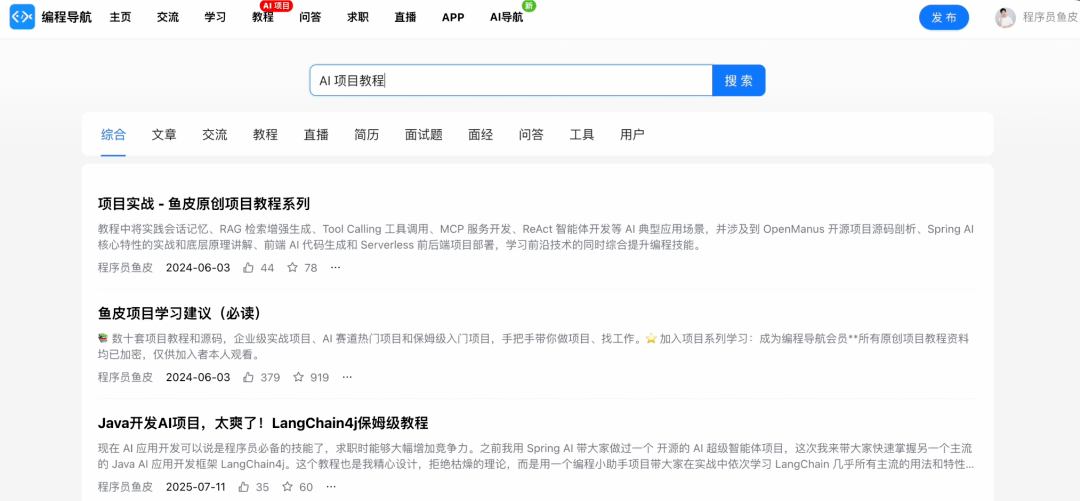
你非常开心:阿巴,俺可真厉害!

鱼皮:不错不错,你已经掌握了 ES 的基本操作,算是学会 80% 了。不过 ES 还有很多值得学习的实用特性,进一步优化你的搜索功能。
### 倒排索引
鱼皮:先来考考你,你知道为什么 ES 能搜得又快又准么?
你挠挠头:阿巴阿巴……
鱼皮笑道:关键在于它使用了 **倒排索引** 来存储数据,这是 ES 最核心的特性。
举个例子,假设咱们要存 3 篇博客文档,用 MySQL 数据库的话,存储结构是这样的:
|文档 id|文档内容|
| ---------| ------------------|
|1|感谢关注鱼皮|
|2|鱼皮是一名程序员|
|3|感谢关注编程导航|
这种结构下,如果用户搜 “鱼皮程序员”,MySQL 会傻乎乎地把它当成一整个词去匹配,结果可能啥也搜不到。
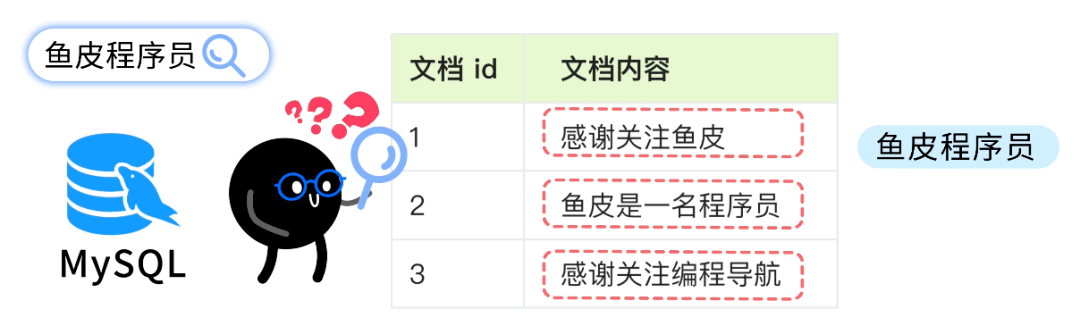
而 ES 的做法不一样。它会先把文档内容按照单词进行切分,这个过程叫 **分词**。然后再构建 **单词到文档 id 的映射关系**,也就是 **倒排索引**。

有了上述的倒排索引,当用户搜索 “鱼皮程序员” 时,搜索引擎数据库会先对搜索词进行分词,得到 “鱼皮” 和 “程序员”,然后根据这两个词汇就能找到文档 id 1、2 了。不用再一行一行遍历表内所有的数据,实现了更灵活、快速的 **模糊搜索** 。
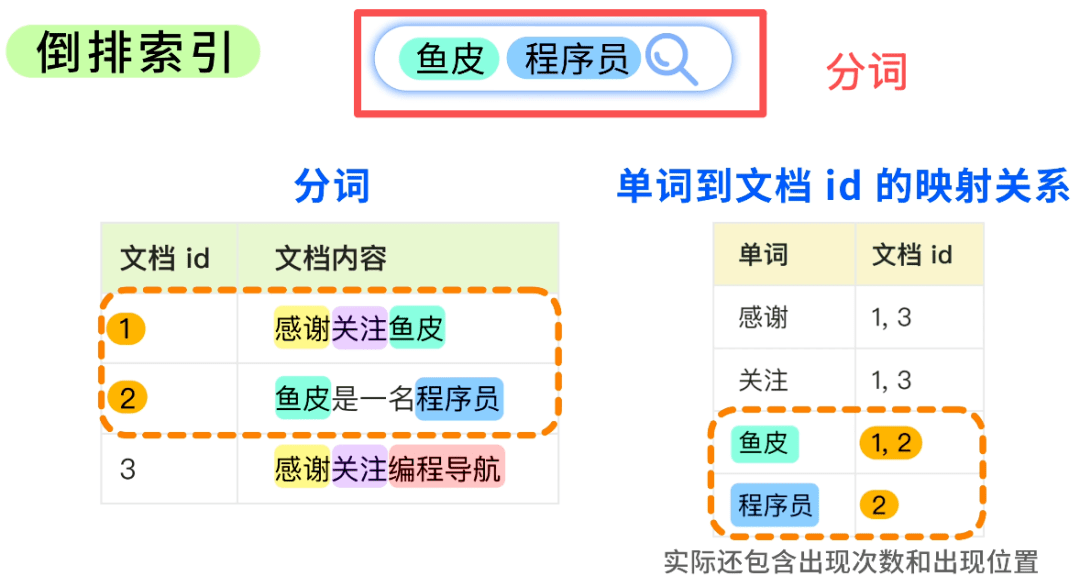
你两眼放光:原来如此,牛啊牛啊!
但是 ES 怎么知道一句话该拆成哪些词呢?
### 分词器
鱼皮:好问题,这就要靠 **分词器** 了,它负责把一段文本拆成一个个词。
ES 内置了标准分词器,它基于 Unicode 文本分割算法设计,会按空格和标点符号等来切分文本。但这个规则只适合英文,对中文基本是一个字一个字地拆,效果很差。

所以如果你要做中文搜索,必须安装 **IK 分词器**。它是专门为中文设计的,能够智能识别中文词汇的边界,把句子正确地拆分成有意义的词语。
IK 提供了两种分词模式:
- `ik_smart` 是智能分词,尽量把词分得少一点,比如 "好学生" 就只会拆成 "好学生" 一个词
- `ik_max_word` 是最大化分词,能拆的都拆,"好学生" 会被拆成 "好学生"、"好学"、"学生" 三个词。
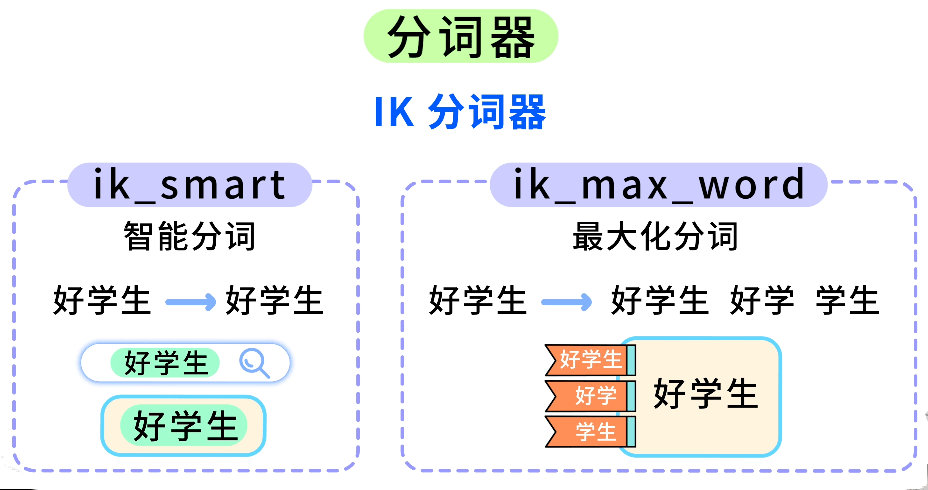
一般建议索引的时候用 `ik_max_word` 尽可能多分词,搜索的时候用 `ik_smart` 提高精确度。
此外,IK 还支持自定义词典。比如你想让 “程序员鱼皮” 作为一个完整的词不被拆开,加到词典里就行了。

### 高亮显示
你好奇道:既然 ES 能分词,那能不能在搜索结果中把命中的关键词标红啊?
鱼皮:当然可以,ES 支持 **高亮显示** 功能。只需要在查询里加个 `highlight` 参数,指定要高亮的字段就行:
```
GET /article/_search
{
"query": {
"match": { "title": "鱼皮教程" }
},
"highlight": {
"fields": { "title": {} }
}
}
```
返回结果里,命中的关键词会自动被 *标签包起来,前端拿到之后加个颜色样式就搞定了。*

*你两眼放光:这也太方便了吧!*
*不过还有个问题,现在虽然能够搜索到内容了,但怎么把最相关的结果排到前面呢?*
### *相关性评分*
*鱼皮:好问题。ES 会给每个搜索结果计算一个分数,放到* *`_score`* *字段中,分数高的排在前面。*

*你好奇道:这个分数是怎么算的呢?*
*鱼皮:ES 默认用的是* ***BM25 算法*** *,主要考虑三个因素:*
- ***词频*** *,关键词在文档里出现的次数越多,分数越高。这很好理解,一篇文章里反复提到 "鱼皮",说明它很可能就是在讲鱼皮相关的内容。*
- ***文档长度*** *,同样出现一次关键词,在短文档里占的比例更大,所以短文档的分数会更高一点。*
- ***稀有度*** *,如果一个词在所有文档里都很常见,比如 "的"、"是",那它对搜索结果的区分度就不大。反过来,如果一个词很少见,只在少数文档里出现,那命中这个词的文档就更有价值,分数也更高。*
### *聚合分析*
*鱼皮:除了搜索,ES 还有个很实用的功能叫* ***聚合分析*** *,有点像 MySQL 的* *`GROUP BY`* *分组查询。*
*比如你想统计每个标签下有多少篇文章,写个聚合查询就行:*
*`GET /article/_search { "size": 0, "aggs": { "tag_count": { "terms": { "field": "tags" } } } }`*

*除了分组统计数量,ES 的聚合还能做求和、求平均值、找最大最小值、甚至多层嵌套聚合,能够满足开发各类数据报表的需求。*

## *第四阶段:生产环境实践*
*用了一段时间 ES 后,你开始有点儿飘了。*
*没事儿就对着新来的实习生阿坤吹牛皮:ES 我闭着眼睛都能写!什么分词、高亮、聚合,我都玩得贼溜儿~*

*结果没多久,老板黑着脸找到你:有用户投诉,说明明改了自己文章的标题,但是搜索出来还是旧的,怎么回事?*

*你排查后发现:原来是 ES 里的数据和 MySQL 数据库里的不一样!当初俺只是把数据一次性导入 ES,后来文章在数据库里更新了,但 ES 里还是旧数据。*
*你有些头大:唉,ES 和 MySQL 是两套独立的系统,数据不会自动同步啊,咋办啊?*

*这时,旁边的阿坤突然鸡叫起来:我来!*
### *数据同步方案*
*阿坤一边打篮球一边说:MySQL 和 ES 的数据同步,一般有这么几种方案。*
*1)定时任务*
*每隔几分钟扫一遍数据库,把最近更新的数据同步到 ES。优点是实现简单,缺点是有一定延迟。适合数据更新不频繁、对实时性要求不高的场景。*
*2)双写*
*每次把数据写入 MySQL 的时候顺便也写一份到 ES。优点是能做到实时同步,缺点是会影响写入性能,而且如果 ES 写失败了还得处理数据不一致的问题。适合数据写入量不大的场景。*
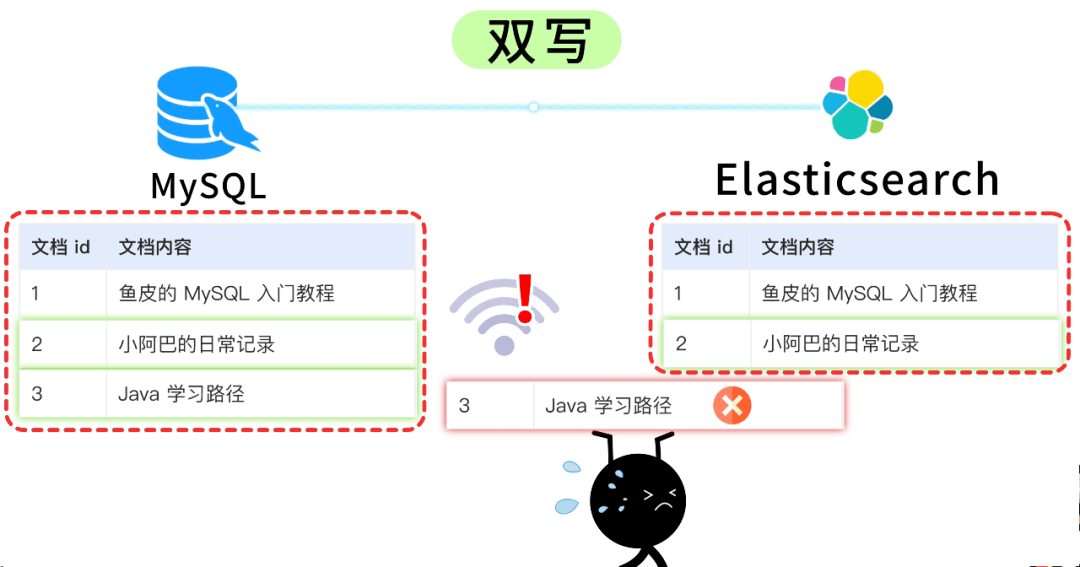
*3)用 Logstash*
*它是 ES 官方提供的数据收集工具,可以配置从 MySQL 定时拉取数据同步到 ES。优点是不用写代码,全靠配置驱动,缺点是需要额外部署组件,灵活性也有限。*
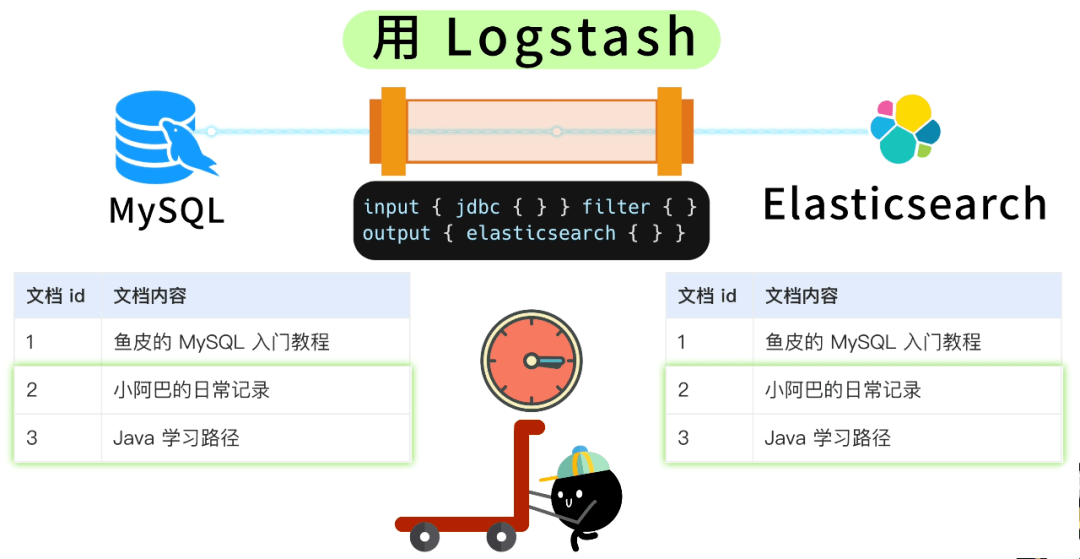
*4)用 Canal 监听数据库*
*Canal 是阿里开源的一个工具,它会伪装成 MySQL 的从库,实时监听数据库的变更日志。数据库一有改动,Canal 立刻就能感知到,然后同步到 ES。优点是能做到实时同步,缺点是部署和运维相对麻烦一点。*

*像咱们这个文章系统,更新又不频繁,用户也能接受几分钟的延迟,用定时任务就完全够了。如果以后做电商那种对实时性要求高的系统,再考虑上 Canal。*
### *集群部署*
*鱼皮走过来拍了拍阿坤的肩膀:不错不错,我再考考你们,如果 ES 服务器挂了怎么办?*
*你支支吾吾:重…… 重启?*

*鱼皮摇头:用户等得起吗?*
*阿坤:生产环境肯定不能只部署一台 ES 啊,得搭建* ***集群*** *。*
*ES 集群中有几种角色的节点。****主节点*** *负责管理集群的状态,比如哪些节点在线、索引的元数据等等。****数据节点*** *负责存储实际的数据,处理读写请求。一般生产环境至少部署 3 个节点,保证高可用。*
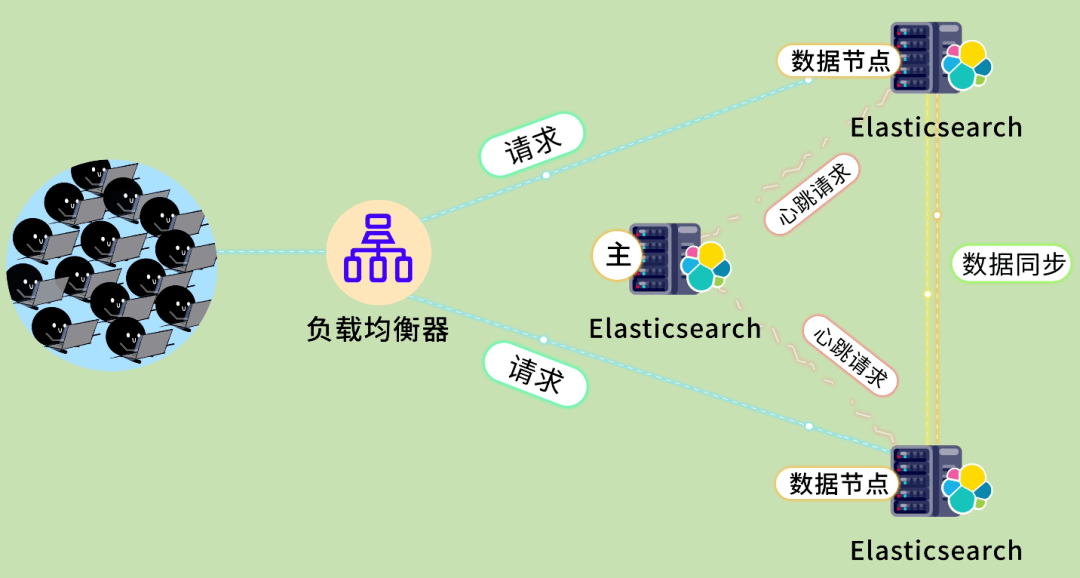
*鱼皮追问:那如果数据量特别大,一个节点存不下怎么办?*
*你眼前一亮,终于等到自己会的问题了,抢答道:删除数据!*
*阿坤用看流浪狗的眼神看了你一眼,回答道:这就要说到* ***分片*** *了。分片就是把一个索引的数据拆成多份,分别存到不同的节点上。这样单个节点存不下的海量数据,也能通过多节点分担。而且多个节点可以并行处理查询请求,性能也更好。*

*你有些不服气:那万一某个节点挂了,上面的数据不就丢了?*
*阿坤:所以还需要* ***副本*** *。副本就是分片的备份。每个分片可以配置若干个副本,存在其他节点上。万一某个节点挂了,副本可以顶上,这样数据就不会丢失,服务也不会中断。*
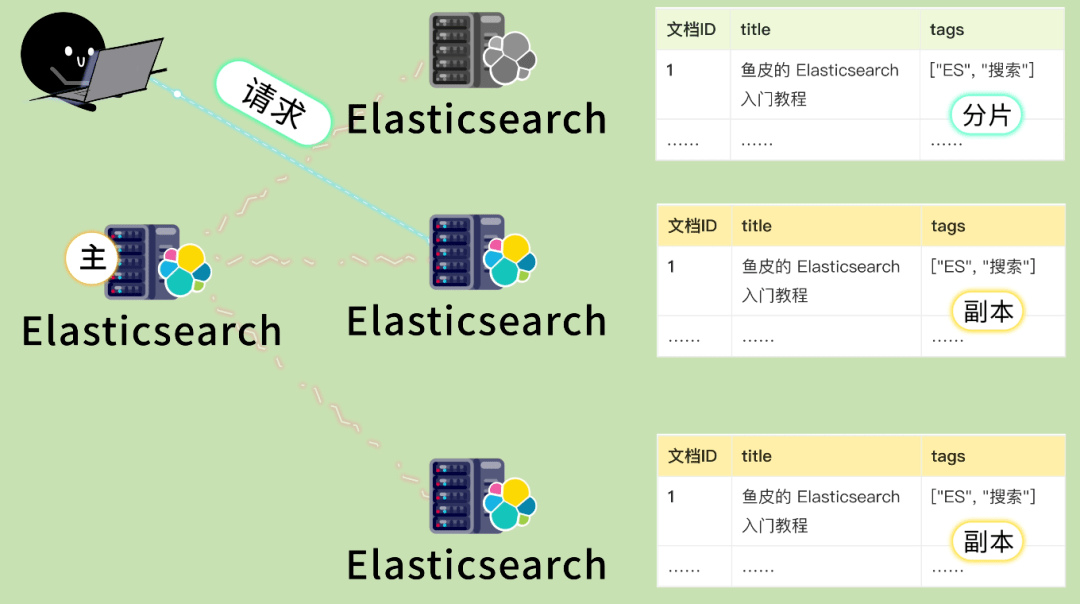
### *其他生产实践*
*鱼皮拍了拍阿坤的肩膀:小伙子年轻有为啊!*
*这些都是 ES 在生产环境必须考虑的问题,此外还要学习:*
- *深度分页问题:ES 默认只允许查询前 10000 条数据,再往后翻就会报错。这是为了保护集群性能。如果确实需要给用户深度翻页,推荐使用更高效的 search_after。如果需要导出全量数据,可以结合 Point-in-Time API 使用。*
- *性能调优技巧:合理设计 Mapping,该用 keyword 的别用 text;查询的时候多用 filter 少用 query,因为 filter 会缓存结果;还有控制返回字段的数量,别动不动就查全部字段。*
- *ELK 日志方案:ES 最经典的应用场景之一就是做日志系统。ELK 是三个组件的缩写,E 是 Elasticsearch 负责存储和搜索日志,L 是 Logstash 负责收集和处理日志,K 是 Kibana 负责可视化展示。大厂排查线上问题,基本都靠这一套。*

*你羞愧地抬不起头:我以为自己已经掌握了 ES,原来只是学了个皮毛……*
*鱼皮:小阿巴,你还要好好跟阿坤学习啊。*

## *第五阶段:深入原理*
*被连环拷问后,你主动找到阿坤:坤哥,我想深入学习 ES 的底层原理,你是怎么学的?*
*阿坤有些惊讶:咦?你不背八股文的么?去 面试刷题网站 - 面试鸭 刷刷题就好了呀!*
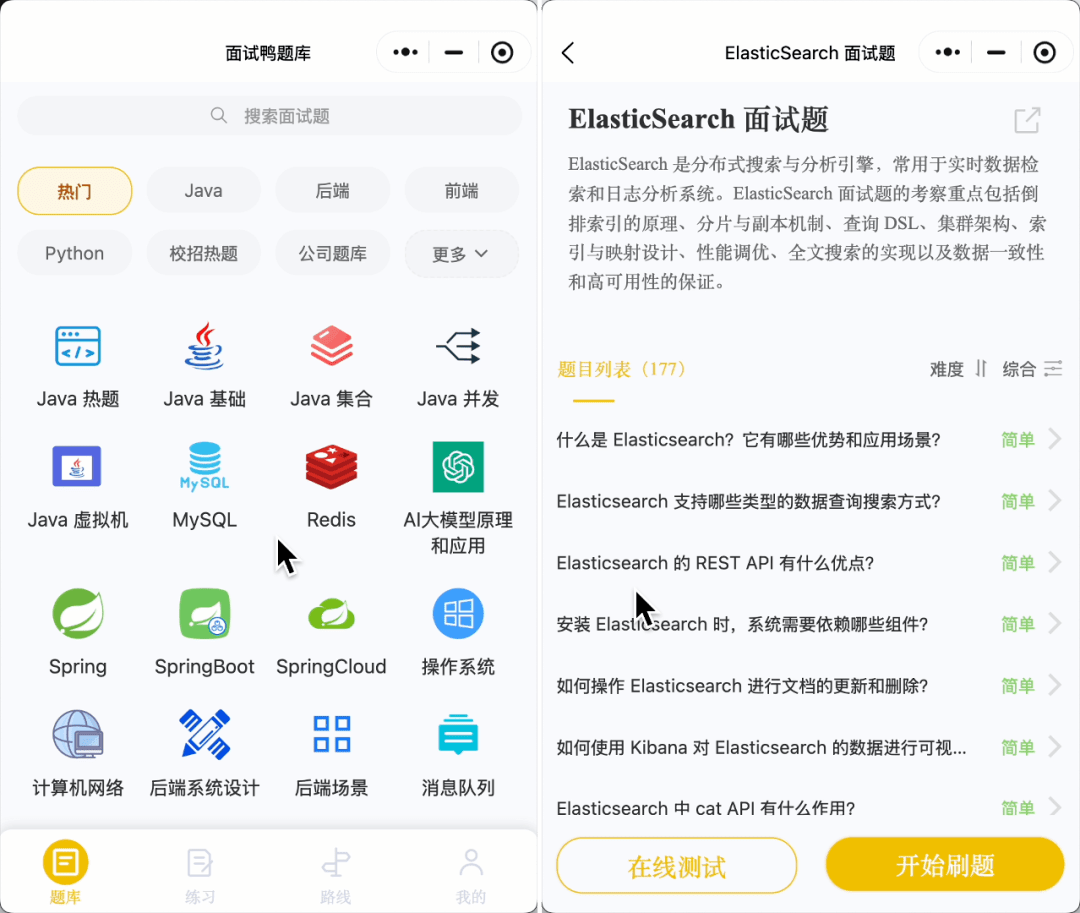
*你震惊了:现在的实习生,竟然恐怖如斯!*
*鱼皮笑了笑:阿坤你别逗他了。其实可以带着问题去学习,比如* ***ES 为什么这么快*** *?*
*你抢答道:因为倒排索引!*
*鱼皮:没错,但这只是一方面。ES 底层是基于 Lucene 搜索引擎库的,它的倒排索引结构经过了高度优化。另外 ES 会把常用的数据缓存在内存里,查询时优先从内存读取,速度自然快。再加上 ES 是分布式的,可以把数据分片存储到多个节点,并行处理查询请求,几方面加起来,性能就上去了。*
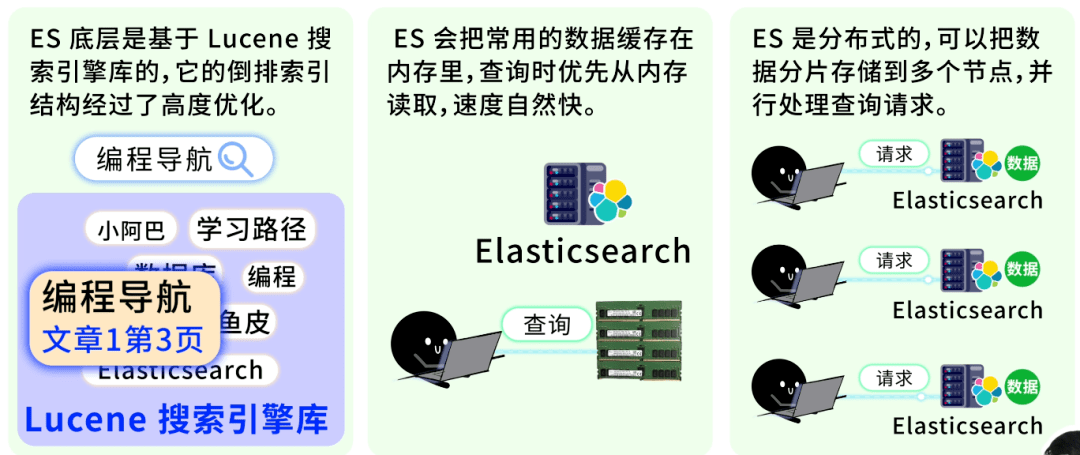
*再比如数据是怎么写入的、查询请求是怎么执行的?*
*从这些问题出发,去阅读相关的文章,或者像阿坤说的刷一刷 ES 高频面试题,就能快速学会很多核心知识点。*
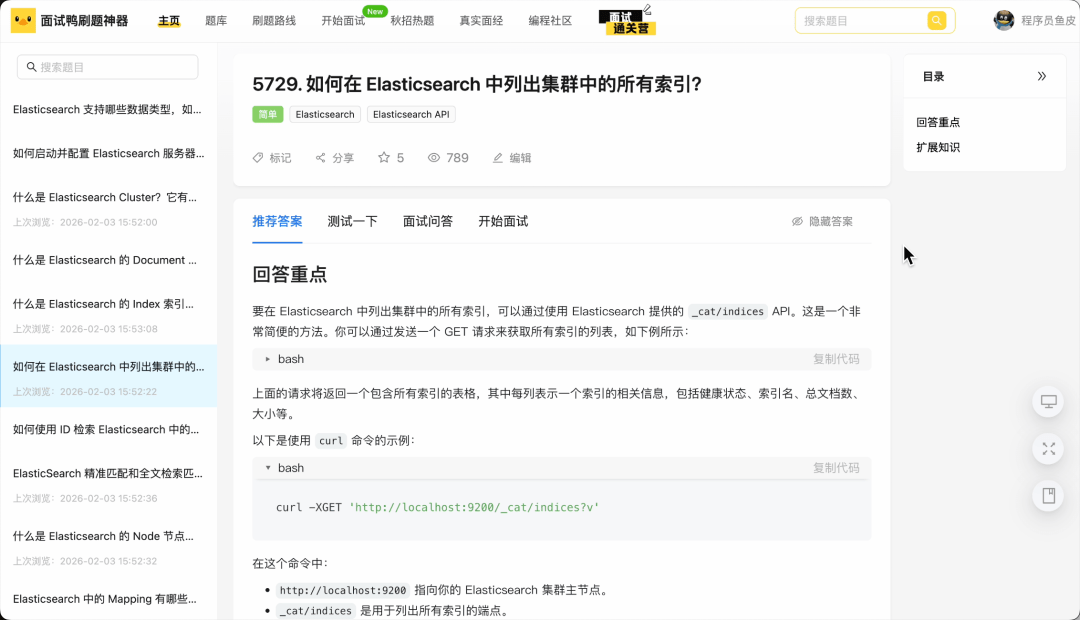
*如果想系统学习,推荐看 ES 官方文档,因为 ES 的更新太快了,很多书籍可能已经跟不上节奏了。*
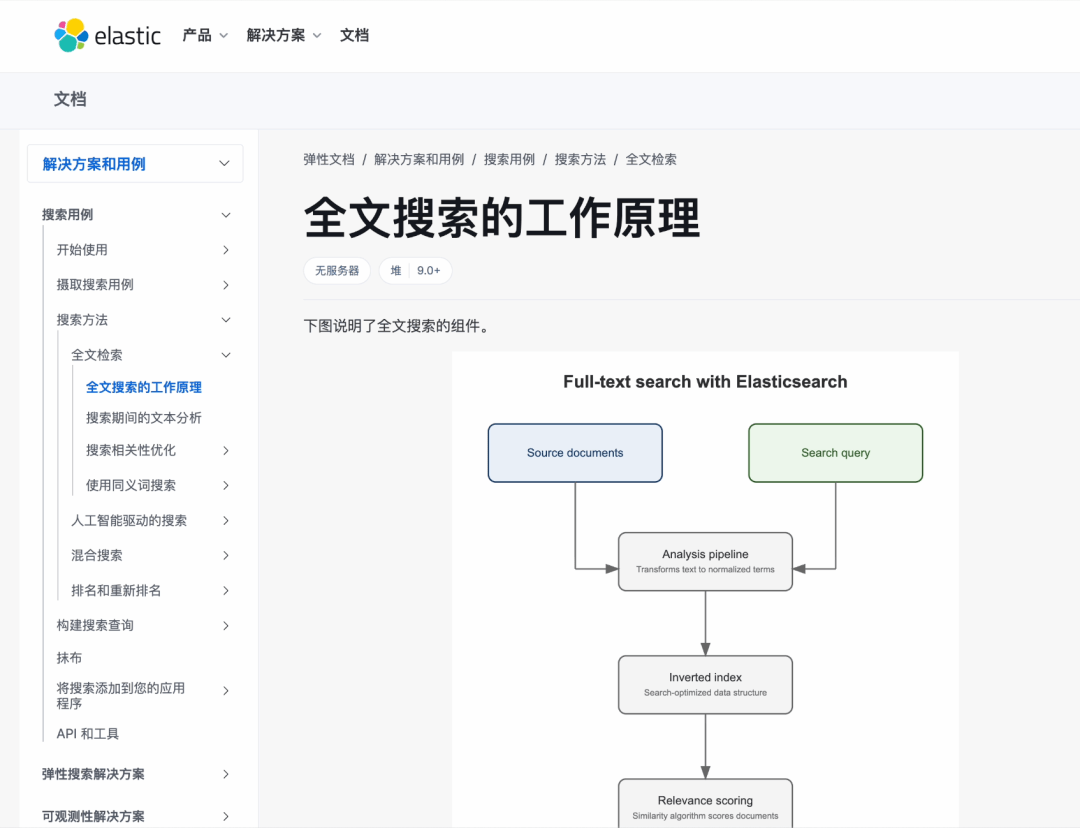
## *结尾*
*若干年后,你已经成为了公司的 ES 搜索专家。不仅能熟练使用 ES 解决各种搜索问题,搭个集群架构也是手拿把掐的。*
*你也像鱼皮当时一样,耐心地给新人分享学习 ES 的经验,让他们谨记一句话:****ES 是实战型技术,一定要多动手实践!***

*再次遇到鱼皮是在一条昏暗的小巷,此时的他年过 35,灰头土脸。你什么都没说,只是给他点了个赞,投了 2 个币。*

*不打扰,是你的温柔~*
*一些对大家有用的资源:👉🏻 100+ 编程学习路线 / 实战项目 / 求职指导* *[codefather.cn](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247577595&idx=2&sn=34c0eec03ed726c03d19f639e9985fda&scene=21#wechat_redirect)* *👉🏻 100+ 简历模板* *[laoyujianli.com](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247576607&idx=2&sn=a2fe52e4e4b7008aa7a081b00cfc2469&scene=21#wechat_redirect)* *👉🏻 300+ 企业面试题库 mianshiya.com👉🏻 500+ AI 资源大全* *[ai.codefather.cn](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247577417&idx=2&sn=b506d27675379b3f432c9f9ad907fe9d&scene=21#wechat_redirect)* *👉🏻 1 对 1 模拟面试* *[ai.mianshiya.com](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247577974&idx=2&sn=cb0f3097c4493f7ab980530cb97f2f04&scene=21#wechat_redirect)* *👉🏻 动画学算法教程* *[algo.codefather.cn](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247576485&idx=2&sn=508ff5e6018405847834b881614bab72&scene=21#wechat_redirect)*
---

Original 程序员鱼皮 程序员鱼皮
_
Read more
_
_
继续滑动看下一个
_
_

程序员鱼皮
向上滑动看下一个
_[^52]: # ChartGPU 重磅发布!WebGPU 版的 ECharts !
## 来源
[原文链接](https://mp.weixin.qq.com/s?__biz=MzUzNTk3MjE2Ng==&mid=2247522428&idx=1&sn=b4e09babbe38aaef16186db692d14c22&chksm=fbdb8f9c8e0072b1770015fe222b512e99d216cff75b30812d793bba22be22317bca8170cfbc&mpshare=1&scene=1&srcid=0303qitHvNHrOp2cIpDbITMq&sharer_shareinfo=0da08b0392971c5c88519754a57a2532&sharer_shareinfo_first=0da08b0392971c5c88519754a57a2532#rd)
## 正文
公众号名称:前端开发爱好者
作者名称:认真努力的小四子
发布时间:2026-03-03 08:34
在前端**可视化领域**,说一句不夸张的话:
> **90%** 的图表项目,都在用 **ECharts**。
>

无论是`后台管理系统`、`数据分析平台`,还是`金融行情系统`,**ECharts** 几乎是默认选项。
`生态成熟`、`组件丰富`、`文档完善`、`上手简单`——它确实解决了绝大多数业务场景。
但问题也很现实。
当`数据规模`上来之后,**ECharts** 开始变得吃力。
## ECharts 的性能瓶颈在哪?
**ECharts** 本质基于 `Canvas 2D`(或 `SVG`)渲染。
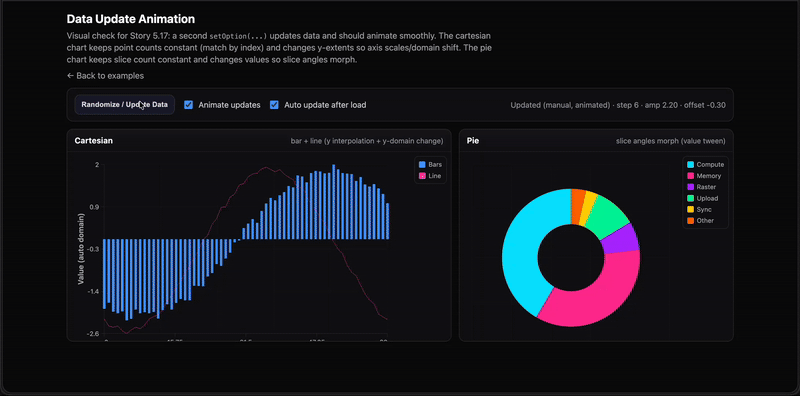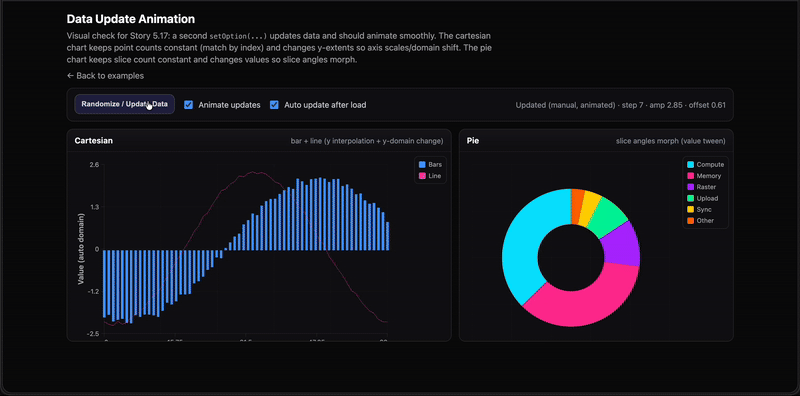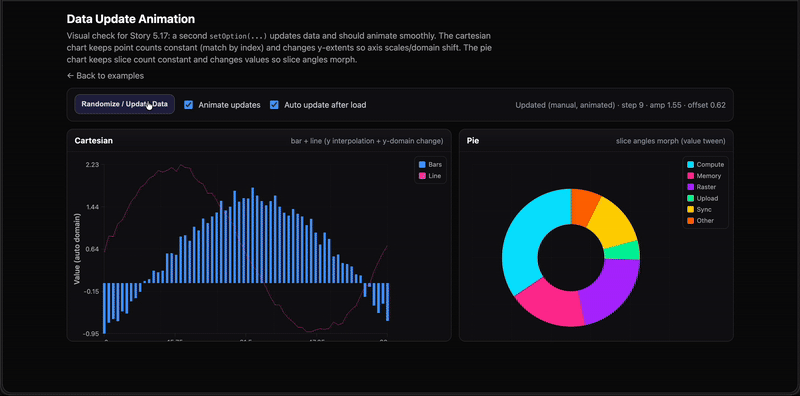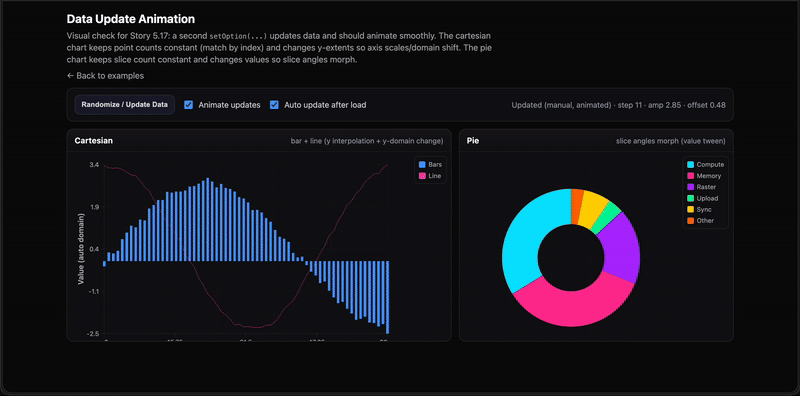
这意味着:
- 渲染逻辑跑在 `CPU` 上
- 大量绘制指令由 `JS` 生成
- 每次重绘都要`执行完整绘制流程`
在数据规模较小时没有问题,但当场景变成:
- **百万级散点**
- **千万级时间序列**
- **高频实时追加数据**
- 多图表同屏 **Dashboard**
常见问题就出现了:
- **帧率明显下降**
- **鼠标交互卡顿**
- **滚动缩放延迟**
- **页面 CPU 飙升**
很多团队的解决方式是:
- **数据抽样**
- **分页展示**
- **后端聚合**
- **限制最大数据量**
但这些都不是根本解决方案。
因为核心问题只有一个:
> **CPU 不是为大规模并行绘制而设计的**。
>
这时候,**ChartGPU** 出现了。
## ChartGPU 是什么?

**ChartGPU** 是一个基于 **WebGPU** 构建的前端图表库。
简单理解一句话:
> 它把图表渲染从 `CPU` 转移到了 `GPU`。
>
**WebGPU** 是浏览器新一代图形 `API`,允许网页直接调用显卡能力。
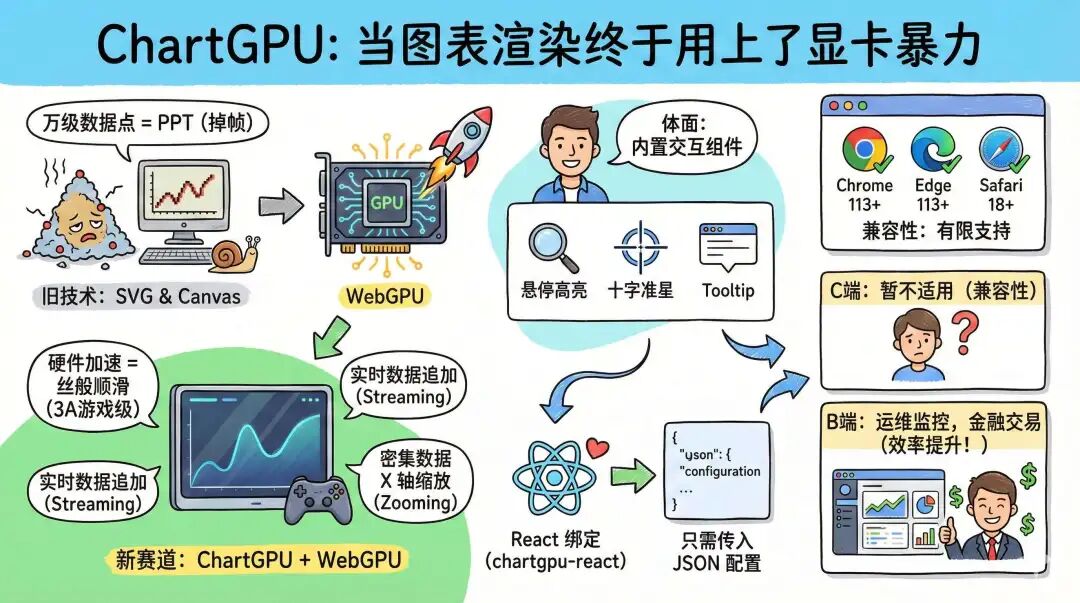
相比传统 `Canvas 2D`,它可以:
- **并行处理大量数据**
- **高效执行批量绘制**
- **管理现代 GPU 渲染管线**
**ChartGPU** 正是构建在这个基础之上。
官方给出的性能数据非常激进:
- `3500 万`数据点仍可保持`高帧率`
- `500 万`根 `K 线`实时更新超过 `100 FPS`
它的目标很明确:
> 解决 **“极端数据规模”** 下的可视化性能问题。
>
## ChartGPU 相比传统图表库有哪些优势?

#### GPU 渲染架构
**传统图表库**:`CPU 计算` + `Canvas 绘制`**ChartGPU**:`GPU 并行计算` + `GPU 绘制`
当数据量达到百万级以上时,**GPU** 的并行能力优势开始显现。
#### 高吞吐数据处理
数据通过 **TypedArray** 传入 `GPU`,避免频繁 `GC`。
在高频更新场景下更稳定。
#### 支持多图表共享 GPU 资源
在 **Dashboard** 场景下:
- 多图实例可`共享 GPU 设备`
- 共享`渲染管线`缓存
避免重复初始化导致的资源浪费。
#### 真正适合“海量数据”
如果数据量只有几千条,**ChartGPU** 未必有明显优势。
但当规模进入:
- **百万级散点**
- **千万级时间序列**
- **高频金融行情图**
差距就会被拉开。
## 如何快速使用 ChartGPU?
**安装**:
```
npm install chartgpu
```
**React 项目**:
```
npm install chartgpu-react
```
**基础使用示例**:
```
import { ChartGPU } from'chartgpu';
const content_container = document.getElementById('content');
const chart = await ChartGPU.create(content_container, {
series: [
{
type: 'line',
data: [
[0, 10],
[10, 30],
[20, 20],
],
},
],
});
```
注意:
- **容器必须设置明确宽高**
- 页面销毁时需调用 `dispose()` 释放 **GPU** 资源
## 支持的图表类型

目前 ChartGPU 支持:
- `折线图(Line)`
- `面积图(Area)`
- `柱状图(Bar)`
- `散点图(Scatter)`
- `饼图(Pie)`
- `K 线图(Candlestick)`
其中散点图支持密度模式(`Density Mode`),在百万级点云场景下尤其实用。
## 内置交互能力
性能之外,**ChartGPU** 也提供完整交互体验:
- `Tooltip` 悬停提示
- `十字准线`(Crosshair)
- 可缩放`时间轴`
- 图表`注释系统`
- 多图`同步联动`
它不仅仅是“快”,而是一个完整的图表解决方案。
## 流式数据更新(实时场景)
对于金融行情、监控系统等场景,**ChartGPU** 提供了数据追加能力:
```
chart.appendData('series-0', new Float64Array([timestamp, value]));
```
特点:
- **不重建整张图**
- 直接向 **GPU** 缓冲区追加数据
- 减少 **GC** 压力
- 保持**高帧率更新**
在实时大盘系统中,这一点至关重要。
## 经典案例展示
**ChartGPU** 官方提供了大量示例场景,下面挑几个典型案例。
#### 百万级散点图
展示数百万数据点仍可保持流畅交互。
👉 **示例页面**:[https://chartgpu.github.io/ChartGPU/examples/](https://chartgpu.github.io/ChartGPU/examples/)

## 高频实时 K 线图
模拟**金融行情**系统:
- **实时价格追加**
- **大规模历史数据**
- **流畅缩放与交互**
## 多图 Dashboard 同屏展示
多个图表共享 **GPU** 设备:
- **同步联动**
- **低资源占用**
- **流畅交互**
## 散点密度模式
当数据点严重重叠时,自动转换为热力密度表达。
## 写在最后
**ChartGPU** 并不是用来取代所有图表库。
如果你只是做普通后台统计图,**ECharts** 依然是成熟稳妥的选择。
但如果你的项目:
- **面对百万级数据规模**
- **需要高频实时更新**
- **正在被性能瓶颈困扰**
- **或正在开发金融 / 科学 / 数据分析系统**
**ChartGPU** 是一个值得重点调研的方向。
- 🔗 **GitHub 地址**:[https://github.com/ChartGPU/ChartGPU](https://github.com/ChartGPU/ChartGPU)
- 🔗 **官网 地址**:[https://chartgpu.github.io/ChartGPU/examples/](https://chartgpu.github.io/ChartGPU/examples/)
---

原创 认真努力的小四子 前端开发爱好者
继续滑动看下一个

前端开发爱好者
向上滑动看下一个[^53]: # OpenClaw从新手到中级完整教程
## 来源
[原文链接](https://mp.weixin.qq.com/s/9PPmlkZmNv5_aB_sSAd_fQ)
## 正文
公众号名称:程序员小灰
作者名称:小灰&子悠
发布时间:2026-03-03 12:10
## **大家好,我是程序员小灰。**
## **在最近这三个月,有一款开源AI Agent项目在全球爆火,许多人都在争相学习和使用。**
## **这个开源项目就是OpenClaw,被国人戏称为“小龙虾”。**
## **这到底是一个怎样的项目?如何进行安装和使用?有哪些落地的应用场景?今天我们用一篇完整教程给大家讲清楚。**
## **文章比较长,建议大家收藏一下,不迷路。**
## **一、OpenClaw 到底是什么?**
OpenClaw(曾用名 ClawdBot/Moltbot)是 2026 年最火的开源 AI Agent 项目,GitHub 已获得超过 242,000 星标。
它不是普通的聊天机器人,而像是一个**的AI智能体平台(Agent Platform)** _,_让你能在自己的电脑上运行AI助理,并把它接入到你日常使用的工具里——比如飞书、Discord。
### OpenClaw的核心架构,就像这张图中所展示的一样:

**1、Gateway(网关)**
Gateway 是 OpenClaw 与外部世界交互的桥梁:
- **消息路由**:将 IM(微信、Telegram、Discord 等)消息转发给对应的 Agent 处理
- **结果回复**:将 Agent 的响应发送回原始 IM 渠道
- **多渠道支持**:同时接入多个 IM 平台,统一管理
**2、Agent(智能体)**
Agent 是处理任务的实体:
- **会话管理**:维护对话上下文,支持多轮对话
- **任务执行**:调用 Skills 和工具完成用户请求
- **记忆机制**:通过记忆系统保持长期上下文
**3、Skills(技能)**
Skills 是 OpenClaw 的能力扩展,类似于"插件"或"应用":
- **模块化设计**:每个 Skill 定义一组特定任务
- **生态丰富**:可从 ClawHub 安装第三方 Skills
- **自定义开发**:支持编写自定义 Skills 扩展能力
- **典型 Skills**:GitHub、Weather、Coding Agent 等
**4、Channel(频道)**
Channel 定义了消息的输入/输出渠道:
- **多平台接入**:支持 Telegram、Discord、WhatsApp、Feishu、Signal 等
- **配置灵活**:每个 Channel 可独立配置机器人行为
- **消息格式**:处理不同平台的消息格式差异
## **二、如何安装OpenClaw?**
在终端,粘贴下面命令安装 openclaw:
```
npm install -g openclaw@latest
```
安装完成后,执行以下命令,然后按照引导对openclaw进行初始化设置:
```
openclaw onboard --install-daemon
```
选择 **QuickStart** 快速开始配置:
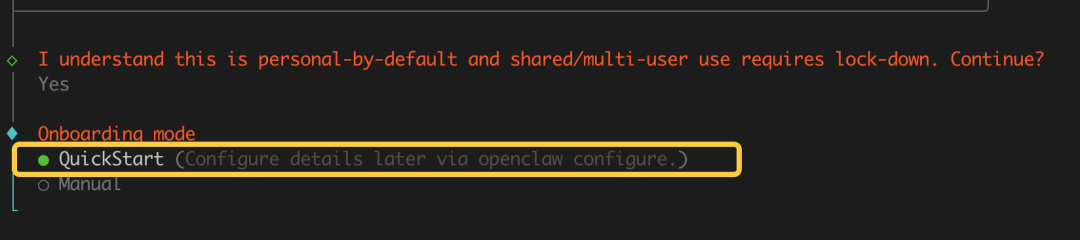
AI模型供应商选择, 这里我选择 **MiniMax:**
认证方式选择:**MiniMax M2.5(CN)** ,意思是国内版本,通过API Key 方式做认证:
接着按提示输入Key,回车确认。

Channel 选择,暂时跳过,后面单独介绍接入飞书和Discord:
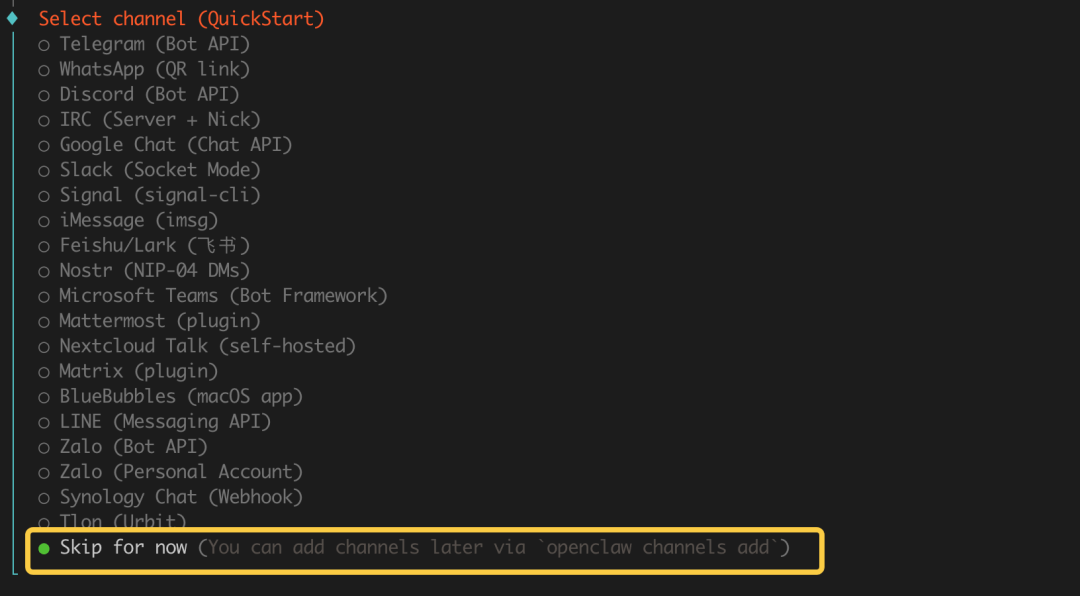
Skill 和Hooks 也先跳过,暂时先不配置:
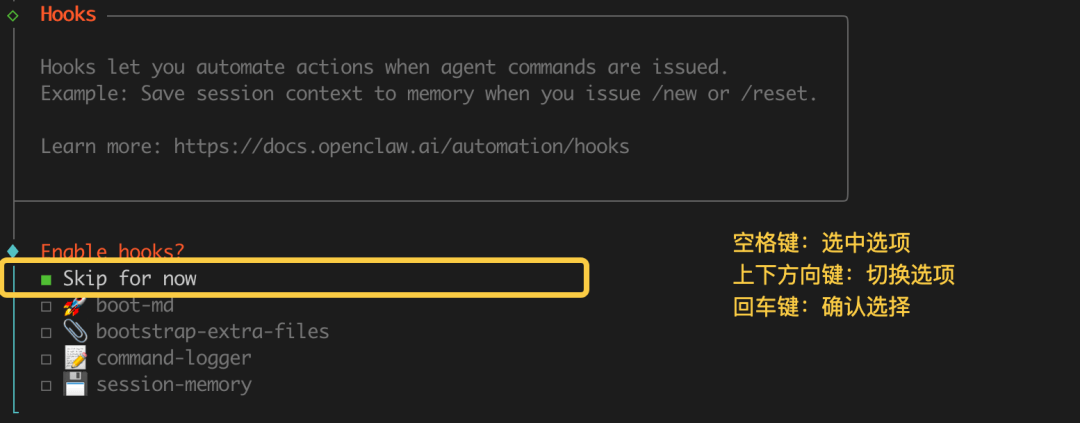
然后选择的Web UI打开 OpenClaw Web 端:

随后会在浏览器打开 http://127.0.0.1:18789
这个就是 OpenClaw Web 端,后面也可以通过 **openclaw dashboard** 命令来打开 **。**
### **三、如何接入****飞书机器人?**
## 为了可以随时随地使用OpenClaw **,我们需要接入IM通信软件。**
## **国内的话可以考虑接入飞书,因为它生态相对开放,接入起来会比较方便,同时支持PC电脑端和手机移动端。**
**1、创建****飞书应用**
https://open.feishu.cn/app
打开飞书开放平台, 创建新的应用: **OpenClaw**
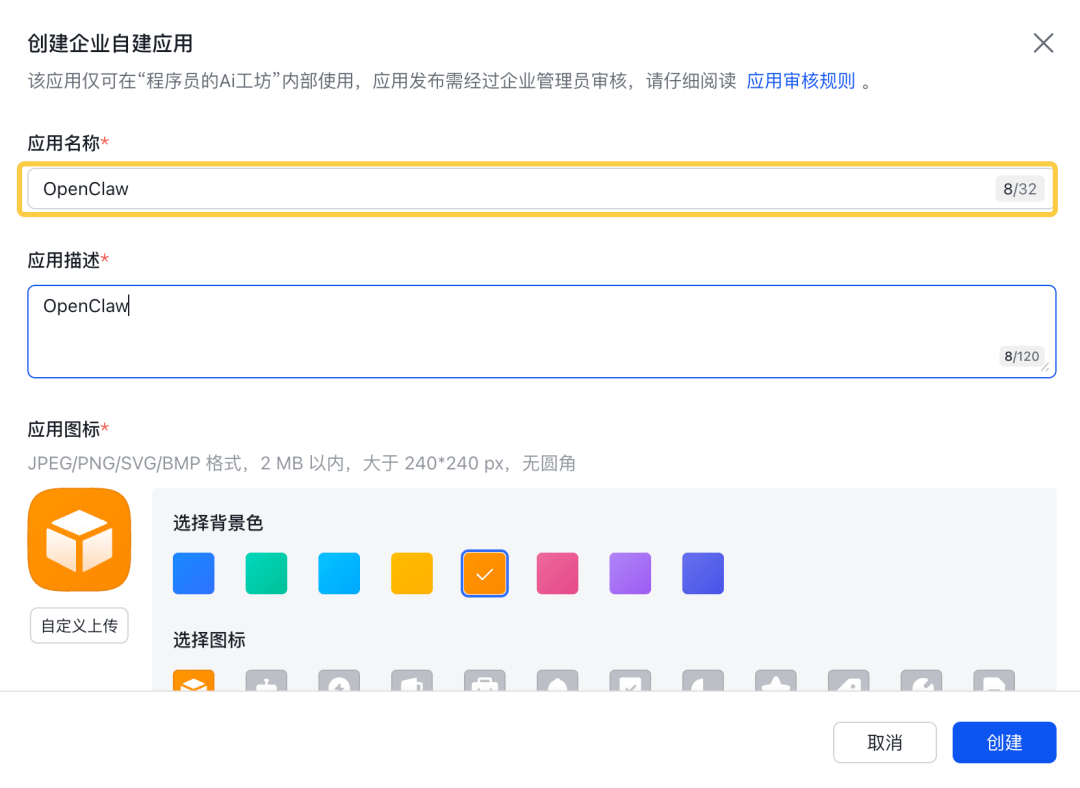
创建完成记录下 App ID 和 App Secret 备用:
**2、 OpenClaw添加********飞书********channel**
使用命令:openclaw plugins enable feishu 开启 OpenClaw 内置的飞书插件,默认是disable 状态,loaded 为开启。
使用 openclaw channels add 命令配置channel。
选择 Feishu/Lark (飞书):
按提示输入创建飞书应用时保存的App ID 和App Secret:
群聊策略选择 Open:允许响应所有的群聊,Allowlist: 在白名单的群聊可以响应。

选择 Finished, 然后按提示完成配置即可。
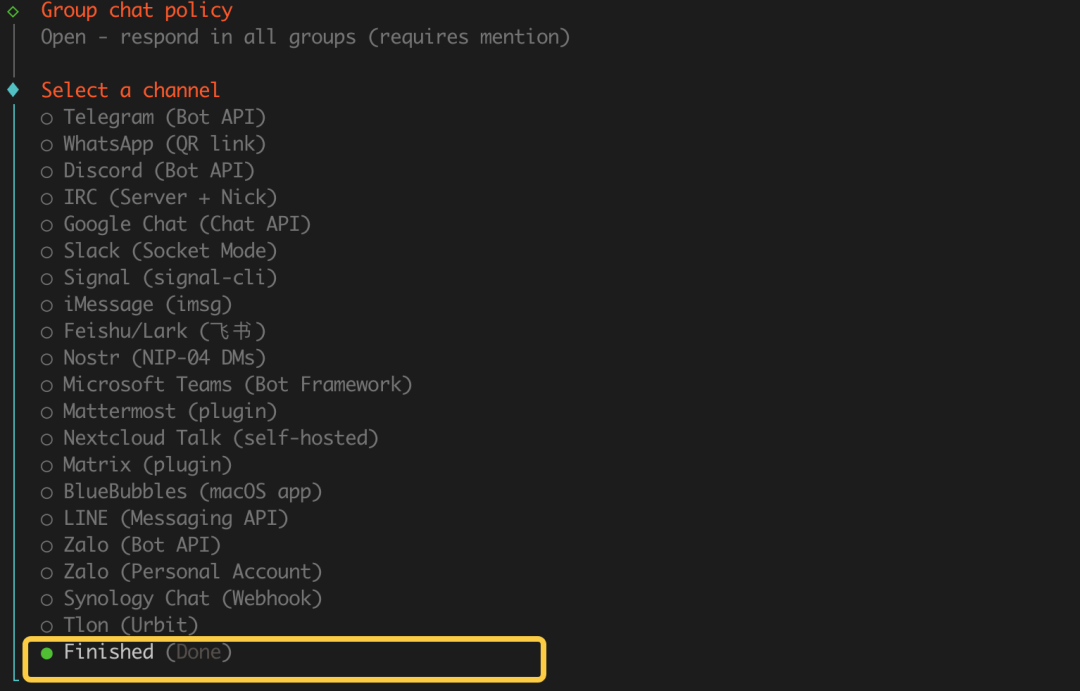
Web 端 Channels 页可以看到飞书是 Running 状态, 就是配置好了。
**3、 配置********飞书应用********机器人能力与消息权限**
编辑上面创建的飞书应用
- 为应用开启机器人能力

- 为应用开通相关权限
- 批量导入下方权限
```
{
"scopes": {
"tenant": [
"cardkit:card:write",
"contact:contact.base:readonly",
"contact:user.base:readonly",
"im:chat:readonly",
"im:message",
"im:message.group_at_msg:readonly",
"im:message.group_msg",
"im:message.p2p_msg:readonly",
"im:message.reactions:read",
"im:message:readonly",
"im:message:recall",
"im:message:send_as_bot",
"im:message:update",
"im:resource"
],
"user": [
"contact:contact.base:readonly"
]
}
}
{
"scopes": {
"tenant": [
"cardkit:card:write",
"contact:contact.base:readonly",
"contact:user.base:readonly",
"im:chat:readonly",
"im:message",
"im:message.group_at_msg:readonly",
"im:message.group_msg",
"im:message.p2p_msg:readonly",
"im:message.reactions:read",
"im:message:readonly",
"im:message:recall",
"im:message:send_as_bot",
"im:message:update",
"im:resource"
],
"user": [
"contact:contact.base:readonly"
]
}
}
```
- 为应用订阅相关事件
订阅方式选默认推荐的 **长连接****,添加上以下事件**

⚠️第3步中的订阅事件的操作一定要在第2步 接入飞书channel之后,否则选长连接会失败。
编辑完之后记得创建版本并发布才能生效。
**4、接入********飞书********群聊**
用手机或者电脑打开飞书客户端,创建一个测试群:
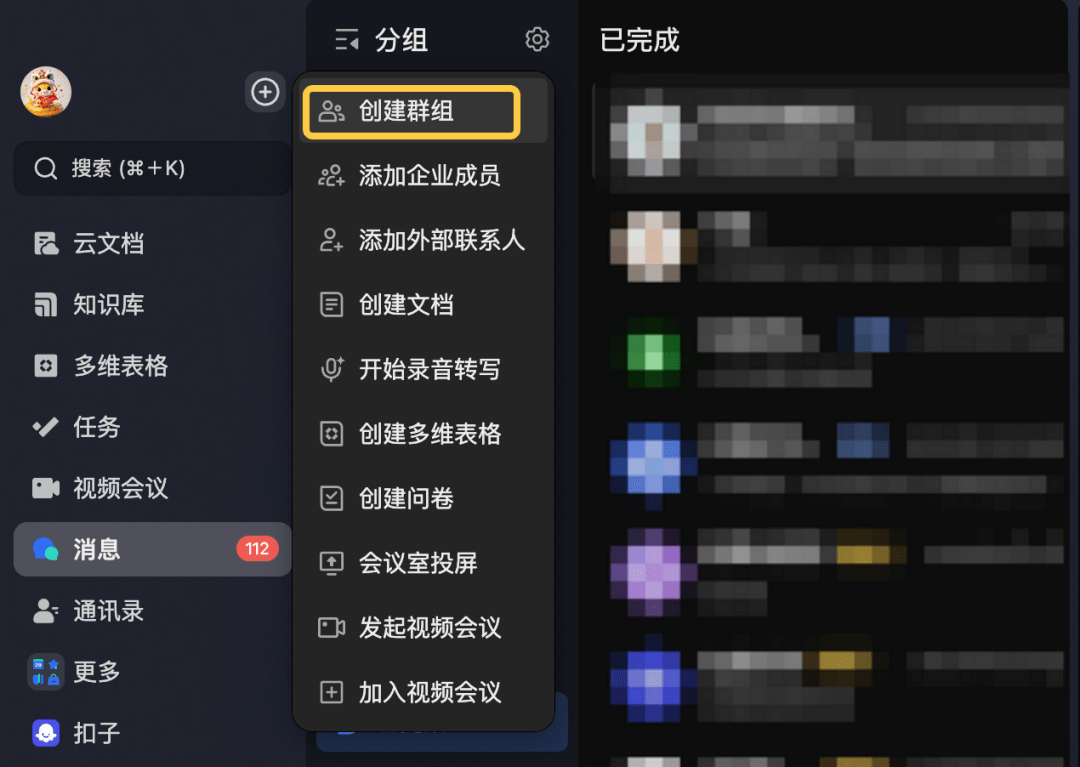
将机器人拉入群聊:
@**OpenClaw 打个招呼:**
**OpenClaw** 可以正常回复就说明飞书接入成功了。
### 四、如何接入Discord Bot?
### 对于有条件上外网的朋友,可以考虑接入Discord,它多频道(channel)的设计天生就适合 OpenClaw 的多Agent场景, 用起来很丝滑。
**1、新建 discord 应用**
https://discord.com/developers/applications
打开Discord 开发者平台,新建应用:**OpenClaw**
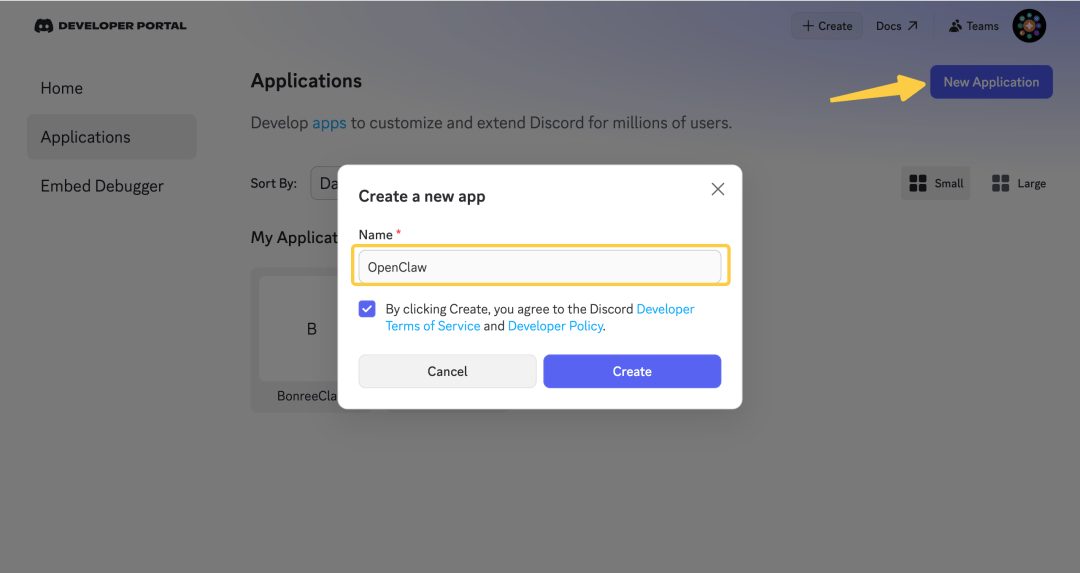
Bot 页面开启下面3个配置项,然后复制Token 备用:
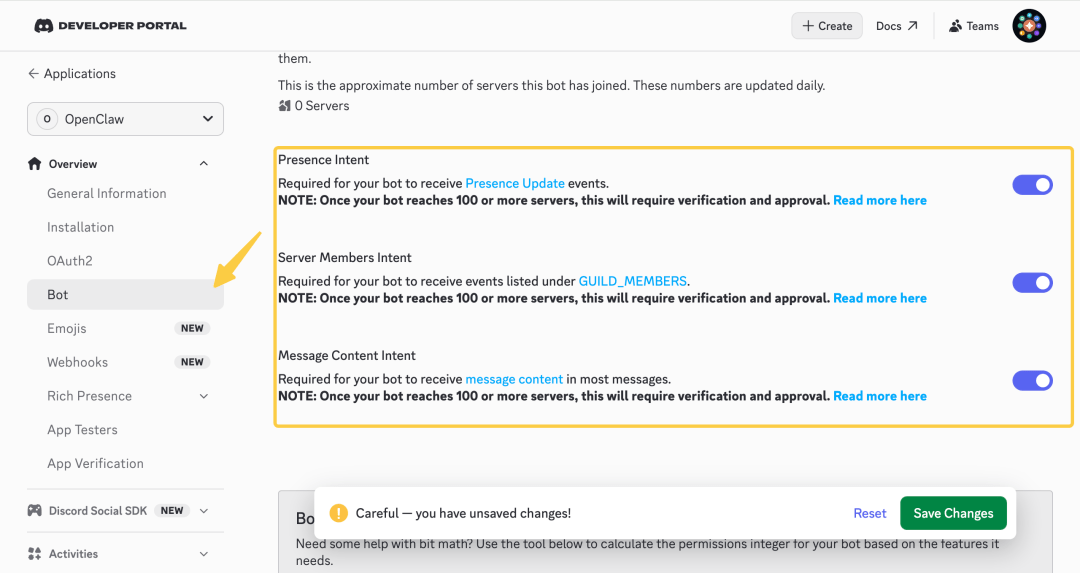
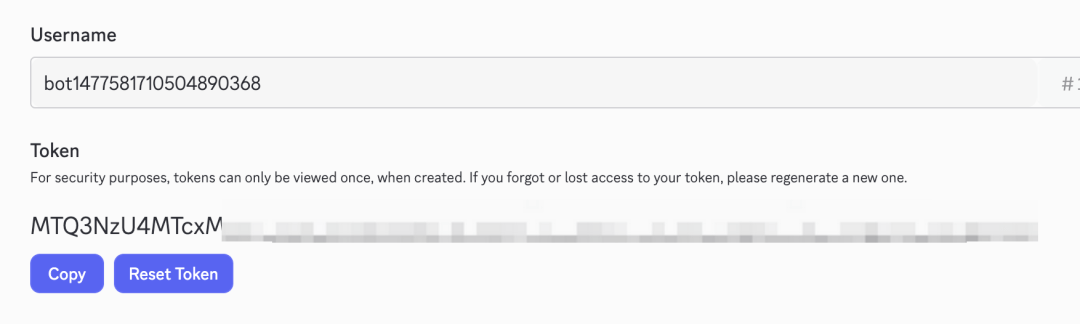
OAuth2 页面开启必要的权限后,拷贝生成的URL:
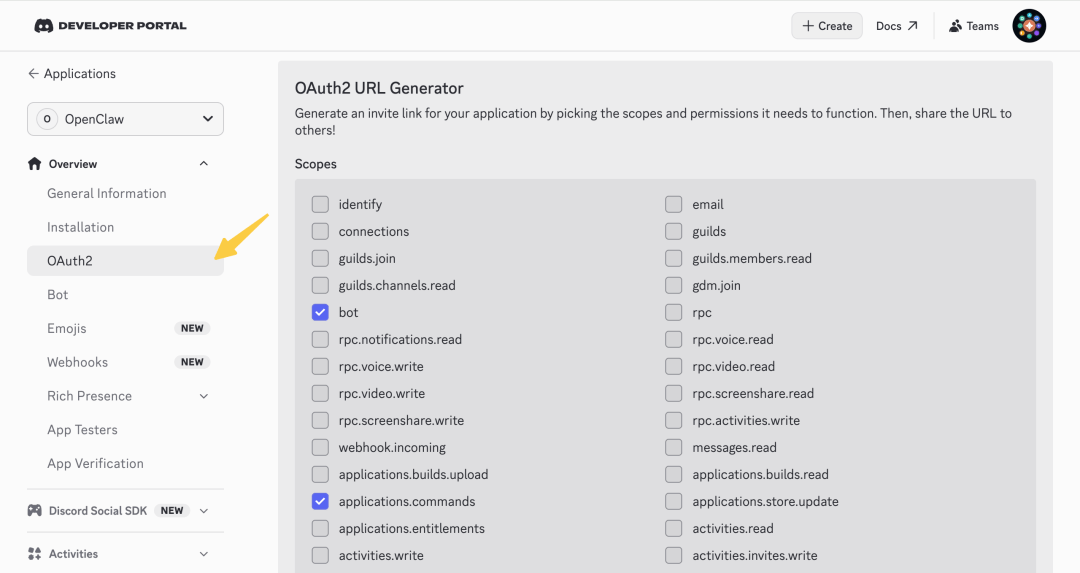
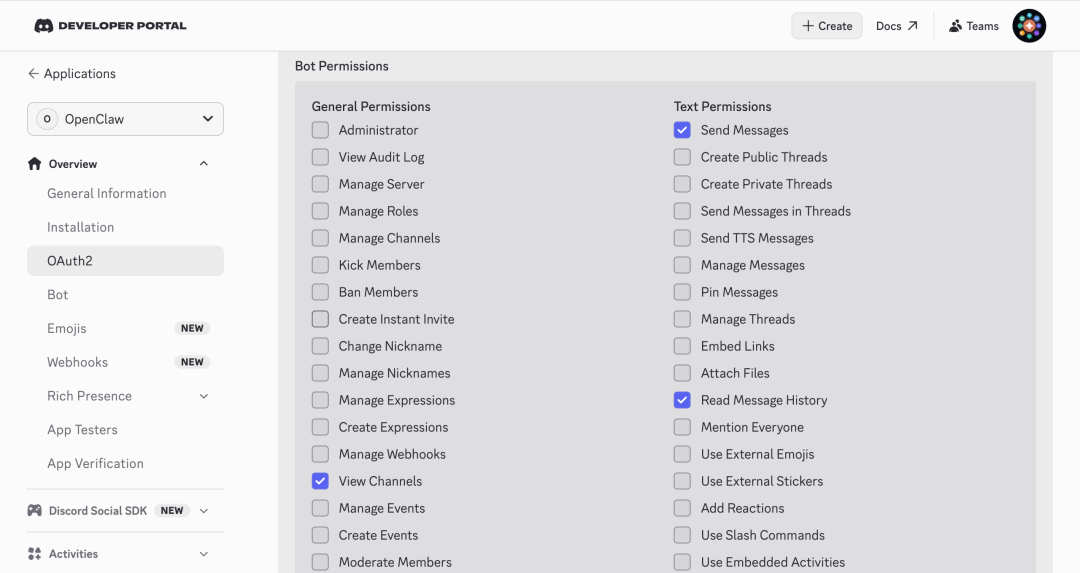
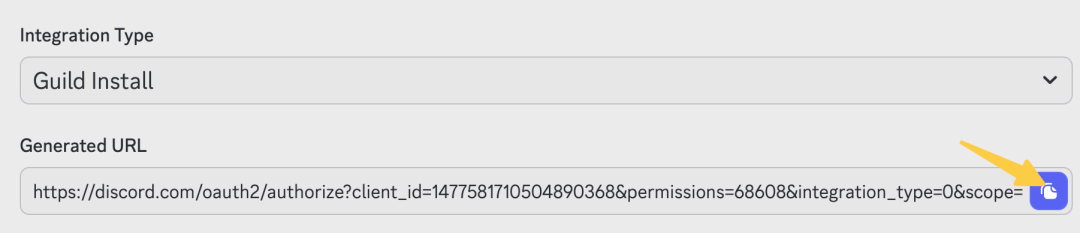
**2、新建Discord Server 并加入****Bot**
新建Discord 的Server:
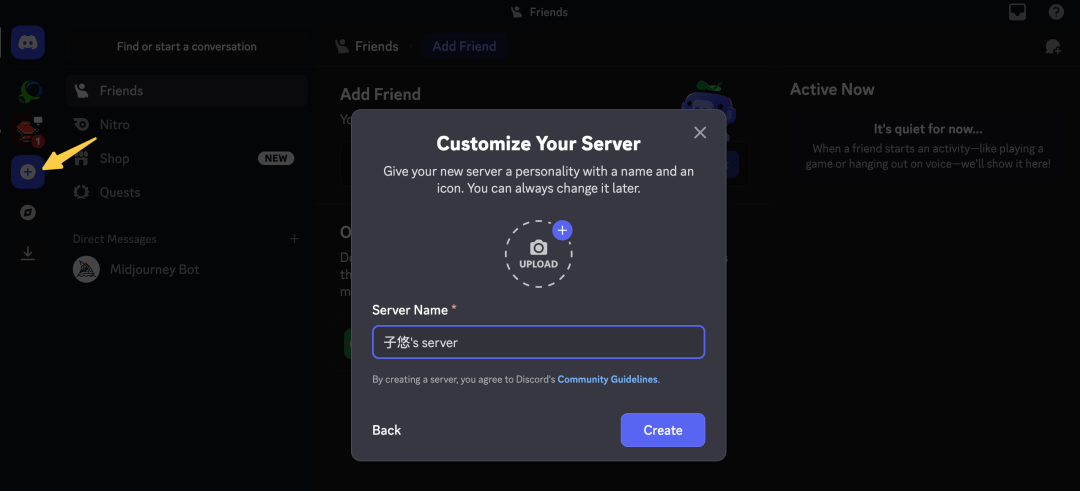
将创建的Bot 加到 Server , 拷贝上面复制的URL 到浏览器打开,点击‘Continue’:
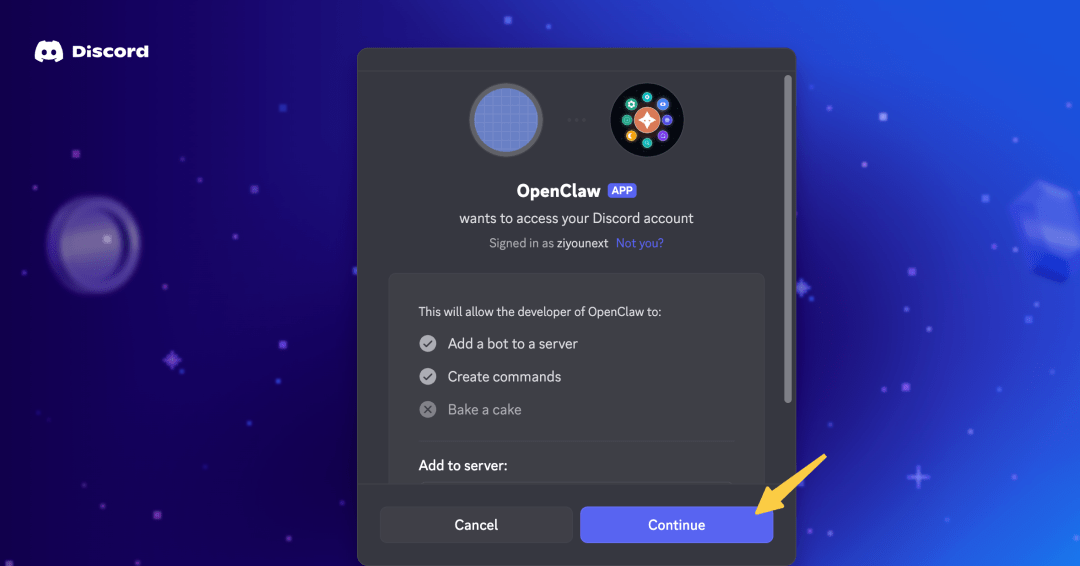
**3、OpenClaw添加Discord** **channel**
使用 openclaw channels add 命令配置channel。
选择 Discord (Bot API):
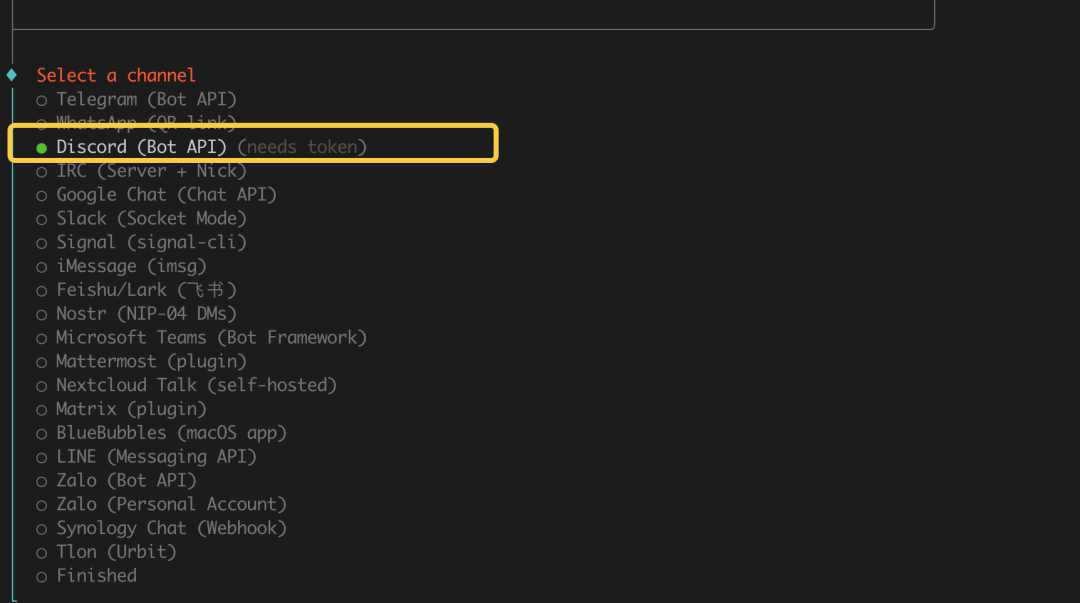
按提示输入Token:
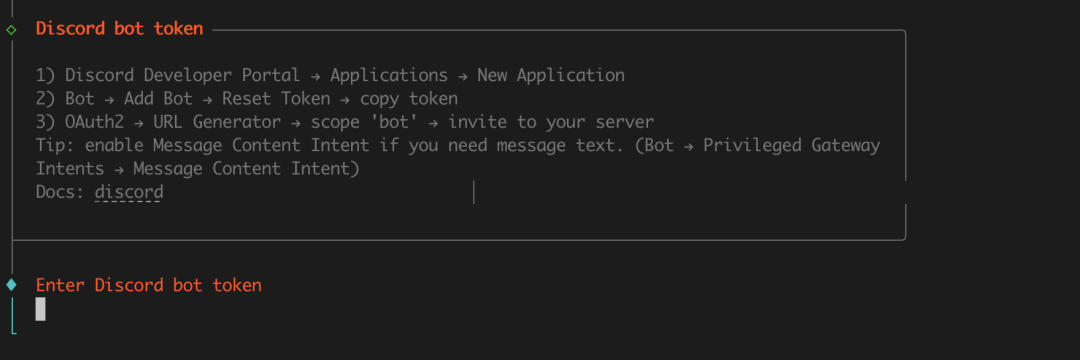
Discord channel策略选择 Open:允许响应所有的channel,Allowlist: 在白名单的channel可以响应:

选择 Finished, 然后按提示完成配置即可。
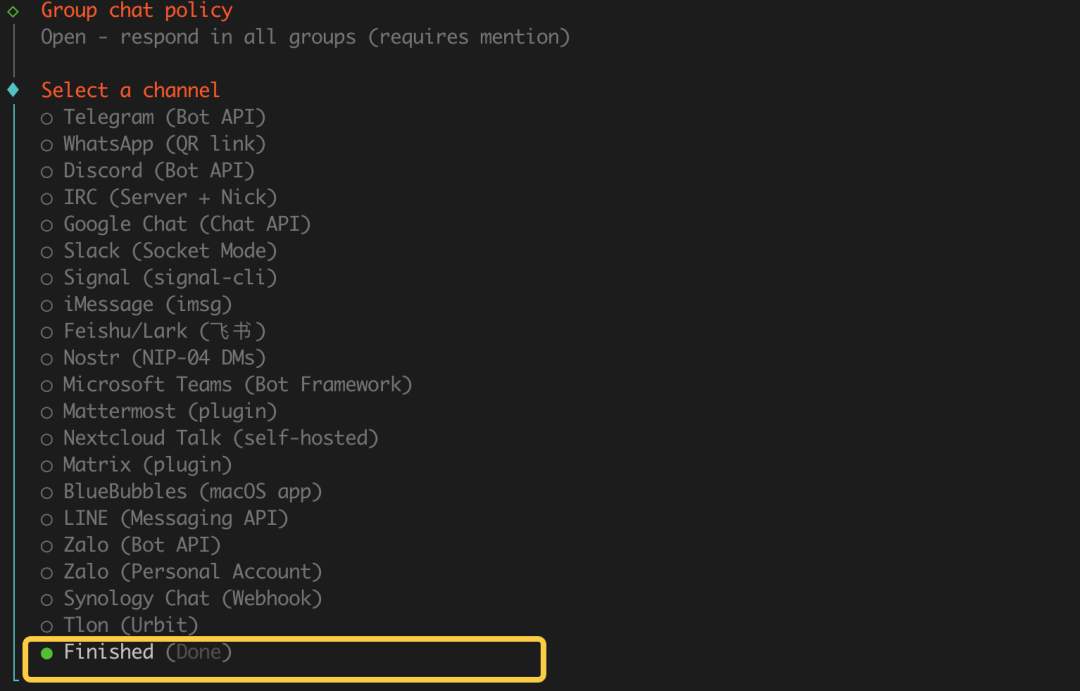
## 五、如何进行多Agent 配置?
在 OpenClaw 中,一个 Agent 不只是一个名字,它是一个**独立的“虚拟员工”** ,拥有自己的各个组成部分,包括:
- **Workspace (工作区)** :它的个人办公室("灵魂三件套"、长期记忆)
- **AgentDir (状态目录)** :它的身份证(认证信息、模型配置)
- **Sessions (会话存储)** :它的私人记忆(独立的聊天记录,不跟别人串味)
### 其中 Workspace 目录下的 AGENTS.md、SOUL.md、USER.md 文件是Agent 的核心,被称为Agent 的"灵魂三件套",下面我给大家逐个介绍下:

**1、SOUL.md — AI 的灵魂**
定义 AI 的性格和行为准则:
- Core Truths — 核心原则(不说废话、有观点、谨慎使用外部工具)
- Vibe — 风格定位(不像机器人,像真实助手)
- Boundaries — 边界(隐私保护、谨慎对外)
**2、USER.md — 用户画像**
记录关于用户的信息:
- 姓名、称呼、时区
- 偏好、项目、痛点
- 随对话不断更新
**3、AGENTS.md — 工作规范**
定义工作方式和记忆机制:
- 每次会话必读:SOUL.md → USER.md → memory/
- 写作规范:TEXT > BRAIN(随时记录)
- 心跳任务:定期检查 + 主动汇报
- 群聊礼仪:知道何时说话、何时沉默
**通过调整 workspace 下的这3个文件,就可以将Agent 从"通用 AI"变成"你的专属AI"。**
### 多Agent的原理已经讲清楚,接下来我们演示一下,如何在Discord当中配置**多个agent:**
**step1: 新建多个agent**
Openclaw 默认是单 agent 模式,可以通过下面命令新建 agent:
```
openclaw agents add coder
```

**step2: 创建多个****Bot**
按着上面 **新建 discord 应用** 的操作创建多个Bot 并加入到Server

**step3: 将****Bot** **与Agent 绑定**
通过bindings 为每个agent 绑定一个Bot , 下面是discord 的配置示例:
```
{
"bindings": [
{
"agentId": "main",
"match": {
"channel": "discord",
"accountId": "main"
}
},
{
"agentId": "coder",
"match": {
"channel": "discord",
"accountId": "coder"
}
}
],
"channels": {
"discord": {
"enabled": true,
"allowBots": true,
"groupPolicy": "allowlist",
"accounts": {
"main": {
"token": "${DISCORD_BOT_TOKEN_1}",
"groupPolicy": "allowlist",
"guilds": {
"${SERVER_ID}": {
"requireMention": true,
"users": [
"${USER_ID}"
],
"channels": {
"${CHANNEL_ID}": {
"allow": true
}
}
}
}
},
"coder": {
"token": "${DISCORD_BOT_TOKEN_2}",
"groupPolicy": "allowlist",
"guilds": {
"${SERVER_ID}": {
"requireMention": true,
"users": [
"${USER_ID}"
],
"channels": {
"${CHANNEL_ID}": {
"allow": true
}
}
}
}
}
}
}
}
}
{
"bindings": [
{
"agentId": "main",
"match": {
"channel": "discord",
"accountId": "main"
}
},
{
"agentId": "coder",
"match": {
"channel": "discord",
"accountId": "coder"
}
}
],
"channels": {
"discord": {
"enabled": true,
"allowBots": true,
"groupPolicy": "allowlist",
"accounts": {
"main": {
"token": "${DISCORD_BOT_TOKEN_1}",
"groupPolicy": "allowlist",
"guilds": {
"${SERVER_ID}": {
"requireMention": true,
"users": [
"${USER_ID}"
],
"channels": {
"${CHANNEL_ID}": {
"allow": true
}
}
}
}
},
"coder": {
"token": "${DISCORD_BOT_TOKEN_2}",
"groupPolicy": "allowlist",
"guilds": {
"${SERVER_ID}": {
"requireMention": true,
"users": [
"${USER_ID}"
],
"channels": {
"${CHANNEL_ID}": {
"allow": true
}
}
}
}
}
}
}
}
}
```
Tips: 手动修改配置文件容易出错,可以直接将这个丢给OpenClaw 让它给配置。
## 六、如何使用OpenClaw Skill 市场?
ClawHub 是 OpenClaw 的官方插件市场,提供丰富的 Skills 扩展。它的访问地址如下:
##
https://clawhub.ai/
另外clawhub 也提供了命令行工具用来搜索/安装SKill,使用下方命令进行安装
npm install -g clawhub
- 搜索 Skills
clawhub search <关键词>
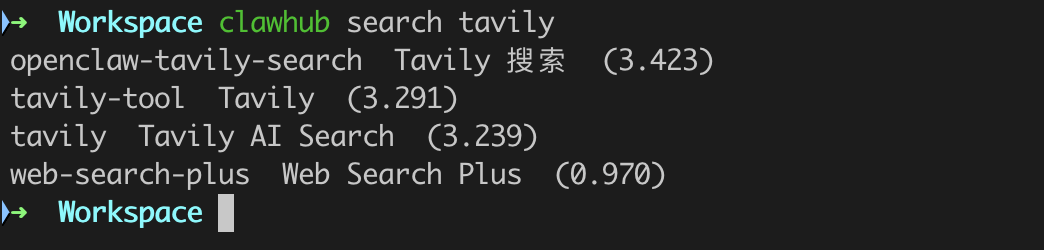
- 安装指定的 Skill
clawhub install <skill-name>

通过 openclaw skills list 命令可以查看当前安装的skills 情况,绿色ready状态的Skill 就是可用的

## **七、OpenClaw的实操案例**
**案例1: 操作浏览器**
在飞书聊天框 **@OpenClaw 打开浏览器,用Google 搜索下‘openclaw’**

OpenClaw 会自动打开你的浏览器进行操作
**案例2: 每日新闻**
**@OpenClaw 每天18:10分给我一个关于Ai 的新闻简报**
**案例3: 自动审查** **GitHub** **的****PR**
**@OpenClaw 帮我审查下这个项目的****PR** **<****github** **rep>**
通过 **Heartbeat 可以让OpenClaw 自动审查****PR**
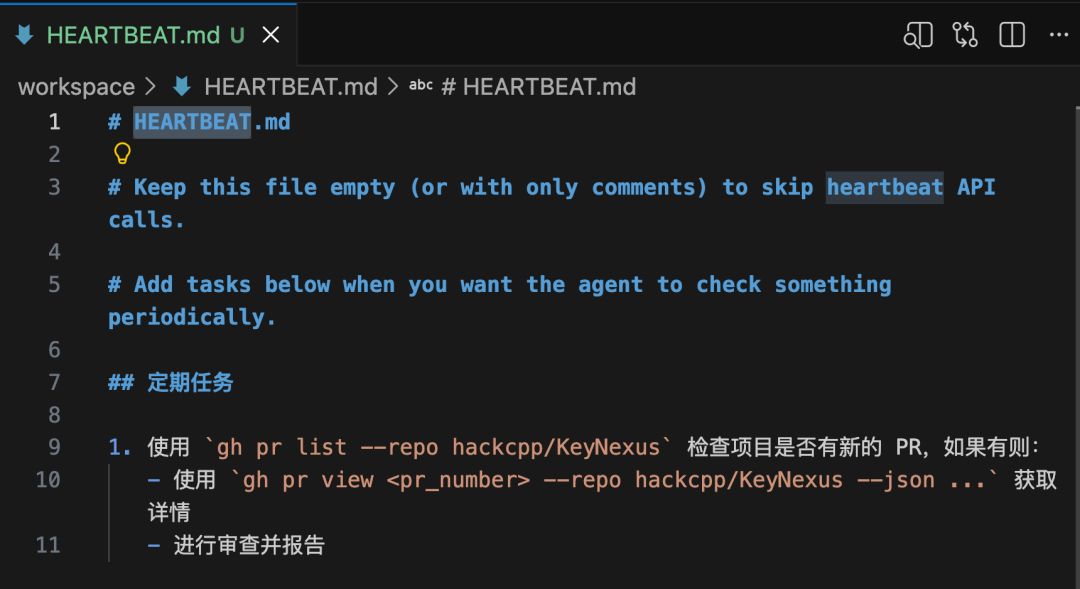
## 八、OpenClaw的常用玩法
## 在OpenClaw上线的这三个月里,许多聪明的玩家研究出了各种落地玩法,为他们带来了工作提效,甚至是变现。
在此,我们挑选了一些社区分享的案例供大家参考尝试。如需探索更多应用场景,访问这个 GitHub 仓库:
https://github.com/hesamsheikh/awesome-openclaw-usecases
**案例1:** 自定义早间简报****
每天在固定时间(如早上 8:00)通过 Telegram、Discord 或 iMessage 发送一份结构化的简报,内容涵盖:
- **定制新闻:** 自动搜索并总结你感兴趣的领域(如 AI、创业、技术)的隔夜动态。
- **任务梳理:** 从 Todoist 或 Apple Reminders 等工具中提取当天的待办事项。
- **深度产出:** 不只是给灵感,而是直接写出完整的脚本、邮件草案或方案,让你“醒来时工作已经做了一半”。
- **主动建议:** AI 会提议它当天可以帮你自动完成哪些任务
******案例2:****** ****Reddit 每日摘要****
Cron 自动化任务,帮你高效筛选并阅读感兴趣的内容:
- **自动汇总:** 每天获取你最喜欢的 Subreddit(版块)中表现最好的帖子。
- **深度搜索:** 按主题搜索帖子或提取评论列表,获取更多背景信息。
- **建立清单:** 帮你把想看的、想回复的内容整理成短列表,方便稍后处理
**案例3:项目状态管理系统**
用事件驱动的逻辑来取代传统的看板(如 Kanban 或 Trello),解决项目管理中手动更新滞后、背景信息丢失的问题
- **告别手动:** 不再手动挪动看板卡片(Kanban),直接对 AI 说“XX 做完了”或“YY 卡住了”。
- **自动更新:** AI 自动修改数据库状态,并同步关联你的 GitHub 代码提交记录。
- **随时追溯:** 像问同事一样问 AI:“那个功能进度如何?”或“为什么当时改了方案?”,它会根据历史记录直接回答
## **九、写在最后**
站在 2026 年初的起点,OpenClaw 不仅仅是一个工具,它是您与 AI 时代共同进化的数字资产。
**1.** **自动进化的“大脑”**
随着底层模型(Claude、GPT)的持续迭代,您的 OpenClaw 助手在**无需更改配置**的情况下,理解力与执行力将自动升级。它会越用越聪明,犯错越来越少。
**2.** **从文字到全感官的跨越**
未来的 OpenClaw 将普及**多模态**交互:
- **看与听:** 实时分析摄像头画面,支持自然的语音对话。
- **动:** 不再止于屏幕,而是能控制外部设备执行物理世界的任务。
**3.** **Agent 协作网络**
未来您拥有的将是一个“数字团队”。OpenClaw 作为核心“管家”,协调多个专项 Agent(写代码、管邮件、做分析)各司其职,而您只需发号施令。
**4.** **越早开始,优势越大**
**技术可以买到,但“记忆”不能。** 今天搭建的助手,每一天都在积累关于您的工作习惯、项目状态和处理偏好。一个使用了半年的助手,其核心价值在于那 6 个月的**认知积累**。这种先发优势,是任何新工具都无法瞬间替代的。
正在看这篇文章的朋友,你有在使用OpenClaw吗? 你用OpenClaw做了哪些有意思的东西呢?欢迎评论区一起讨论!
< END >
最近小灰创建了一个AI副业交流群,对AI和副业变现感兴趣的朋友,都欢迎进群交流。扫码添加小灰微信,备注“ai“即可进群:

---

原创 小灰&子悠 程序员小灰
继续滑动看下一个

程序员小灰
向上滑动看下一个[^54]: # Nano Banana 2 的 16 个邪修玩法,漫画转真人已经落后好几个版本了!
## 来源
[原文链接](http://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247583106&idx=1&sn=c02dd7bc5b3e01f7d6de1ee75d771426&chksm=e83edc71c068da4885d45863616ad9dbdbfacea8f30c7357fd656306be292aa6c4b847ee26b0&scene=0&xtrack=1#rd)
## 正文
公众号名称:程序员鱼皮
作者名称:程序员鱼皮
发布时间:2026-03-05 16:43
原文链接:[https://ai.codefather.cn](https://ai.codefather.cn)
大家好,我是程序员鱼皮。
谷歌官方的 AI 生图大模型 Nano Banana 又整新活了!
前几天谷歌悄悄上线了 Nano Banana 的 2.0 版本,底层换成了 Gemini 3.1 Flash,直接冲上 HuggingFace 全球文生图排行榜第一。
相比上一代,整体质量没有太大的进步,核心升级就四个字:**又快又便宜**。
同样一张 1K 图,Banana 2 的价格大概比 Pro 便宜了一半。还多了两个杀手锏:生图时能联网搜索实时信息,以及支持 8:1 这种极端比例的超长画布。另外参考图的上限提到了 **14 张**,包括 10 张物体 + 4 张角色。
我花了 1 天时间,把最近全网比较火的新玩法都测了一遍,整理出 16 个最有意思的分享给大家,并附上了精简版提示词可以参考。
如果你之前只用过 “插画转手办”、“漫画转真人”,看完这篇你可能会觉得自己白用了半年。

当然,如果你懒得自己一个个试提示词,也可以直接用我做的 **AI 绘图提示词工具**,精选了一批热门的 AI 绘图风格模板,比如吉伊卡哇、蜡笔小新、吉卜力、赛博朋克、美式波普漫画、黏土定格动画、复古手绘等等,一键生成提示词,复刻爆款图片。
点击头像,然后私信回复 aidraw,可获取 AI 绘图模板和提示词工具。
不仅如此,刷到好看的图想要复刻,只需上传图片,AI 会自动分析,反向生成提示词模板,再也不用求别人要提示词了!

## 1、一张海报,自动翻译成全球版本
这个是 Google 官方力推的用法,他们专门做了一个 Demo 叫「Global Kit Generator」。
操作很简单,只需上传一张海报,描述你的目标语言,它可以直接帮你一次性生成对应的多语言版本。字体、配色、排版基本都保持原样,只把文字翻译了。
> Translate all text in this advertisement image to the language of {market}. ONLY translate the text – do not add any cultural imagery, flags, national symbols, or stereotypical visual elements.
>
有意思的是,它翻译的时候是带脑子的。比如你拿一张《星际穿越》的海报去翻译台湾繁体版,它给你翻的是《星际效应》—— 这是台湾的正式译名,不是粗暴地把简体转繁体。

如果你有做跨境业务的需求,这个功能能帮你省掉大量翻译 + 重新排版的工作。
## 2、输入城市名,生成窗外的风景照
另一个官方 Demo 叫「Window Seat」,输入一个城市名和具体景点,它会自动调用实时天气数据,然后生成一张 “从窗户看出去” 的风景照。
关键在于它用了 Nano Banana 2 新加的 **Image Search** 能力。不光搜文字资料,还会搜真实的图片做参考,所以生成出来的风景特别有真实感。
> Generate a photorealistic window view poster based on the following data: location: ${城市名}, specific_view:${景点}, Weather: ${天气}, aspect\_ratio: 16:9
>

## 3、联网生图
这是 Nano Banana 2 我个人觉得最黑科技的功能。
传统的 AI 生图模型是 “闭卷考试”,它只知道训练数据里有的东西。但 Nano Banana 2 能在生图的时候调用 Google 搜索和图片搜索来获取实时信息。
比如你让它画 “今天 NBA 的比分”,它会先去搜真实比分,然后再画出来。
> Search for the latest NBA game scores from today, then generate a sports infographic poster showing the final scores, team logos, and key player stats.
>

做新闻类自媒体、做实时资讯配图,这个功能太实用了。以前你得先自己查信息,再手动写进提示词;现在直接一句话,它自己查自己画。
## 4、8:1 超长画布
这是 Nano Banana 2 的独家能力,Pro 版本都做不到。再原先的基础上,它还额外支持 1:4、4:1、1:8、8:1 这样的极端宽高比,做网页 Banner、知识卡片和时间线长图,场景更丰富了。
你可以让它画一幅 “AI 版清明上河图”,也可以画一条从太阳到冥王星的太阳系全景长卷。选 4K 分辨率的话,一张图大小能到 20MB,细节非常丰富。
> A cinematic ultra-wide 8:1 panoramic illustration of the entire solar system, from the Sun on the far left to Pluto on the far right, set against a deep black starfield with nebula accents, photorealistic rendering, 4K resolution
>

不过在生成的时候,我也发现了一个小问题,预览没有问题的图片,下载后却出现了内容位移,上面这张图是不是还挺明显的?
## 5、模仿笔迹
上传一张带手写文字的图片,让它用相同的笔迹写新的内容,相似度还挺高。
> 模仿图片里的字迹,用同样字迹的手写体,在下面加上一行“程序员面试就用面试鸭”的手写字
>

不过如果字写得很 “个性”,那 AI 模仿得效果就比较一般了。
据说 Google 团队把 “文字渲染” 当成了训练的核心指标。他们认为如果模型能把字写好,那图片的其他方面也不会差。做手帐风内容、做手写体 Logo、做个性化贺卡…… 想象空间很大。
## 6、珐琅徽章风格一键出图
Gemini 平台这次上了一批新的内置风格预设,其中 Enamel Pin(珐琅徽章)风格非常受欢迎。
选好风格后只需要输入主题,就能生成精致的徽章设计图。
> A highly detailed enamel pin design of a cute sleeping cat curled up on a crescent moon, surrounded by tiny stars.
>

如果你做文创周边,这个功能可以当快速概念稿工具。先批量出一波方案给客户挑,选定之后再精修。
## 7、撕纸分层特效
这个玩法在推特上传播很广,效果确实不错。
给 AI 一张动漫角色的图片,让它在画面上制造撕裂的纸张效果,撕开的部分露出不同的艺术风格,比如你可以选线稿、水墨、水彩、铅笔画等等。一张图里同时展示好几种风格,视觉冲击力非常强。
> task: "edit-image: add widened torn-paper layered effect" interior\_style: mode: "line-art" / "sumi-e" / "watercolor" / "pencil-drawing"
>

而且这个提示词用了类似 YAML 的结构化写法来控制每一层的效果,思路值得学习。
## 8、知识可视化
Nano Banana 2 在知识科普图生成方面延续了不错的水准,复杂概念、流程图、知识对比都能画得逻辑清晰、排版美观。
做 PPT 插图、做教学图解、做公众号配图,完全可以让 AI 帮你快速配图。
## 9、一键生成九宫格大头贴
这个玩法特别适合做社交媒体素材,拿来做表情包、做小红书封面图,都很好用。
让 Nano Banana 2 先生成一张九宫格的大头贴拼图,每个格子的表情动作都不一样,还可以再让它拆分成独立的单张照片。而且因为 Nano Banana 2 单价比 Pro 便宜很多,你可以尽情生成不心疼。
> Generate a 3x3 grid photo booth picture of Elon Musk. Each of the 9 squares shows Elon in a different expression and pose.
>

## 10、给经典电影生成 PS1 游戏盒
不知道有没有跟我一样的 90 后,看到 PlayStation 1 时代那种低多边形风格的游戏封面就满满的回忆杀。
现在你可以让 Nano Banana 2 给任何经典电影生成一个 “PS1 时代电影改编游戏” 的包装盒,效果逼真到像是你小时候真的玩过这个游戏。
> A photorealistic image of a Playstation 1 game case for "The Matrix" movie tie-in game. The case has the classic PS1 black border and jewel case design.
>

《黑客帝国》、《侏罗纪公园》、《哈利波特》…… 你随便试,每一个出来都很有那味儿。
## 11、一次性搞定角色设定全家桶
如果你想做一个原创 IP 角色,Nano Banana 2 可以一次性帮你生成完整的角色设定:正面 / 侧面 / 背面三视图、表情参考、常见动作姿势、服装变体,全部在一张图里。
> Generate a complete character design sheet for an original anime character: a 16-year-old female mage with short pink bob hair, green eyes, wearing a navy blue school uniform with a magical cape. The sheet includes: 1) Three-view turnaround; 2) Expression sheet with 6 expressions...
>
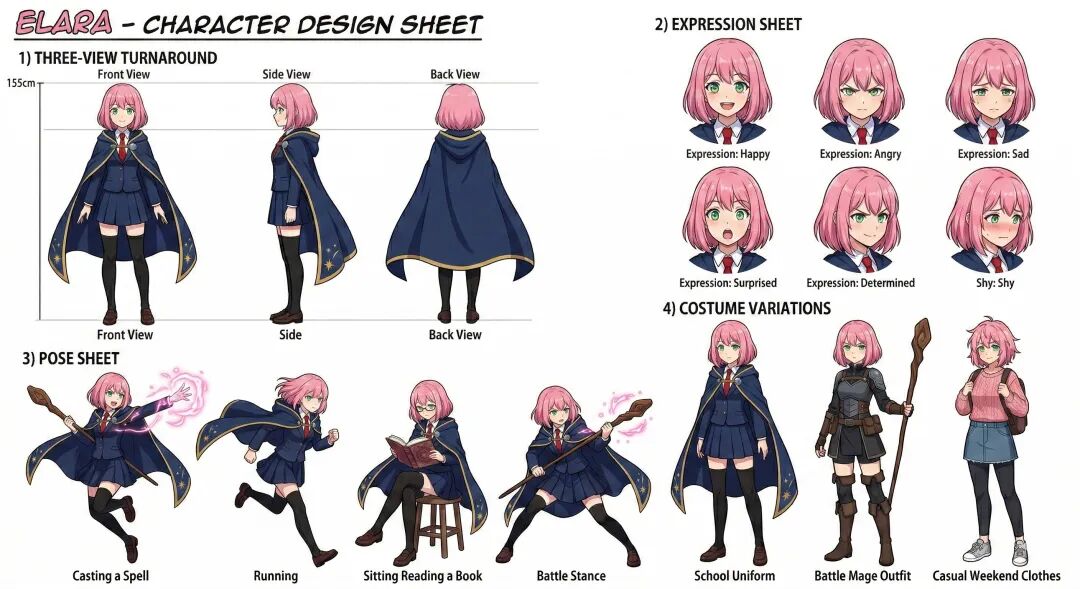
有了角色参考表之后,后续在不同场景下生成这个角色的图片时,一致性就有了保障。
这套流程其实已经是专业游戏美术的标准做法了,只不过现在 AI 帮你把从几天缩短到了几分钟。
## 12、多格漫画分镜
你只需要给一个故事大纲,AI 就能自动帮你构思情节、生成连续的多格漫画分镜。在角色一致性、画面丰富度上,Banana 2 的表现都不错。
> Generate a 6-panel manga storyboard in Japanese shounen style, reading left to right. {story description} . Black and white ink style with screentone shading, dynamic panel layouts with speed lines, 2:3 aspect ratio.
>

## 13、照片秒变俯视图 / AR 标注图
Nano Banana 2 拥有 Gemini 的世界知识,所以可以做很多 “需要理解现实世界” 的操作。
比如上传一张街拍照,让它转换成自上而下的俯视图,并标注摄影师的位置。也可以指定某个建筑,让它叠加 AR 风格的信息标注。
> Generate a photorealistic street-level photo of the Eiffel Tower, then overlay AR-style information annotations on the image. Each annotation has a thin connecting line from the label to the landmark. Use a clean, modern AR UI design with frosted glass effect cards, white text, and small icons.
>

以后旅游博主做景点标注、建筑师做概念展示、教育类博主做图解,都是洒洒水的事儿~
## 14、电影主题复古邮票
这个玩法在 X 上特别火。用一段结构化的提示词,让 Nano Banana 2 生成日式风格的复古邮票,比如带锯齿边缘、雕刻风格的插画、日文标注,整体质感拉满。
> A single vintage postage stamp displayed on a flat matte black background, centered in a 16:9 canvas with small black borders visible on all sides. The stamp itself is an ultrawide horizontal rectangle at approximately 3:1 aspect ratio. The stamp has serrated/perforated zigzag edges on four sides..
>

可以看出,Nano Banana 2 在这种场景下的文字渲染能力确实强。
## 15、小红书 3:4 爆款封面一键出图
利用 Nano Banana 2 的中文理解能力和精准文字渲染,你可以直接用一句自然语言描述,生成符合小红书 3:4 黄金比例(1080×1440)的封面图。
> 生成一张小红书风格的封面图,尺寸 1080x1440,主题是"5 个让皮肤变好的睡前习惯",采用手绘彩色漫画风格,画面温馨清新简洁,重点突出
>

## 16、用代码批量生成
最后一个玩法面向程序员或者愿意折腾的朋友。
因为 Nano Banana 2 的 API 价格打下来了,可以直接写一个程序,或者封装一个 Agent Skills,调用 Gemini 官方的 API 批量生成图片。
比如一次性生成整套电商产品图、整套绘本插画、整套表情包等等。对于内容矩阵型的自媒体和电商团队来说,这就是效率核武器。
## 写在最后
从最早火遍全网的插画转手办,到今天我分享的这 16 种创意玩法,网友们想新 idea 的速度简直快得离谱。
虽然 Nano Banana 2 在精致度上可能还比不过 Pro 版,但 **更快的速度 + 更低的价格 + 联网搜索 + 极端比例画布** 这套组合下来,日常创作场景基本够用了。以前 Pro 版才能做的事,现在 2.0 花更少的钱就能跑出不错的效果。
不会写提示词也不用担心,这玩意本来就不是人来写的,可以直接看 [鱼皮 AI 导航](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247580489&idx=1&sn=ea128f6a8c5d79e641133615f85f7ab8&scene=21#wechat_redirect) 的「AI 绘图提示词」板块,包含提示词模板大全、提示词生成器、图转提示词三大能力。哪怕你没有任何专业知识,也能轻松用 AI 画出好看的图。我也会持续把最新的 Nano Banana 2 玩法模板更新上去。点击头像,然后私信回复 aidraw 就能拿到所有模板

你用过 Nano Banana 2 了么?欢迎在评论区分享你的 Nano Banana 2 玩法和作品~
一些对大家有用的资源:
👉🏻 100+ 编程学习路线 / 实战项目 / 求职指导 [codefather.cn](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247577595&idx=2&sn=34c0eec03ed726c03d19f639e9985fda&scene=21#wechat_redirect)
👉🏻 100+ 简历模板 [laoyujianli.com](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247576607&idx=2&sn=a2fe52e4e4b7008aa7a081b00cfc2469&scene=21#wechat_redirect)
👉🏻 300+ 企业面试题库 mianshiya.com
👉🏻 500+ AI 资源大全 [ai.codefather.cn](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247577417&idx=2&sn=b506d27675379b3f432c9f9ad907fe9d&scene=21#wechat_redirect)
👉🏻 1 对 1 模拟面试 [ai.mianshiya.com](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247577974&idx=2&sn=cb0f3097c4493f7ab980530cb97f2f04&scene=21#wechat_redirect)
👉🏻 动画学算法教程 [algo.codefather.cn](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247576485&idx=2&sn=508ff5e6018405847834b881614bab72&scene=21#wechat_redirect)
---

原创 程序员鱼皮 程序员鱼皮
阅读原文[^55]: # 在动荡时代构建内在结界:斯多葛哲学的实用指南
## 来源
[原文链接](https://b23.tv/q080Zcd?share_medium=android&share_source=weixin&bbid=XX3FC9B34AD4B5C4AF7B792CA2CC540987E3F&ts=1772771344671)
## 正文
**作者:** 好奇的珜
## 1\. 当代的焦虑
随着信息流的高速增长,网络充斥着让人焦虑的新闻;AI 技术日新月异,职场竞争愈发激烈,连生活中的人际关系也似乎随时可能在指尖崩塌。面对如此失控的外部世界,许多人感到自己在拼命奔跑,却仍被时间从指缝中溜走。
信息焦虑的画面
## 2\. 斯多葛的控制二分法
两千多年前的古罗马哲学家已经为这种时代提供了一把“终极武器”。斯多葛学派的核心思路是将所有事物划分为两类:**不可控**与**可控**。
### 2.1 不可控的事物
- 宏观经济的走势
- AI 的迭代速度
- 公司的裁员决定
- 他人是否仍然爱你
### 2.2 可控的事物
- 对事件的判断
- 是否沉下心学习新知识
- 坚持每日哪怕一分钟的微习惯
控制二分法概念示意图
## 3\. 建立内在结界
罗马皇帝马可·奥勒留将这种思维模型形容为“内在堡垒”。它并不是让人对外界视而不见,也不是彻底切断感知,而是把所有投射到外部的情绪雷达收回,形成一座绝对的心理防线。

内在堡垒的形象化表达
## 4\. 微行动的力量
在结界之内,保持对自我的主权尤为关键。即使外部环境动荡不安,也要通过确定的、可量化的微行动来锚定自我:比如把代码写得更漂亮,或每天弹吉他十分钟。这样的细碎行为能够在宏大叙事的空虚中提供实在的支点。

代码编写与吉他练习的微习惯
## 5\. 四字提醒:与我无关
当外部噪音袭来时,心里默念四个字——“与我无关”。这是一种快速的情绪脱钩手段,让情绪不再被外部评价所绑架。

‘与我无关’四字提醒的画面
## 6\. 当现实的铁拳落下
如果公司真的裁员,或是房租如期到期,结界并不能直接解决这些外在问题。但它能让你在面对不可控的冲击时,依然保持清晰的思考与执行力——例如及时更新简历、在面试中保持从容。

面对裁员时的心理结界示意图
## 7\. 结语:真正的自由
建立结界的目的不是逃避现实,而是保存执行力、避免情绪透支。放下对不可控事物的执念,你便获得了真正的自由——不再为外部世界的起伏失眠,也不再在焦虑中耗尽精力。

成为自己国王的象征画面
愿你在这个快要失控的时代,依然能够成为自己的国王。[^56]: # 别被成功学误导:从幸存者偏差到全样本思维
## 来源
[原文链接](https://www.bilibili.com/video/BV1Tzwtz7EMD/?share_source=copy_web&vd_source=332cbfef5943d5ef55ba848756ad9b81)
## 正文
作者:好奇的珜
## 引言:为何学习再多道理仍感人生迷茫?
市面上充斥着所谓的成功学教材:科比凌晨四点起床、乔布斯辍学创业、巴菲特长期持有……于是我们把这些成功人士的作息、思维方式照搬到自己的生活中,期望同样的结果。然而,很多人发现自律到极致后却并未取得预期的成功,甚至感到更加疲惫。

模仿成功人士的日常
## 幸存者偏差的本质
我们经常把成功案例当作唯一的参考,却忽略了大量未能幸存下来的案例。统计学上,这种倾向被称为<span data-type="text" style="color: var(--b3-font-color3);">“幸存者偏差”(Survivorship Bias)</span>——即当我们只能看到经过某种筛选而产生的结果时,往往会产生错误的认知,忽略了被筛选掉的关键信息。
### 案例:二战飞机的机翼加固
二战期间,军方统计了返回基地的飞机,发现机翼上弹孔最密集,便决定加固机翼。统计学家亚博拉·汉沃德指出,这种做法忽视了未能返回的飞机——那些机翼被弹中但仍能飞回的机体并不代表致命伤。真正致命的部位(如驾驶舱、发动机)在返回的飞机上往往没有弹孔,因为这些飞机根本没有返航。

二战飞机弹孔分布图
## 成功背后的隐形因素
成功者往往对自己的成功进行事后归因,把<span data-type="text" style="color: var(--b3-font-color2);">偶然的习惯包装成必然的因素</span>。他们可能恰好赶上时代红利、拥有未被公开的资源,或仅仅是运气的眷顾。人类的大脑倾向于寻找因果关系,却难以接受随机性的作用——这导致了<span data-type="text" style="color: var(--b3-font-color1);">归因谬误</span>。
## 全样本思维:从失败中学习
> [!Tip] 核心观点
> 若只关注成功案例,我们得到的结论往往是“自嗨”。真正的洞见来自对全体样本的审视——包括那些未能成功的人。通过研究失败者的共同困境(资金链断裂、合伙人背叛、市场环境等),可以识别系统性风险,剔除运气噪音。
>

全样本思维示意图
## 实践建议:控制风险,提高成功概率
在缺乏通用成功地图的现实中,我们应遵循以下原则:
- 接受不确定性,避免将单一经验视作普遍真理。
- 构建<span data-type="text" style="color: var(--b3-font-color3);">“全样本”视角</span>,既关注成功也关注失败。
- 识别并控制关键风险点,提高整体成功率。
- 将个人努力与概率提升相结合,而非盲目复制他人的习惯。
## 结语:在不确定的世界中寻找自己的道路
> [!Note] 总结
> 每个人的道路都是独特的。别把别人的成功经验当作固定的地图,而应把它们视为参考点。通过全样本思维、风险管理和持续学习,我们可以在充满意外的生活中,提高生存的概率,走出属于自己的路径。
>
## 逐字稿
\[00:00\] 今日话题,为什么听了那么多道理依然过不好?先停一下,最近我有一个很大的困惑,甚至是一种愤怒。市面上到处都在教我们成功学。他们说科比每天凌晨四点起床,所以你要早起,乔布斯辍学创业,所以学历不重要,巴菲特长期持有,所以你要死抓不放,我照做了。
\[00:20\] 我极度自律,我模仿他们的习惯,我甚至模仿他们的思维方式。但结果呢我不仅没成功,反而把自己弄得筋疲力尽,甚至比以前更差了。是这些道理是假的吗?还是我这个人本身就是个伪劣产品,道理不一定是假的,但你的样本是错的,你陷入了逻辑学上最致命的陷阱,幸存者偏差。你以为你在学习成功的秘诀。
\[00:42\] 其实你只是在盯着幸存者的伤疤。
\[00:45\] 这听起来像是在打仗,生活就是一场战争,而历史是由活下来的人书写的。二战时,军方统计了飞回来的战机,发现机翼上弹孔最多,于是决定加固机翼。但统计学家亚伯拉罕·沃德说:不,我们要加固那些没有弹孔的地方,为什么机翼明明被打烂了?因为那些被打中驾驶舱和引擎的飞机根本就没飞回来。
\[01:06\] 他们坠毁了,他们变成了沉默的数据。你看到的弹孔不是致命伤,那是非致命伤的证明。回到你的人生。当你看着乔布斯说辍学能成功时,你看到的是那一个飞回来的幸存者。在你看不到的阴影里,躺着十万个同样辍学,同样有野心,但最终在加油站打了一辈子工的失败者,死人是不会说话的。如果你只采访中彩票的人。
\[01:27\] 你会得出一个荒谬的结论,去便利店买一张彩票是发财的最佳途径。这太可怕了。你是说那些成功人士总结出来的道理,其实并不全是误导,但很多时候那是归因谬误。很多成功者其实并不真正知道自己为什么成功,他们可能只是刚好踩中了时代的红利,或者拥有某种隐形的资源,但人类的大脑无法接受随机性。
\[01:48\] 我们需要一个解释,于是成功者会回溯自己的人生,把一些无关紧要的习惯包装成原因。这就像古代的皇帝以为日食是因为自己没祭拜天神,你模仿了他的祭拜仪式,但你无法复制他的天时地利,有时候他们成功,甚至是因为有那些坏习惯,而不是因为有那些好习惯,那我该怎么办?如果所有的经验都是偏差。
\[02:09\] 如果所有的道理都是幸存者的自嗨,我还能信什么?我该躺平吗?你不需要躺平,你需要全局思维。当你想模仿一个人的选择时,不要只看那些赚了大钱的人,你要去看看那些坟墓,去看看那些做了同样选择,但失败了的人,他们到底是怎么死的,是资金链断裂,还是合伙人背叛,还是市场因素,根本不存在失败者的教训,往往只有成功者的经验。
\[02:31\] 更接近真理,因为失败剔除了运气的噪音,暴露了系统的底线逻辑。我好像懂了,原来这个世界上没有通用的地图,别人的地图,那是他们走过之后画出来的轨迹,而不是我前方的路。是的,成熟的标志,就是承认不确定性,不要试图寻找必胜的机会。因为捷径只存在于骗子的嘴里,你要做的是提高胜率。
\[02:52\] 控制风险,然后把剩下的交给上帝安排,不要只听他说对了,什么都要听。如果重来一次,由于什么原因,他可能会死掉,只有看清了死亡的深渊,你才能在生存的钢丝上走的更稳。[^57]: # 求你了,别再对自己搞“意志力霸凌”了
# 🌙 为什么昨晚的壮志凌云,总在今晨灰飞烟灭?

### 📌 引言:宏伟计划与实际行动的鸿沟
你是否也有过这种“人格分裂”的经历?深夜痛定思痛要重塑人生,次日清晨却被短视频瞬间“封印”。别急着否定自己的意志力,这其实是**人类大脑的底层出厂设置**在作祟。
---
## 📉 核心逻辑:双曲贴现(Hyperbolic Discounting)
简单来说,人类对收益的感知并非线性的。随着时间的推移,未来的收益在此时此刻的你眼中,价值会呈“断崖式”下跌。

> *注:在该数学模型中,**$V$* *代表奖励的当前价值,**$A$* *是奖励的原始数额,**$D$* *是延迟时间。这意味着:****时间越久,动力越小。***
>
- **当下:** “即时满足”(如刷视频、吃甜食)权重极大。
- **未来:** “远期收益”(如健身成功、升职加薪)被严重低估。

---
## 🧪 心理学实验:关于“钱”的非理性博弈
|**实验组**|**选项 A (即时)**|**选项 B (延迟)**|**最终选择**|
| --| --------------------| ----------------------| ------------------|
|**实验一:现在 vs 一周后**|**立刻**领 100 元 🧧|一周后领 200 元 🧧🧧|**多数人选 A**(落袋为安)|
|**实验二:一年后 vs 一年零一周**|一年后领 100 元 🧧|**一年零一周**后领 200 元 🧧🧧|**多数人选 B**(理性回归)|
**结论:** 当诱惑就在眼前时,我们是冲动的野兽;当诱惑远在天边时,我们才是理性的智者。

---
## 🧠 深度解析:大脑里的“两个自我”
时间不一致性(Time Inconsistency)揭示了我们体内住着的两个灵魂:
1. **🌞 长期自我(Planner):** 住在前额叶皮层,擅长逻辑、全局规划,是你深夜发誓时的样子。
2. **🧛 短期自我(Doer):** 住在边缘系统,受多巴胺驱动,只想要现在的快乐,是你清晨赖床时的样子。

---
## 🛡️ 破局路径:构建“奥德修斯”式的契约
如何防止“短期自我”篡权?你需要增加违约成本,提前锁死选项。
> **背景故事:** 古希腊英雄奥德修斯为了抵抗海妖塞壬的致命歌声,命令水手用蜡封住耳朵,并将自己紧紧绑在桅杆上。
>

---
## ✅ 5 个实操建议:从“想做”到“必做”
- **📱 物理屏蔽:** 睡前将手机放客厅,或使用物理手机锁盒。
- **💸 利益捆绑:** 寻找“对赌伙伴”,未完成计划则自动触发扣款。
- **🤖 强制工具:** 使用专注类 App,开启“深渊模式”,屏蔽所有干扰。
- **✨ 微量奖赏:** 将长期目标拆解。完成 30 分钟阅读后,立即奖励自己喝一杯喜欢的咖啡。
- **🤝 社交监督:** 在公开朋友圈打卡,利用“面子成本”形成外部约束力。
---
## 💎 结语
“双曲贴现”是进化留给我们的生存本能,承认它,而不是对抗它。**聪明人从不靠意志力死撑,而是靠设计机制来“赢过”那个冲动的自己。**
[^58]: # 为什么越努力,越快失败?——大脑戒备、活化能与微习惯的科学解答
## 来源
[原文链接](https://www.bilibili.com/video/BV1YDcpz6E2v/?share_source=copy_web&vd_source=332cbfef5943d5ef55ba848756ad9b81)
## 正文
**作者:** 好奇的珜
## 引子:过度努力的悲剧
一位听完“双曲贴现”课程的同学,激动地对导师说:“我照你说的做了”。翌日,他给自己设定了每天背50个单词并跑5km的宏大计划。然而,仅两天后,他便彻底崩溃,陷入自我怀疑:是否天生缺乏意志力?

主角对熊大说‘我照你说的做了’,展现过度计划的情境
## 多巴胺的陷阱:宏大目标的兴奋与恐惧
制定宏大目标时,大脑会释放大量多巴胺,产生强烈的期待感,这是一种“多巴胺骗局”。在想象成功的瞬间,大脑感到愉悦,却忽视了实际执行时的阻力。

大脑因预期成功产生多巴胺兴奋的瞬间
## 杏仁核的警报:大脑的防御机制
负责恐惧和防御的杏仁核在感知到潜在风险时会立即报警。例如,当我们对大脑说“我要跑5km”时,杏仁核会发出“太累、太危险”的信号,强迫我们返回安全区。目标越宏大,杏仁核的抵抗越剧烈。

杏仁核发出警报,提示跑5km的潜在风险
## 活化能:启动门槛的物理类比
在物理学中,推动静止的重物需要克服所谓的活化能——即启动的那一瞬间最为困难。一旦物体开始移动,维持运动所需的力大幅下降。做事的逻辑与此相同:启动门槛越高,持续行动的难度越大。

活化能概念的图示,静止重物的启动难度
## 微习惯:把门槛砍到不可思议的小
要降低启动门槛,只需要把目标拆解到极小的程度。例如,背一个单词、做一个俯卧撑,而不是一次性背50个单词或跑5km。微习惯的核心不是为了快速达成大成果,而是让杏仁核不再报警,从而允许行为启动。
当你仅做一个俯卧撑时,杏仁核会认为这不构成挑战,于是放行。完成第一动作后,静摩擦力已被克服,第二、第三个动作比第一个更容易。此时,你锻炼的不是肌肉,而是“开始的能力”。

微习惯示例:只做一个俯卧撑,降低启动门槛
## 身份的转变:持续小动作的力量
坚持每天背一个单词,累计100天后,你的潜意识会形成一种身份认同:你是一个能够坚持学习的人。这种身份的转变远比一次性背完1000个单词更为珍贵,因为行为可以伪装,而身份不可伪装。
当你相信自己是读书人时,你自然会完成阅读;相反,如果把自己标记为“只想完成任务的差生”,逃课便成为默认行为。

坚持背一个单词100天后的身份认同变化
## 实践指南:把宏大目标拆解为微小行动
从今天起,忘掉宏大的目标,将其撕碎成可笑的尘埃。每次只做一个极小的动作:背一个词、写一行代码、阅读一页书。不要试图用一次性的大行动锁定未来,而是用这些微不足道的动作撬动人生。

结束语:将宏大目标碎成微小尘埃的视觉象征
## 结语:慢即是快
所谓“慢就是快”,并非消极放任,而是通过持续的、可管理的微行动,实现复利式的成长。真正的自律不是苦行僧式的自虐,而是像呼吸一样自然,甚至让人感觉不到自己在努力。[^59]: # 运维工程师必存!存储知识,万字全解!
## 来源
[原文链接](https://mp.weixin.qq.com/s/8ikDSWLydRpOz5ysgOYZ2A)
## 正文
公众号名称:开源Linux
作者名称:CloudMan
发布时间:2026-03-02 08:00
原文链接:[https://www.linuxyz.cn](https://www.linuxyz.cn)
在大数据万物互联时代,数据呈爆炸式增长,芯片具备巨大的计算能力,进而大幅提升了人工智能 (AI) 及边缘计算 (Edge Computing)等巨量运算架构的应用需求。
你想过吗,数据这么庞大,放在哪里好?这就不得不提到我们的存储技术。
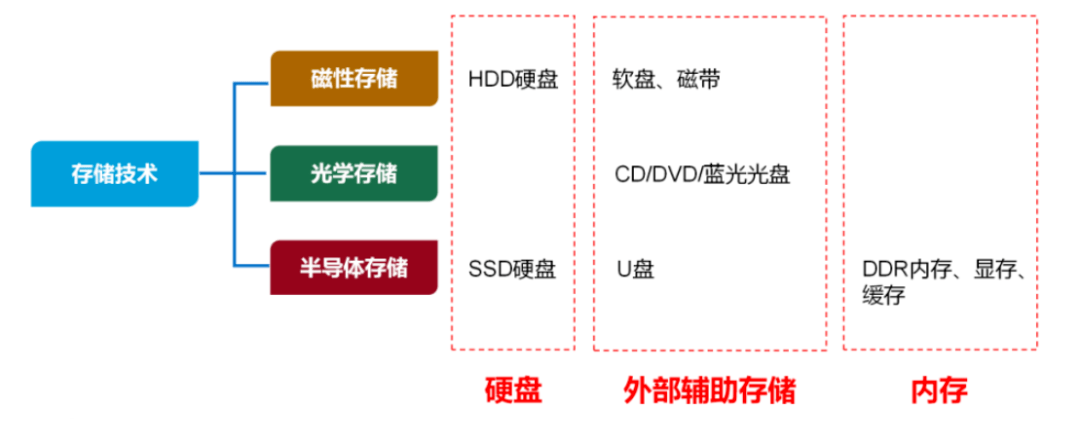
在这一领域,其实很多粉丝都很感兴趣,但都苦于不知如何入门,今天这一篇万字文章,帮你搞定入门科普。
**01**
**存储简介及存储方式**
**01** **简介**
存储就是根据不同的应用环境通过采取合理、 安全、有效的方式将数据保存到某些介质上并能保证有效的访问。
总的来讲可以包含两个方面的含义:
- 一方面它是数据临时或长期驻留的物理媒介;
- 另一方面,它是保证数据完整安全存放的方式或行为。
**02** **三种常见存储方式 DAS、NAS和SAN**
**1.** **DAS**
DAS(Direct Access Storage —直接连接存储)是指将存储设备通过 SCSI接口或光纤通道直接连接到一台计算机上。DAS这种存储方式与我们普通的 PC存储架构一样,外部存储设备都是直接挂接在服务器内部总线上, 数据存储设备是整个服务器结构的一部分。
**DAS存储方式主要适用以下环境:**
(1)小型网络
因为网络规模较小,数据存储量小,而且也不是很复杂,采用这种存储方式对服务器的影响不会很大。并且这种存储方式也十分经济,适合拥有小型网络的企业用户。
(2)地理位置分散的网络
虽然企业总体网络规模较大,但在地理分布上很分散,通过 SAN或NAS在它们之间进行互联非常困难,此时各分支机构的服务器也可采用 DAS存储方式,这样可以降低成本。
(3) 特殊应用服务器
在一些特殊应用服务器上,如微软的集群服务器或某些数据库使用的原始分区,均要求存储设备直接连接到应用服务器。
**DAS存储的局限性:**
直连式存储依赖服务器主机操作系统进行数据的 IO读写和存储维护管理,数据备份和恢复要求占用服务器主机资源(包括 CPU、系统IO等),数据备份通常占用服务器主机资源 20-30%,因此许多企业用户的日常数据备份常常在深夜或业务系统不繁忙时进行,以免影响正常业务系统的运行。
直连式存储的数据量越大,备份和恢复的时间就越长,对服务器硬件的依赖性和影响就越大。
直连式存储与服务器主机之间的连接通道通常采用 SCSI(小型计算机系统接口,是一种智能的通用接口标准)连接,带宽为 10MB/s、20MB/s、40MB/s、80MB/s等,随着服务器 CPU的处理能力越来越强,存储硬盘空间越来越大,阵列的硬盘数量越来越多, SCSI通道将会成为IO瓶颈;
服务器主机 SCSI ID资源有限,能够建立的 SCSI通道连接有限。
无论直连式存储还是服务器主机的扩展, 从一台服务器扩展为多台服务器组成的群集(Cluster) ,或存储阵列容量的扩展,都会造成业务系统的停机,从而给企业带来经济损失,对于银行、电信、传媒等行业7×24小时服务的关键业务系统,这是不可接受的。
**2.** **NAS**
NAS(Network Attached Storage )—网络连接存储,即将存储设备通过标准的网络拓扑结构(例如以太网),连接到一群计算机上。它是一种专用数据存储服务器。
它以数据为中心,将存储设备与服务器彻底分离,集中管理数据,从而释放带宽、提高性能、降低总拥有成本、保护投资。其成本远远低于使用服务器存储,而效率却远远高于后者。
NAS产品包括存储器件(例如硬盘驱动器阵列、CD或DVD驱动器、磁带驱动器或可移动的存储介质)和集成在一起的简易服务器,可用于实现涉及文件存取及管理的所有功能。
简易服务器经优化设计,可以完成一系列简化的功能, 例如文档存储及服务、电子邮件、互联网缓存等等。集成在NAS设备中的简易服务器可以将有关存储的功能与应用服务器执行的其他功能分隔开。
这种方法从两方面改善了数据的可用性:
- 即使相应的应用服务器不再工作了,仍然可以读出数据。
- 简易服务器本身不会崩溃,因为它避免了引起服务器崩溃的首要原因,即应用软件引起的问题。

**NAS的优点:**
(1)真正的即插即用
NAS是独立的存储节点存在于网络之中,与用户的操作系统平台无关,真正的即插即用。
(2)存储部署简单
NAS不依赖通用的操作系统,而是采用一个面向用户设计的,专门用于数据存储的简化操作系统,内置了与网络连接所需要的协议, 因此使整个系统的管理和设置较为简单。
(3)存储设备位置非常灵活
(4)管理容易且成本低
NAS数据存储方式是基于现有的企业局域网而设计的, 按照TCP/IP协议进行通信,以文件的 I/O方式进行数据传输。
**NAS的缺点:**
(1)存储性能较低
(2)可靠度不高
**3.** **SAN**
SAN(Storage Area Network) 存储区域网络1991年,IBM公司在 S/390服务器中推出了 ESCON(Enterprise SystemConnection管理系统连接 )技术。它是基于光纤介质,最大传输速率达17MB/s的服务器访问存储器的一种连接方式。在此基础上,进一步推出了功能更强的 ESCONDirector(FC SWitch) ,构建了一套最原始的 SAN系统。
SAN存储方式创造了存储的网络化。存储网络化顺应了计算机服务器体系结构网络化的趋势。FC-SAN的支撑技术是光纤通道 (FC Fiber Channel) 技术。
FC技术支持HIPPI、IPI、SCSI、IP、ATM等多种高级协议,其最大特性是将网络和设备的通信协议与传输物理介质隔离开, 这样多种协议可在同一个物理连接上同时传送。当然SAN也可以使用IP通道进行部署---IP-SAN。
FC-SAN的硬件基础设施是光纤通道,用光纤通道构建的 SAN由以下三个部分组成:
- 存储和备份设备:包括磁带、磁盘和光盘库等。
- 光纤通道网络连接部件:包括主机总线适配卡、驱动程序、光缆、集线器、交换机、光纤通道和 SCSI间的桥接器
- 应用和管理软件:包括备份软件、存储资源管理软件和存储设备管理软件。
**FC-SAN的优势:**
(1)网络部署容易;
(2)高速存储性能。
因为 SAN采用了光纤通道技术,所以它具有更高的存储带宽,存储性能明显提高。SAN的光纤通道使用全双工串行通信原理传输数据,传输速率高达1062.5Mb/s。
(3)良好的扩展能力。
由于 SAN采用了网络结构,扩展能力更强。光纤接口提供了10公里的连接距离,这使得实现物理上分离,不在本地机房的存储变得非常容易。
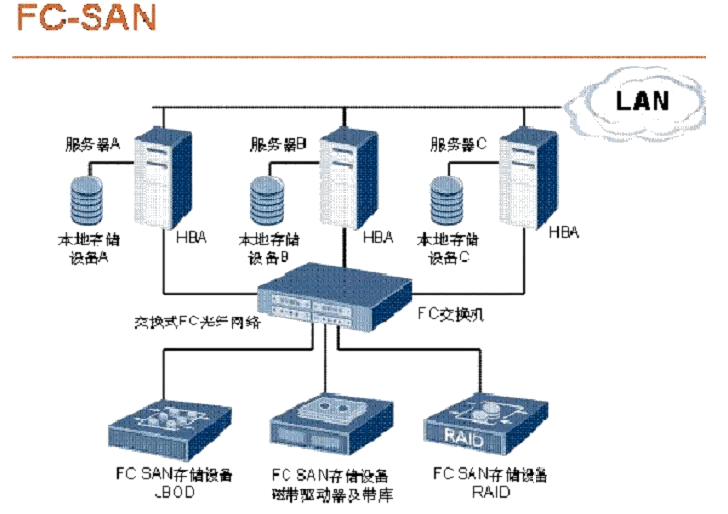
**03** **DAS、NAS和SAN三种存储方式比较**
**1.** **连接方式对比**
从连接方式上对比,DAS采用了存储设备直接连接应用服务器,具有一定的灵活性和限制性;
NAS通过网络(TCP/IP,ATM,FDDI)技术连接存储设备和应用服务器,存储设备位置灵活,随着万兆网的出现,传输速率有了很大的提高;
FC-SAN则是通过光纤通道(Fibre Channel)技术连接存储设备和应用服务器,具有很好的传输速率和扩展性能。
三种存储方式各有优势,相互共存,占到了磁盘存储市场的70%以上。
SAN和NAS产品的价格仍然远远高于 DAS.许多用户出于价格因素考虑选择了低效率的直连存储而不是高效率的共享存储。
客观的说,SAN和NAS系统已经可以利用类似自动精简配置(thinprovisioning )这样的技术来弥补早期存储分配不灵活的短板。
然而,之前它们消耗了太多的时间来解决存储分配的问题增加内链, 以至于给DAS留有足够的时间在数据中心领域站稳脚跟。
此外, SAN和NAS依然问题多多,至今无法解决。但是SAN常用于大型网络存储的建设,并且在混合存储技术成熟的未来, 是颇具潜力的。
**2.** **应用场景对比**
DAS虽然比较古老了,但是还是很适用于那些数据量不大, 对磁盘访问速度要求较高的中小企业;
NAS多适用于文件服务器,用来存储非结构化数据,虽然受限于以太网的速度,但是部署灵活,成本低;
SAN则适用于大型应用或数据库系统,缺点是成本高、较复杂。
**04** **存储常见品牌**
EMC、IBM、NetApp、HP、HDS、DELL、华为等。
**05** **常用介质**
- 硬盘
- 磁带
- 光盘
- 移动存储设备
**02**
**磁盘阵列及 RAID技术详解**
**01** **磁盘阵列**
**1.** **定义**
磁盘阵列(Redundant Arrays of Independent Disks ,RAID),有“独立磁盘构成的具有冗余能力的阵列”之意。
磁盘阵列是由很多价格较便宜的磁盘, 组合成一个容量巨大的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能。利用这项技术,将数据切割成许多区段,分别存放在各个硬盘上。
磁盘阵列还能利用同位检查( Parity Check)的观念,在数组中任意一个硬盘故障时,仍可读出数据,在数据重构时,将数据经计算后重新置入新硬盘中。
**2.** **分类**
磁盘阵列其样式有三种,一是外接式磁盘阵列柜、二是内接式磁盘阵列卡,三是利用软件来仿真。
外接式磁盘阵列柜最常被使用大型服务器上,具可热交换( Hot Swap)的特性,不过这类产品的价格都很贵。
内接式磁盘阵列卡,因为价格便宜,但需要较高的安装技术,适合技术人员使用操作。
硬件阵列能够提供在线扩容、动态修改阵列级别、自动数据恢复、驱动器漫游、超高速缓冲等功能。
它能提供性能、数据保护、可靠性、可用性和可管理性的解决方案。阵列卡专用的处理单元来进行操作。
利用软件仿真的方式,是指通过网络操作系统自身提供的磁盘管理功能将连接的普通SCSI卡上的多块硬盘配置成逻辑盘,组成阵列。
软件阵列可以提供数据冗余功能,但是磁盘子系统的性能会有所降低,有的降低幅度还比较大,达30%左右。因此会拖累机器的速度,不适合大数据流量的服务器。
**3.** **原理**
磁盘阵列作为独立系统在主机外直连或通过网络与主机相连。磁盘阵列有多个端口可以被不同主机或不同端口连接。一个主机连接阵列的不同端口可提升传输速度。
和当时PC用单磁盘内部集成缓存一样,在磁盘阵列内部为加快与主机交互速度,都带有一定量的缓冲存储器。主机与磁盘阵列的缓存交互, 缓存与具体的磁盘交互数据。
在应用中,有部分常用的数据是需要经常读取的,磁盘阵列根据内部的算法,查找出这些经常读取的数据,存储在缓存中,加快主机读取这些数据的速度, 而对于其他缓存中没有的数据,主机要读取,则由阵列从磁盘上直接读取传输给主机。
对于主机写入的数据,只写在缓存中,主机可以立即完成写操作。然后由缓存再慢慢写入磁盘。
**02** **RAID技术详解**
**1.** **简介**
随着计算机应用的日益普及,人们对计算速度和性能的要求也逐渐提高。
在一个完整的计算机系统中,CPU和内存的作用固然重要,但是数据存储设备性能的好坏和速度的快慢也直接影响到整个系统的表现。
本文所要讲解的 RAID技术起初主要应用于服务器高端市场, 但是随着个人用户市场的成熟和发展, 正不断向低端市场靠拢,从而为用户提供了一种既可以提升硬盘速度, 又能够确保数据安全性的良好的解决方案。
本文将对 RAID技术进行较为详细的介绍,希望能够对广大读者有所帮助。
RAID是英文Redundant Array of Inexpensive Disks 的缩写,中文简称为磁盘阵列。其实,从RAID的英文原意中,我们已经能够多少知道 RAID就是一种由多块廉价磁盘构成的冗余阵列。
虽然 RAID包含多块磁盘,但是在操作系统下是作为一个独立的大型存储设备出现。
RAID技术分为几种不同的等级,分别可以提供不同的速度,安全性和性价比。
人们在开发RAID时主要是基于以下设想,即几块小容量硬盘的价格总和要低于一块大容量的硬盘。
虽然目前这一设想还没有成为现实, RAID在节省成本方面的作用还不是很明显,但是 RAID可以充分发挥出多块硬盘的优势,实现远远超出任何一块单独硬盘的速度和吞吐量。
除了性能上的提高之外, RAID还可以提供良好的容错能力,在任何一块硬盘出现问题的情况下都可以继续工作, 不会受到损坏硬盘的影响。
**2.** **RIAD 等级分类**
常用的等级有0、1、3、5、01、10级等。RAID分类通常我们有5种常见的RAID级别,这些级别不是刻意分出来的,而是按功能分的。
不同的 RAID级别提供不同的性能,数据的有效性和完整性取决于特定的 I/O环境。没有任何一种RAID级别可以完美的适合任何用户。
(1) RIAD 0
我们在前文中已经提到 RAID分为几种不同的等级,其中, RAID 0是最简单的一种形式。
RAID 0可以把多块硬盘连接在一起形成一个容量更大的存储设备。最简单的RAID 0技术只是提供更多的磁盘空间,不过我们也可以通过设置,使用RAID 0来提高磁盘的性能和吞吐量。
RAID 0没有冗余或错误修复能力,但是实现成本是最低的。
RAID 0最简单的实现方式就是把几块硬盘串联在一起创建一个大的卷集。
磁盘之间的连接既可以使用硬件的形式通过智能磁盘控制器实现, 也可以使用操作系统中的磁盘驱动程序以软件的方式实现。
图示如下:

在上述配置中,我们把4块磁盘组合在一起形成一个独立的逻辑驱动器, 容量相当于任何任何一块单独硬盘的 4倍。
如图中彩色区域所示,数据被依次写入到各磁盘中。当一块磁盘的空间用尽时,数据就会被自动写入到下一块磁盘中。
这种设置方式只有一个好处,那就是可以增加磁盘的容量。至于速度,则与其中任何一块磁盘的速度相同,这是因为同一时间内只能对一块磁盘进行 I/O操作。
如果其中的任何一块磁盘出现故障, 整个系统将会受到破坏,无法继续使用。从这种意义上说,使用纯 RAID 0方式的可靠性仅相当于单独使用一块硬盘的1/4(因为本例中RAID 0使用了4块硬盘)。
虽然我们无法改变 RAID 0的可靠性问题,但是我们可以通过改变配置方式,提供系统的性能。与前文所述的顺序写入数据不同,我们可以通过创建带区集,在同一时间内向多块磁盘写入数据。
具体如图所示:

上图中,系统向逻辑设备发出的 I/O指令被转化为4项操作,其中的每一项操作都对应于一块硬盘。
我们从图中可以清楚的看到通过建立带区集, 原先顺序写入的数据被分散到所有的四块硬盘中同时进行读写。四块硬盘的并行操作使同一时间内磁盘读写的速度提升了4倍。
在创建带区集时,合理的选择带区的大小非常重要。如果带区过大,可能一块磁盘上的带区空间就可以满足大部分的 I/O操作,使数据的读写仍然只局限在少数的一、两块硬盘上,不能充分的发挥出并行操作的优势。
另一方面,如果带区过小,任何I/O指令都可能引发大量的读写操作,占用过多的控制器总线带宽。
因此,在创建带区集时,我们应当根据实际应用的需要,慎重的选择带区的大小。我们已经知道,带区集可以把数据均匀的分配到所有的磁盘上进行读写。
如果我们把所有的硬盘都连接到一个控制器上的话, 可能会带来潜在的危害。这是因为当我们频繁进行读写操作时, 很容易使控制器或总线的负荷超载。
为了避免出现上述问题,建议用户可以使用多个磁盘控制器。
**示意图如下:**
这样,我们就可以把原先控制器总线上的数据流量降低一半。当然,最好解决方法还是为每一块硬盘都配备一个专门的磁盘控制器。
**RAID 0特性:**

备注:条带卷 有很好的读写性能 不容错
(2)RIAD 1
虽然RAID 0可以提供更多的空间和更好的性能,但是整个系统是非常不可靠的,如果出现故障,无法进行任何补救。
所以, RAID 0一般只是在那些对数据安全性要求不高的情况下才被人们使用。
RAID 1和RAID 0截然不同,其技术重点全部放在如何能够在不影响性能的情况下最大限度的保证系统的可靠性和可修复性上。
RAID 1是所有RAID等级中实现成本最高的一种,尽管如此,人们还是选择 RAID 1来保存那些关键性的重要数据。
RAID 1又被称为磁盘镜像,每一个磁盘都具有一个对应的镜像盘。
对任何一个磁盘的数据写入都会被复制镜像盘中;系统可以从一组镜像盘中的任何一个磁盘读取数据。显然,磁盘镜像肯定会提高系统成本。
因为我们所能使用的空间只是所有磁盘容量总和的一半。下图显示的是由 4块硬盘组成的磁盘镜像,其中可以作为存储空间使用的仅为两块硬盘(画斜线的为镜像部分)。

RAID 1下,任何一块硬盘的故障都不会影响到系统的正常运行,而且只要能够保证任何一对镜像盘中至少有一块磁盘可以使用, RAID 1甚至可以在一半数量的硬盘出现问题时不间断的工作。
当一块硬盘失效时,系统会忽略该硬盘,转而使用剩余的镜像盘读写数据。
通常,我们把出现硬盘故障的 RAID系统称为在降级模式下运行。虽然这时保存的数据仍然可以继续使用,但是 RAID系统将不再可靠。
如果剩余的镜像盘也出现问题,那么整个系统就会崩溃。因此,我们应当及时的更换损坏的硬盘,避免出现新的问题。
更换新盘之后,原有好盘中的数据必须被复制到新盘中。这一操作被称为同步镜像。
同步镜像一般都需要很长时间,尤其是当损害的硬盘的容量很大时更是如此。
在同步镜像的进行过程中,外界对数据的访问不会受到影响, 但是由于复制数据需要占用一部分的带宽,所以可能会使整个系统的性能有所下降。
因为RAID 1主要是通过二次读写实现磁盘镜像,所以磁盘控制器的负载也相当大,尤其是在需要频繁写入数据的环境中。
为了避免出现性能瓶颈,使用多个磁盘控制器就显得很有必要。下图示意了使用两个控制器的磁盘镜像。
使用两个磁盘控制器不仅可以改善性能, 还可以进一步的提高数据的安全性和可用性。
我们已经知道, RAID 1最多允许一半数量的硬盘出现故障,所以按照我们上图中的设置方式(原盘和镜像盘分别连接不同的磁盘控制) ,即使一个磁盘控制器出现问题,系统仍然可以使用另外一个磁盘控制器继续工作。
这样,就可以把一些由于意外操作所带来的损害降低到最低程度。
RAID 1特性:

备注:镜像卷 写入性能一般 读数据快 容错 磁盘50%浪费
(3)RIAD 10
根据组合分为RAID 10和RAID 01,实际是将RAID 0和RAID 1标准结合的产物,在连续地以位或字节为单位分割数据并且并行读 /写多个磁盘的同时,为每一块磁盘作磁盘镜像进行冗余。
它的优点是同时拥有 RAID 0的超凡速度和RAID 1的数据高可靠性。
RAID 10其实结构非常简单,首先创建 2个独立的RAID 1,然后将这两个独立的RAID 1组成一个RAID 0,当往这个逻辑RAID中写数据时,数据被有序的写入两个RAID 1中。
磁盘1和磁盘2组成一个RAID 1,磁盘3和磁盘4又组成另外一个RAID 1;这两个RAID 1组成了一个新的RAID 0。
如写在硬盘1上的数据1、3、5、7,写在硬盘2中则为数据1、3、5、7,硬盘3中的数据为0、2、4、6,硬盘4中的数据则为0、2、4、6,因此数据在这四个硬盘上组合成 Raid10,且具有RAID 0和RAID 1两者的特性。
虽然RAID10方案造成了50%的磁盘浪费,但是它提供了 200%的速度和单磁盘损坏的数据安全性,并且当同时损坏的磁盘不在同一RAID1中,就能保证数据安全性。假如磁盘中的某一块盘坏了,整个逻辑磁盘仍能正常工作的。
当我们需要恢复RAID 10中损坏的磁盘时,只需要更换新的硬盘,按照RAID10的工作原理来进行数据恢复,恢复数据过程中系统仍能正常工作。原先的数据会同步恢复到更换的硬盘中。
总的来说,RAID 10以RAID 0为执行阵列,以 RAID 1为数据保护阵列,它具有与RAID 1一样的容错能力,用于容错处理的系统开销与单独的镜像操作基本一样,由于使用RAID 0作为执行等级,因此具有较高的 I/O宽带;对于那些想在RAID 1基础上大幅提高性能的用户,它是一个完美的解决方案。
RAID 10适用于数据库存储服务器等需要高性能、高容错但对容量要求不大的场合。
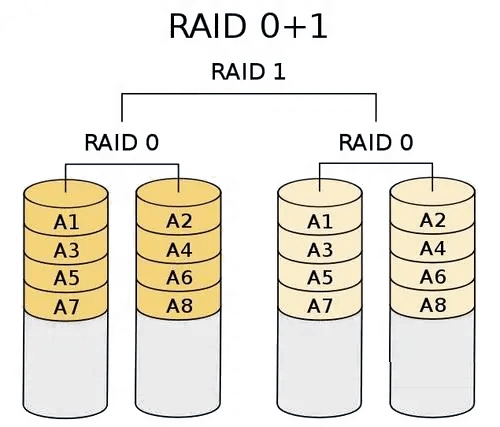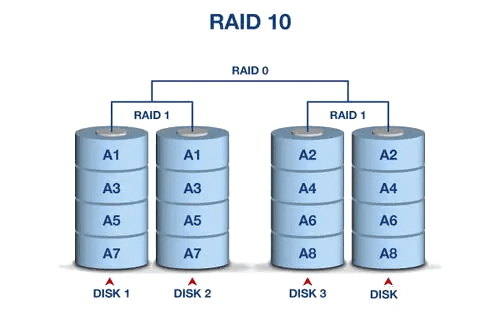
RAID 10特性:

(4)RIAD 2
这是RAID 0的改良版,以汉明码(Hamming Code)的方式将数据进行编码后分割为独立的位元,并将数据分别写入硬盘中。因为在数据中加入了错误修正码(ECC,Error Correction Code),所以数据整体的容量会比原始数据大一些。
(5)RIAD 3
它同RAID 2非常类似,都是将数据条块化分布于不同的硬盘上,区别在于RAID 3使用简单的奇偶校验,并用单块磁盘存放奇偶校验信息。
如果一块磁盘失效,奇偶盘及其他数据盘可以重新产生数据;如果奇偶盘失效则不影响数据使用。
RAID 3对于大量的连续数据可提供很好的传输率,但对于随机数据来说,奇偶盘会成为写操作的瓶颈。
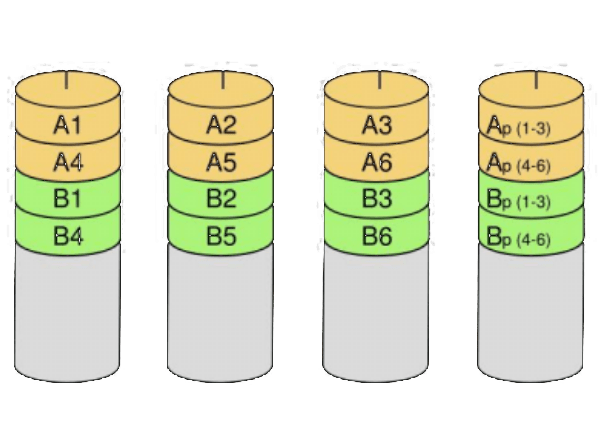
RAID 3特性:

(6) RIAD 4
RAID4和RAID3很象,不同的是,它对数据的访问是按数据块进行的,也就是按磁盘进行的,每次是一个盘。在图上可以这么看, RAID3是一次一横条,而RAID4一次一竖条。
它的特点的 RAID3也挺象,不过在失败恢复时,它的难度可要比RAID3大得多了,控制器的设计难度也要大许多,而且访问数据的效率不怎么好。
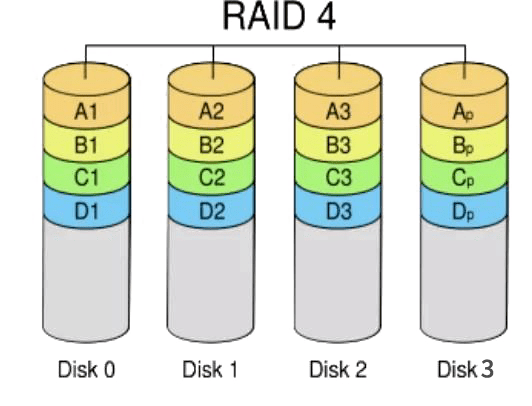
(7) RIAD 5
RAID 5不单独指定的奇偶盘,而是在所有磁盘上交叉地存取数据及奇偶校验信息。
在RAID 5上,读/写指针可同时对阵列设备进行操作,提供了更高的数据流量。
RAID 5更适合于小数据块和随机读写的数据。RAID 3与RAID 5相比,最主要的区别在于 RAID 3每进行一次数据传输就需涉及到所有的阵列盘;而对于RAID 5来说,大部分数据传输只对一块磁盘操作, 并可进行并行操作。
在RAID5中有“写损失”,即每一次写操作将产生四个实际的读 /写操作,其中两次读旧的数据及奇偶信息,两次写新的数据及奇偶信息。
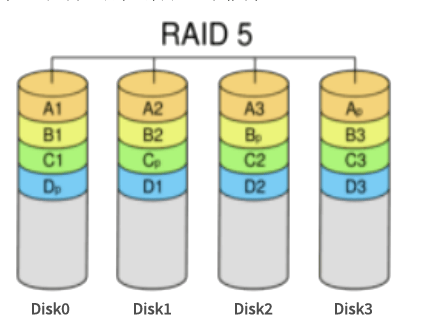
RAID 5特性:

备注:至少3块盘 只允许坏一块盘 读写性能好 坏掉一块盘读性能变慢
**3.** **RIAD 各级别优缺点**
- RAID 0 存取速度最快 没有容错
- RAID 1 完全容错成本高
- RAID 2 带海明码校验,数据冗余多,速度慢
- RAID 3 写入性能最好 没有多任务功能
- RAID 4 具备多任务及容错功能 Parity 磁盘驱动器造成性能瓶颈
- RAID 5 具备多任务及容错功能 写入时有overhead
- RAID 0+1/RAID 10 速度快、完全容错 成本高
**4.** **硬RAID与软RAID**
一般来说,要实现 RAID可以分为硬件实现和软件实现两种。所谓硬 RAID就是指通过硬件实现,同理软件实现的就称作为软 RAID。
下面就来分别解释一下硬RAID与软RAID。
所谓硬RAID,就是用专门的RAID控制器将硬盘和电脑连接起来,RAID控制器负责将所有的 RAID成员磁盘配置成一个虚拟的 RAID磁盘卷。
对于操作系统而言,他只能识别到由 RAID控制器配置后的虚拟磁盘,而无法识别到组成RAID的各个成员盘。
软 RAID就是不使用RAID控制器,而是直接通过软件层实现的 RAID。
与硬RAID不同的是,软RAID的各个成员盘对于操作系统来说是可见的,但操作系统并不把各个成员盘呈现给用户, 而只是把通过软件层配置好的虚拟 RAID卷呈现给用户,使用户可以像使用一个普通磁盘一样使用RAID卷。
---
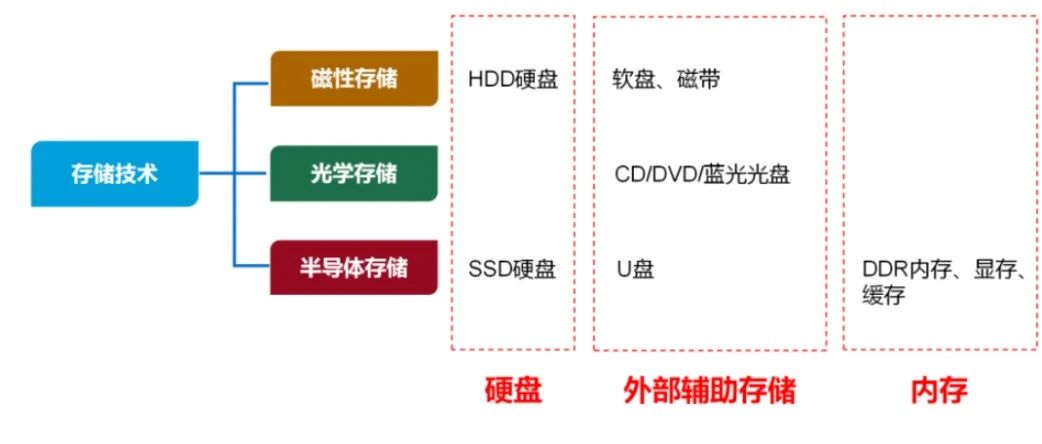[^60]: # MiniMax Office Skills:开源一套生产级办公文档引擎
## 来源
[原文链接](https://mp.weixin.qq.com/s/JKkdMqnHQUnpt0UYRsLTTA)
## 正文
公众号名称:MiniMax 稀宇科技
作者名称:MiniMax
发布时间:2026-03-25 09:07
M2.7 开启了模型的自我进化,是我们第一个模型深度参与迭代自己的模型。在专业办公领域,M2.7 对 Office 三件套 Excel/PPT/Word 的复杂编辑能力有了显著提升,能更好地完成多轮修改和高保真的编辑。
在实际场景的使用中,我们发现,使用Agent处理文档最难的不是写不出来,而是写出来不能用,比如公式存完变成了死数字,模板编辑一轮后格式全乱了,数据透视表保存之后悄悄丢了……文件能打开,但没办法作为最终交付产出。
为了解决这些问题 **,我们搭建了一整套 Office Skills,让生成出来的文档真正经得住交付。**
今天,**我们把这套能力完整开源,包括四个 Office Skills 的代码、设计选型的思路、以及 Skills 自进化的机制,********均采用 MIT 协议****** **。**
如果你也在做 Agent 办公场景,或者正在头疼文档生成出来总是不能直接用,这篇文章会讲清楚两件事:
- 我们是怎样构建 Office Skills 的,为什么在不同文档格式上做了不同的技术选型
- 一套 Skill 怎样在自动评测里持续变稳、持续变强

这四个 Skill 都在生产环境里跑过了多轮自动化测试。用户给出一句话,比如“帮我写一份 Q3 策略报告”,Skill 就能完成从内容组织、排版控制到最终输出的整条流程,生成可直接交付的文档。接下来,我们分别讲讲每个格式的核心难点,以及为什么最后落在现在这套方案上。
**01**
**技术选型:每个决策背后的取舍**
### ① MiniMax-docx:选择 NET OpenXML SDK,而非 python-docx
### 这是整个项目中讨论最久的一个选型。
python-docx 是社区里最常见的 Word 生成方案,轻量、易用。但当需求推进到复杂表格嵌套、多级目录、页眉页脚控制、修订追踪这些复杂场景时,有些功能它不支持,有些它支持但生成出来的文档结构容易出错。
.NET OpenXML SDK 是微软官方维护的底层库,对 ECMA-376(Word 文件格式的官方标准)的实现最完整。选它意味着更高的部署成本,需要额外部署 。NET 运行环境,但换来的是对 Word 文档结构更完整、更可靠的控制力。
**我们在 Word 这个场景里的判断是,文档质量比部署便利性更重要。** 基于这一选型,我们覆盖了三种典型场景:从零生成完整文档、在已有文档上编辑内容而不破坏原有格式、以及将设计模板套用到文档上并自动校验结构是否合规。围绕这些场景,我们沉淀了一批配套文档,包括 OpenXML 格式参考手册、中日韩排版指南、以及 10+ 可直接运行的示例代码,细节在 Github 仓库里。




Omakase 日料菜单示例(可上下滑动)
> Query:为高端 Omakase 日料餐厅体验打造一份精致、高端的菜单,呈现奢华、优雅的质感,具备餐厅级专业水准,布局简洁、措辞考究。需包含以下板块:时令刺身、寿司、烤物、前菜、主厨招牌套餐、甜品及饮品。
>
### ② MiniMax-xlsx:直接操作 XML,而非依赖 openpyxl
Excel 的坑更隐蔽。很多时候不是 Agent 写不出来,而是“写完以后悄悄坏了”。
Openpyxl 是社区里最常见的 Excel 处理方案,但它有一个工程上很难接受的问题:文件读入再写回之后,一些高级内容会被静默丢弃。比如一个包含数据透视表、迷你图、VBA 宏的 Excel 文件,被 openpyxl 打开再保存,这些东西可能就没了,甚至没有报错和提示。对于“读取→编辑→回写”这个最常见的使用场景,这种损失不可接受。
**我们的方案是绕开所有 Python Excel 库,直接在** **XML** **层面操作。** .xlsx 文件本质上是一个压缩包,里面是一组 XML 文件。我们的做法是:解压 → 只修改目标单元格对应的 XML 节点 → 重新打包。这样每次编辑只动需要动的地方,样式、图表、宏都原封不动保留。
另一个关键点是公式。很多方案会把公式提前算好,存一个静态数字进去。我们要求每一个派生值都必须是真正的 Excel 公式,比如 `SUM(B2:B9)`,这样用户打开文件后还能正常编辑和联动。
**为此我们开发了 13 个独立的 Python 工具脚本,覆盖解压打包、列插入、行偏移、公式校验、动态重算、格式审计等环节,同时写了一份 34,000 字的金融格式化标准文档,对齐投行级别的数字格式和排版要求。**
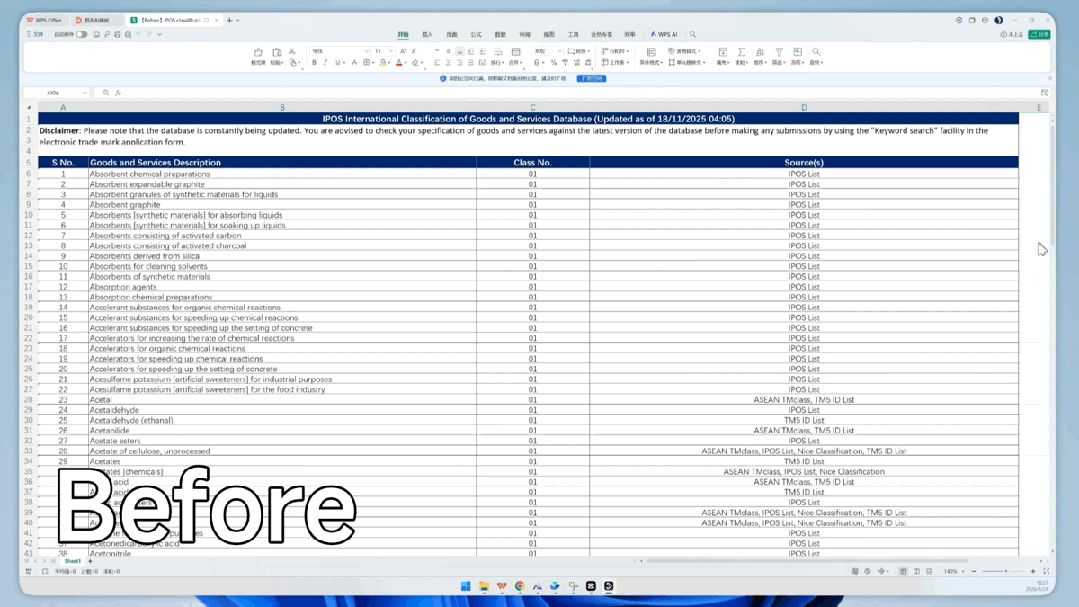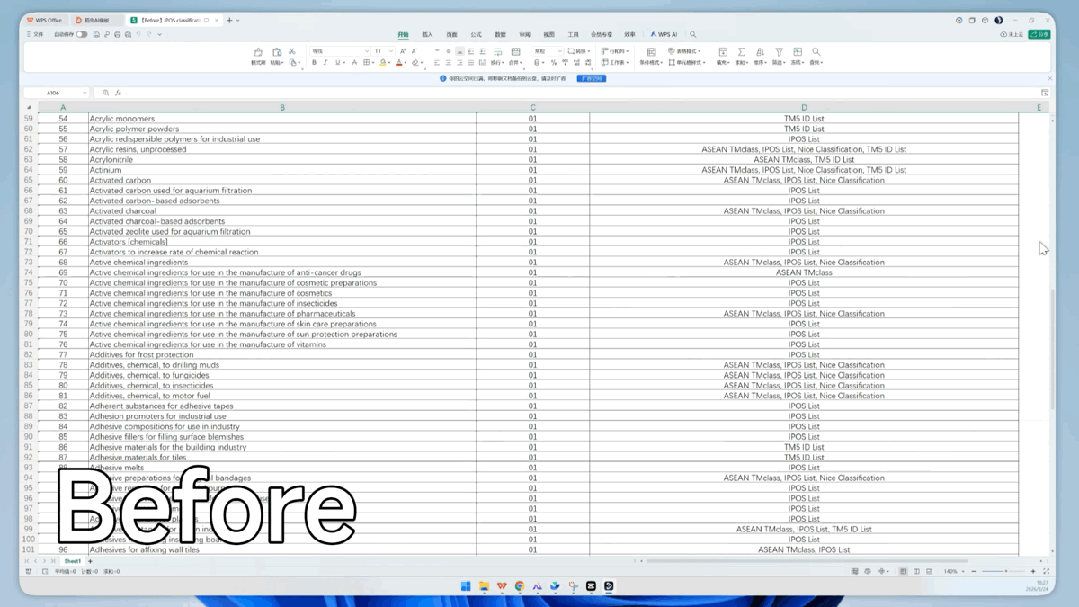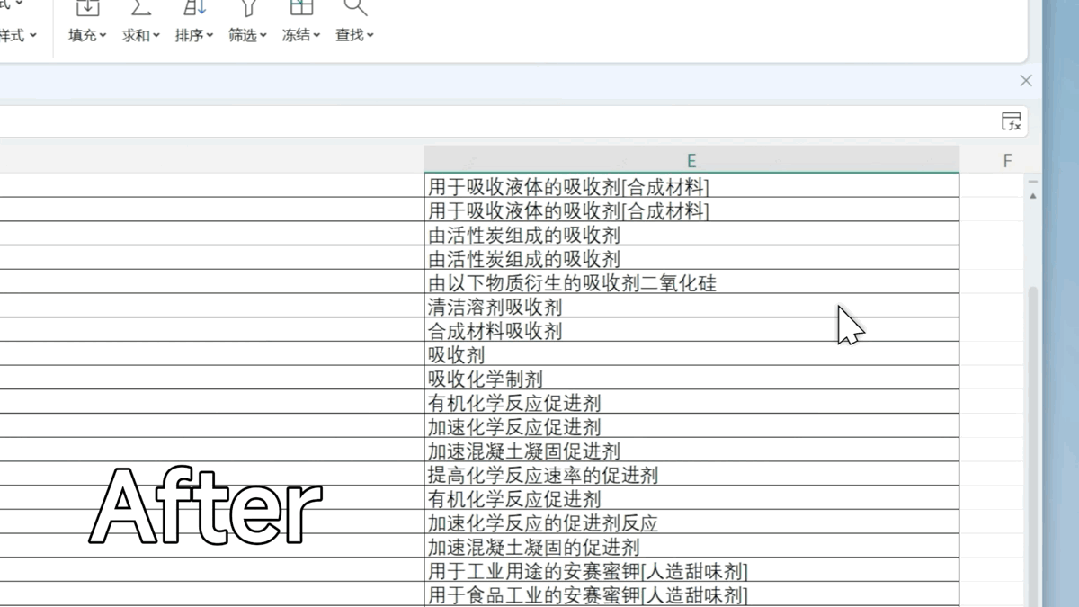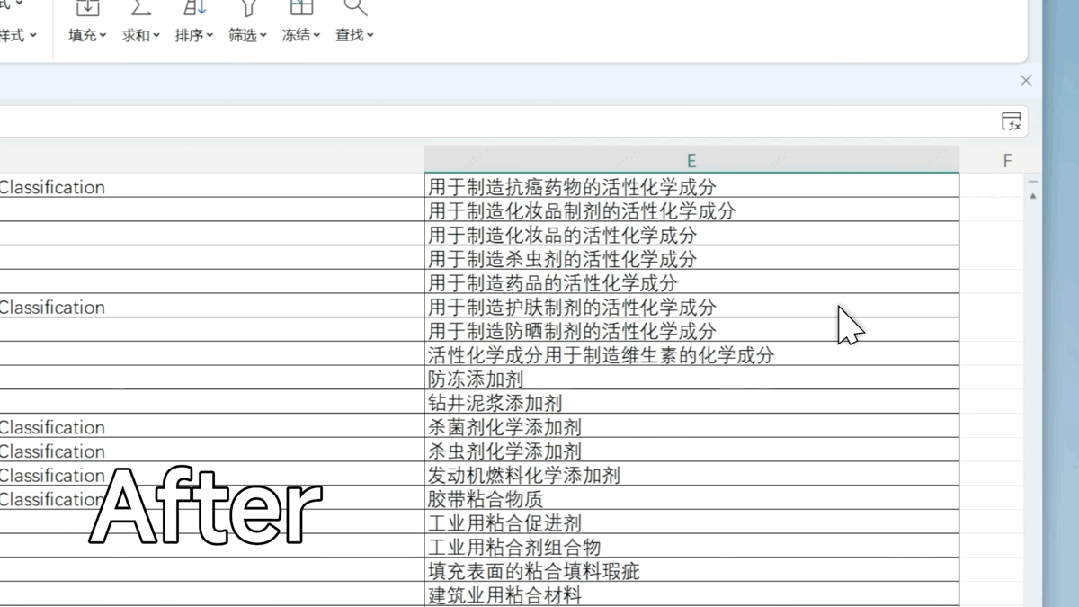
> Query:帮我在表格的最右边加一列,填入对商品服务描述的中文翻译,注意表头的样式以及其余的样式不要发生变化。
>
### ③ MiniMax-pdf:封面和正文要拆成两套渲染引擎
PDF 的核心挑战不在于文字呈现本身,而在于需要做出一套可复用、可扩展的设计系统。我们为 15 种文档类型设计了独立的视觉语言,每一种都有对应的封面模式、字体和配色方案。

**在技术实现上,我们做了一个关键判断:封面和正文使用不同的渲染引擎。**
封面用 HTML + CSS 编写,通过 Playwright 渲染为 PDF。原因在于渐变、网格、混合模式、自定义字体这些设计能力,CSS 原生就支持,而多数 PDF 绘图 API 做这些非常吃力。正文交给 ReportLab 排版,它在段落流控制、分页策略、页眉页脚方面更稳定可控。最后通过 merge 脚本把两部分合并成一份完整的 PDF。
拆成两套引擎,系统更复杂,但封面可以大胆做设计,正文仍然保持工程上的稳定性。






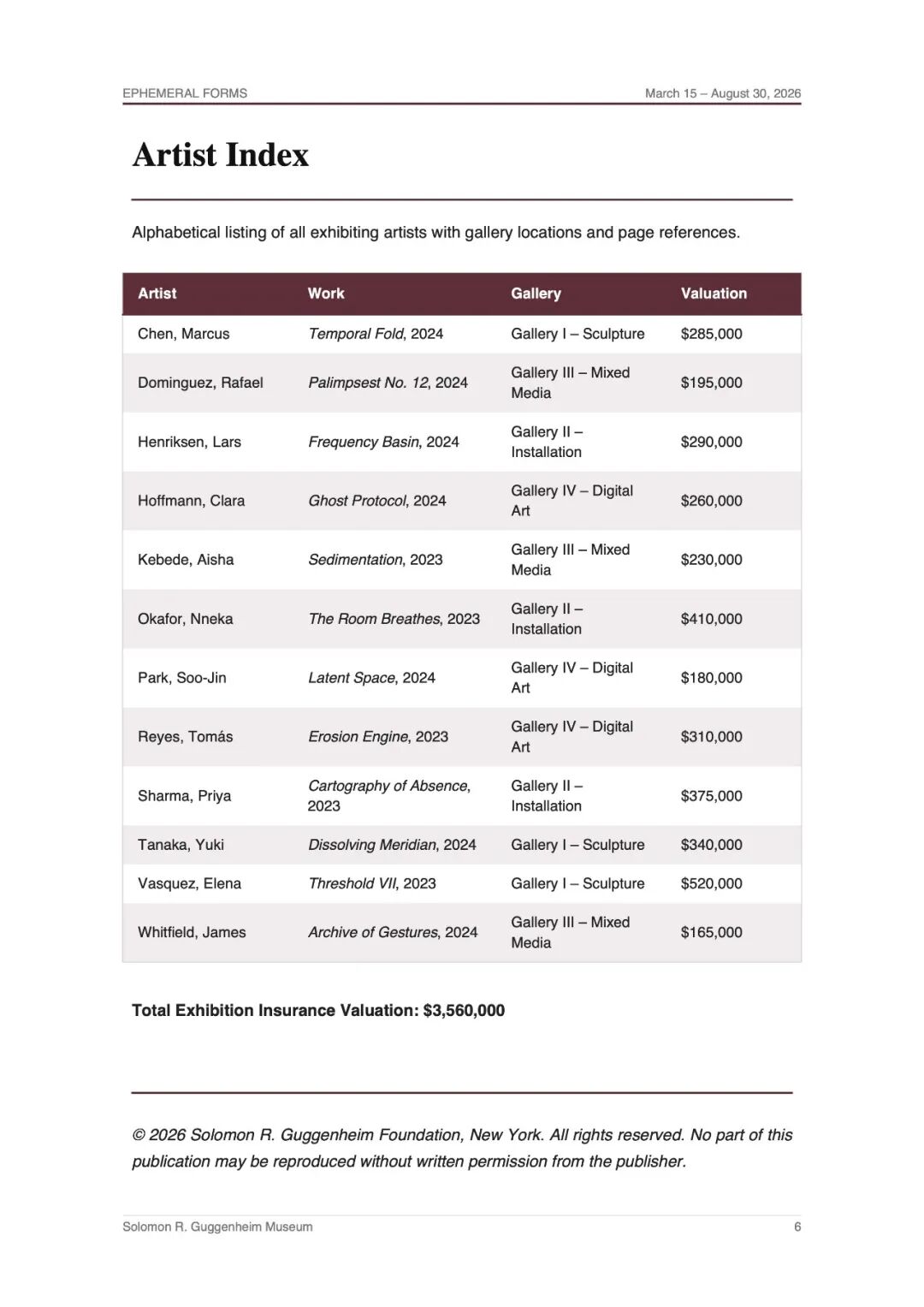
艺术展览 Ephemeral Forms(可上下滑动)
④ PPTX-generator:难点是视觉风格一致性
PPT 生成的难点不在于往 slide 上放内容,而在于视觉风格的统一,字体大小、间距、配色、圆角弧度,任何一个地方不一致,整份演示文稿看起来都会很粗糙。
**我们的做法是先定义一套约束体系,再去做生成。**
页面类型上,我们定义了 5 种标准类型:封面、目录、章节分割、内容、总结。每种类型都有明确的布局规范和元素位置,不是随意摆放。
风格上,我们设计了 4 套配方:Sharp、Soft、Rounded、Pill。每套配方定义了圆角半径、阴影参数、边框粗细、间距比例等一整套数值。切换配方,就能整体改变一份 PPT 的视觉调性,而不用逐页调整。
技术实现基于 PptxGenJS,它是 JavaScript 生态里功能最完整的 PPT 生成库之一。对于已有模板的编辑场景,我们采用和 xlsx 相同的思路:解压 。pptx,直接修改 XML,再重新打包,尽量不破坏原有的格式和结构。

> Query:帮我生成一个介绍 Dota 2 职业选手 AME 的 PPT。
>
**02**
**自循环进化:Skill 如何自己变好**
构建一个 skill 并不难。真正的挑战在于,你怎么知道它下一轮是不是更好了,以及它有没有在修一个问题的同时,又把别的场景弄坏。
在我们看来,办公文档这类任务最困难的地方,不是“第一次做出来”,而是你永远会遇到下一份更难的文档、更刁钻的模板、更多轮真实用户修改。一个 skill 如果不能在失败里持续学习,它很快就会停留在 demo 阶段。
所以我们没有把质量迭代完全交给人工 review,而是搭了一套固定的三阶段循环:**Execute → Evaluate → Fix。**
它的工作方式是:**先执行一组真实用例->再根据规则检查输出是否达标->把失败样例沉淀成可修复的问题,进入下一轮迭代**。**这套机制能够让 Skills 的迭代围绕失败样例持续收敛**,每一轮跑下来,我们都能更清楚地知道问题出在结构、公式、样式,还是模板约束上;修复之后,也能立刻验证,是真的变好了,还是只是换了一种方式出错。
这里对“达标”的定义不只是文件能打开。我们真正关心的是:结构是不是完整,公式还是不是公式,版式在读写之后有没有悄悄变形,模板约束有没有被破坏。一个 xlsx 文件即使成功保存,如果数据透视表丢了、公式被写成了静态数字,在真实交付里都算失败。一个 docx 文档目录能显示却无法正确更新,同样算失败。
这也是为什么前面每个格式我们都选了更复杂的方案——**只有底层链路足够可控,评测才可能对齐到真正有意义的质量指标,而不是停留在“程序没报错”这一层**。
以下视频完整展示了这套系统的运行机制:
**03**
**开源信息**
我们把代码、设计文档和评测框架一起开源,希望这套东西能切实帮到正在做同类工作的团队,减少重复投入,也少在格式细节里反复踩坑。
如果你也在做 AI 文档生成、Agent 工具调用,或者正在把“能跑”往“能交付”推进,欢迎来看看这个仓库。跑通了某个 case,修了某个边角问题,或者有最真实的文档场景,也欢迎直接提 PR、提 issue。
GitHub: github.com/MiniMax-AI/skills
协议:MIT
本次介绍的四个 Skill 已在MiniMax Agent 与 MaxClaw 中上线,可以直接体验:agent.minimaxi.com
Skill开源代码搭配 M2.7 效果最佳,可通过 Token Plan 调用,欢迎大家订阅体验:platform.minimaxi.com/subscribe/token-plan
Intelligence with Everyone.

---

Original MiniMax MiniMax 稀宇科技
修改于
[^61]: # 一条命令让 AI Agent 接管任何软件,港大开源了 CLI-Anything。
## 来源
[原文链接](https://mp.weixin.qq.com/s?__biz=MzUxNjg4NDEzNA==&mid=2247532500&idx=1&sn=c7cd8fb8b1c8e26111ba72c54bdf214f&chksm=f8afbe8660208df2b0c8804c30829424643b804087dae077f19a356d7834f736772bb41d707c&mpshare=1&scene=1&srcid=0325RgGsrUU5j7xzHWC09ohS&sharer_shareinfo=636bdfc02bbfcf23e438f9370de5eb69&sharer_shareinfo_first=636bdfc02bbfcf23e438f9370de5eb69#rd)
## 正文
公众号名称:逛逛GitHub
作者名称:逛逛
发布时间:2026-03-25 15:04
港大刚开源了一个项目,干了一件挺猛的事儿。
**一条命令,把任何有源码的软件变成 AI Agent 可以直接操控的工具。**
不用你自己写 API 对接,不用搞浏览器自动化,把软件源码丢给它就行。
它会自动扫描代码,生成一套完整的命令行接口,Agent 通过命令行就能操控这个软件的全部功能。

上线 4 天 1.5 万多 Star,连续霸占 GitHub Trending。
说实话,这个增长速度有点夸张。
这个项目叫 **CLI-Anything**。
01
一条命令,软件变 Agent 工具
CLI-Anything 的逻辑其实很简单。
你把一个有源码的软件丢给它,它跑一个全自动的 7 阶段流水线。
分析源码 → 设计命令结构 → 实现 CLI → 规划测试 → 写测试 → 生成文档 → 发布安装包。
全程自动,Agent 自己跑完所有步骤,你等着就行。
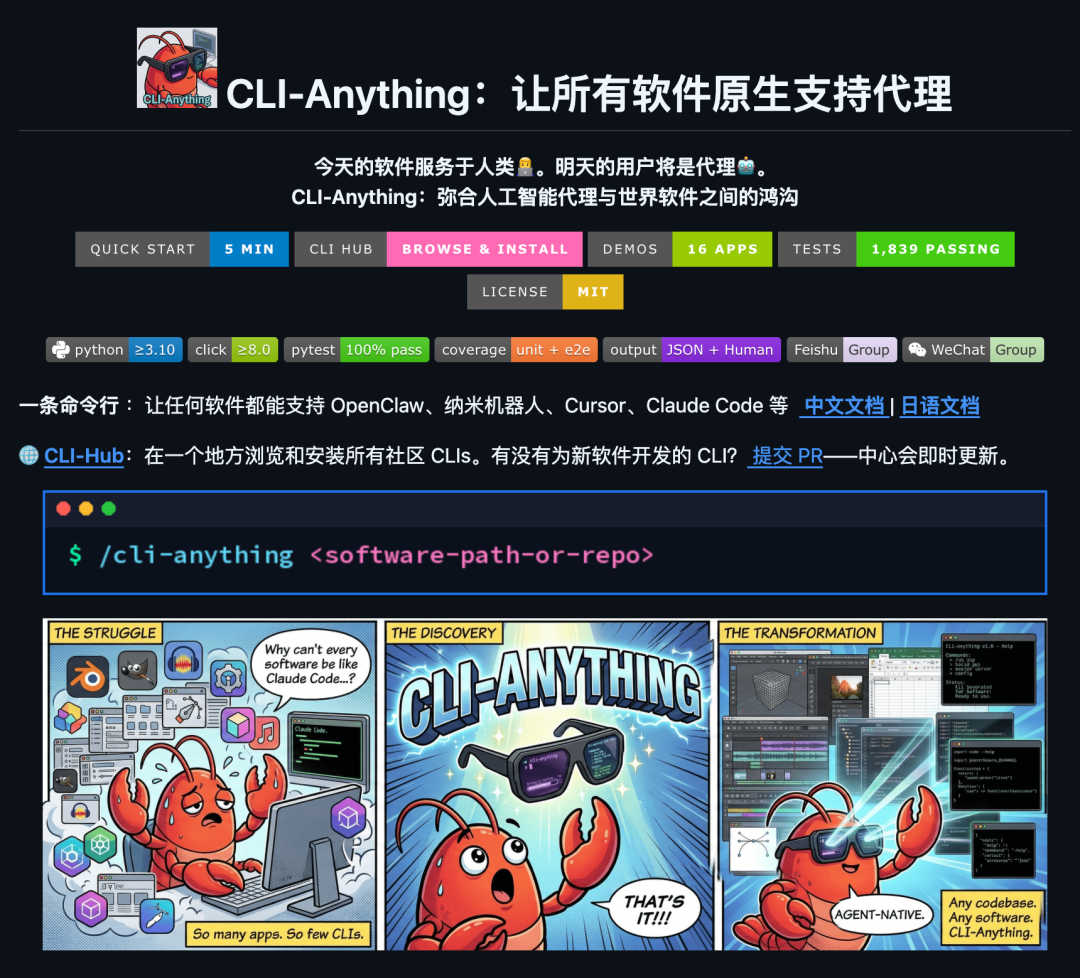
```
开源地址: https://github.com/HKUDS/CLI-Anything
```
目前已经搞定了 16 个软件,覆盖面挺广的。
3D 建模的 Blender、办公套件 LibreOffice、视频剪辑的 Kdenlive 和 Shotcut,还有幕布、Draw.io、Zoom、NotebookLLM。
开发运维方向也覆盖了,Jenkins、GitLab、Grafana 都支持。
**一共 1839 个测试,100% 通过率。**
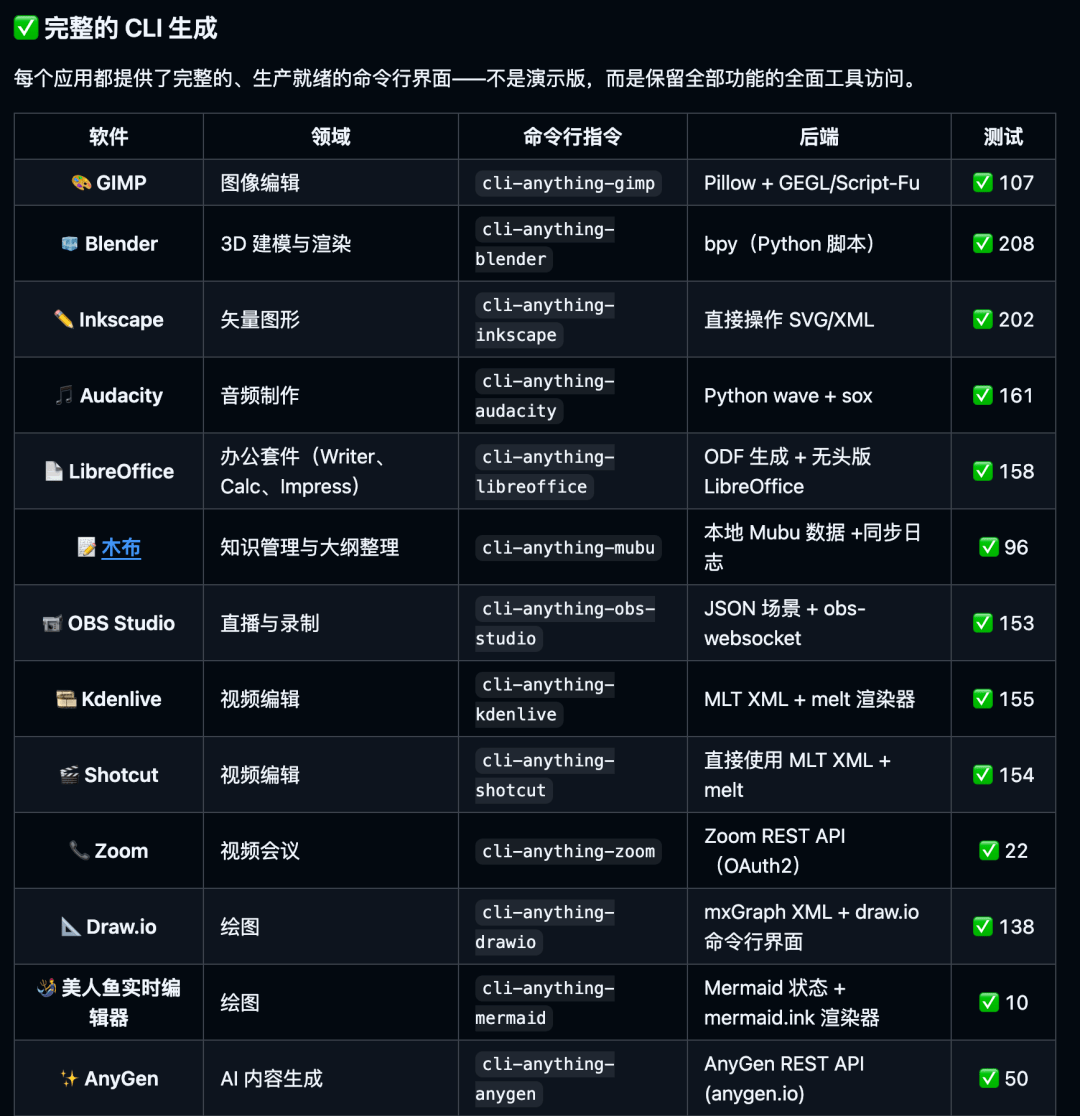
这点我觉得挺关键的,它调用的全是真实的软件后端。
GIMP 修图走的是 GEGL/Script-Fu,Blender 渲染走的是 bpy,LibreOffice 导出 PDF 走的是 headless 模式。
支持 Claude Code、OpenClaw、Cursor、Codex、OpenCode 这些主流 Agent 平台。
02
如何使用
以 Claude Code 为例,两步就能装好:
```
# 添加 marketplace
/plugin marketplace add HKUDS/CLI-Anything
# 安装插件
/plugin install cli-anything
```

装完之后,对 Claude Code 说一句就行:
```
/cli-anything:cli-anything ./libreoffice
```
等它跑完 7 个阶段,LibreOffice 就变成 Agent 可以操控的工具了。
当然也可以直接给 GitHub 仓库地址,不用先下载源码:
```
/cli-anything:cli-anything https://github.com/C4illin/ConvertX
```
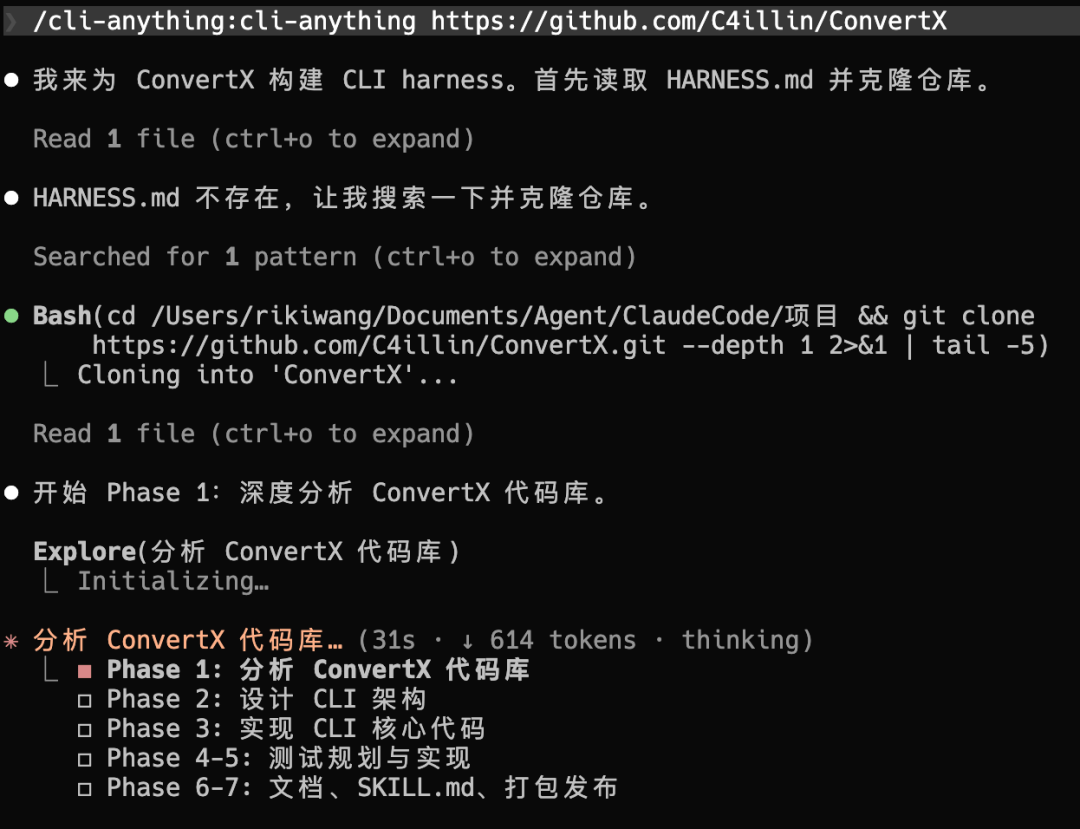

生成完之后,安装就一条命令:
```
cd ConvertX/agent-harness && pip install -e .
```
安装完成,你可以使用如下命令看看怎么用。
```
cli-anything-convertx --help
```
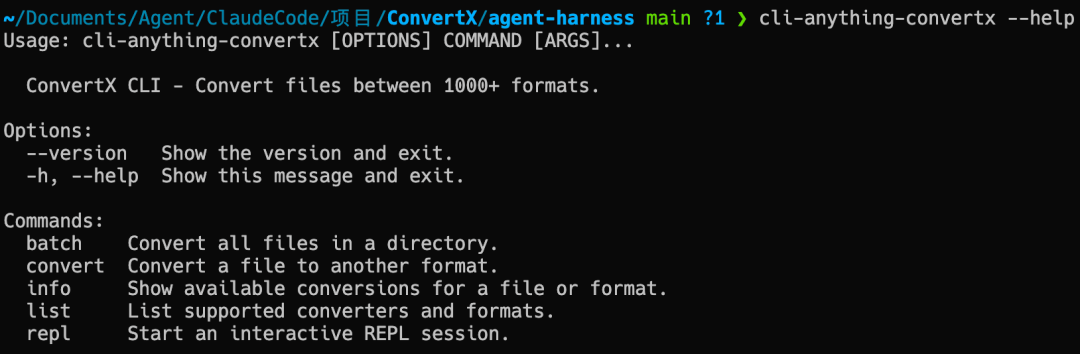
然后你就可以让 Agent 帮你用 ConvertX 进行格式转换了。
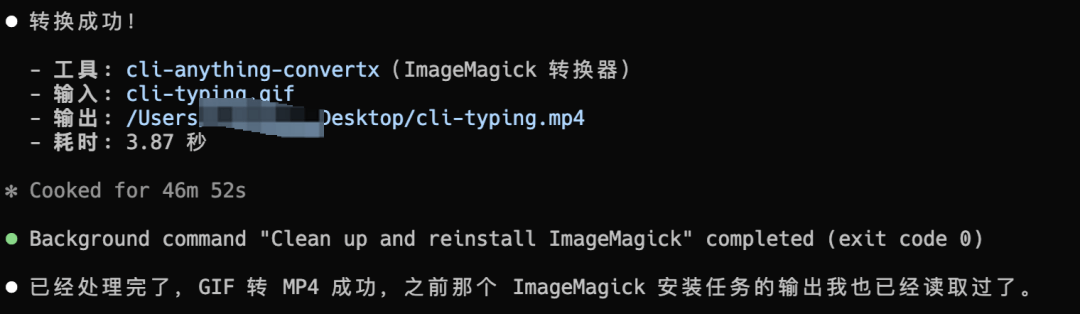
每个命令都支持 `--json` 参数。
Agent 拿到的是结构化数据,直接解析就行。
如果觉得生成的 CLI 覆盖的功能不够全,还可以跑 refine 命令让它继续补充。
03
背后的趋势
这个项目最有意思的其实不是技术本身,是它代表的方向。
CLI-Anything 在 README 顶部写了一句话:
Today's Software Serves Humans. Tomorrow's Users will be Agents.
我理解就是:现在的软件都是给人设计的,以后越来越多的用户可能不是人,是 AI Agent。
Agent 不需要漂亮的界面,不需要拖拽和点击。它要的是结构化输入、结构化输出、可编程的接口。
命令行刚好能满足这些。
输入是文本命令,天然匹配 LLM 的能力范围。输出可以格式化成 JSON,Agent 直接解析。
`--help` 自带文档,Agent 自己就能发现有什么功能可以用。
上个月谷歌刚开源了 Google Workspace CLI,把 Gmail、Drive、Calendar 全打通了。
现在港大又开源了 CLI-Anything,把任意软件都变成 Agent 可以操控的工具。
大厂和学术界都在主动把软件 Agent-ready 化,这个趋势已经挺清楚了。
04
**点击下方卡片,关注逛逛 GitHub**
这个公众号历史发布过很多有趣的开源项目,如果你懒得翻文章一个个找,你直接关注微信公众号:逛逛 GitHub ,后台对话聊天就行了:

---

原创 逛逛 逛逛GitHub[^62]: # Vue Native 发布!官网已上线!
## 来源
[原文链接](https://mp.weixin.qq.com/s?__biz=MzUzNTk3MjE2Ng==&mid=2247522906&idx=1&sn=e54196c273aef73a2ad9ba671d02f30f&chksm=fb0208972463d59c01e5e2d0a53510abf7a3de6aed68dd45773a581696d65fccc613db08bdd1&mpshare=1&scene=1&srcid=03274mEVN4x4tL1Ca8VMpy5c&sharer_shareinfo=28b7920557a6368a3f84aa231aa7ef05&sharer_shareinfo_first=28b7920557a6368a3f84aa231aa7ef05#rd)
## 正文
公众号名称:前端开发爱好者
作者名称:认真努力的小四子
发布时间:2026-03-27 08:33
说实话,这一天很多 **Vue** 开发者已经等了太久。
一直以来,**Vue** 生态其实都有一个明显的“缺口”:
**缺少一个真正成熟的 Native 方案!**
**React** 有 `React Native`,**Flutter** 也越来越成熟, 但 **Vue** 这边:
- `Weex 逐渐淡出`
- `NativeScript Vue 小众`
- `uni-app 更偏工程化方案`
👉 **始终没有一个“官方级”的 Vue Native 方案**
## ⚡ 突发:Vue Native 官网上线!
很突然:刚刚看到 **尤雨溪转发了 Vue + Lynx 项目**
紧接着:官网就直接上线了
**官网地址**:[https://vue.lynxjs.org/zh/](https://vue.lynxjs.org/zh/)
## 🤔 Vue Native(Vue Lynx) 是什么?

**用 Vue 3,开发原生 App(不是 WebView)**
**Vue Lynx** 是一个用于 **Lynx** 的 **Vue 3** 自定义渲染器,让你能够使用 **Vue** 熟悉的`组合式 API`、`单文件组件`和`响应式数据模型`来构建原生 **Lynx** 应用。
你依然可以写:
- `ref / reactive`
---

原创 认真努力的小四子 前端开发爱好者[^63]: # 一文彻底搞懂 Token:词元是什么?输入输出与缓存命中又如何计费?
# 一文彻底搞懂 Token:词元是什么?输入输出与缓存命中又如何计费?
---
## 📖 基本信息
|项目|内容|
| :-----| :----------|
|**作者**|小白debug|
|**来源**|[Bilibili 视频](https://www.bilibili.com/video/BV1oDX8B5EUa/?share_source=copy_web&vd_source=332cbfef5943d5ef55ba848756ad9b81)|
---
## 🔑 一、Token(词元)是什么?
近期,官方首次将"token"正式译为 **"词元"** 。数据显示,我国日均词元调用量已超过 **140 万亿**,这相当于:
- 📚 约 **4.7 亿本**《三体》小说
- 🌐 约 **700 亿篇**网页
- 🗣️ 或一个人连续说话 **3800 万年**的信息量
### 核心概念
我们在 ChatGPT、DeepSeek 等聊天页面输入的是**人类可读的文本**,而大模型只能处理数字。因此,文本在进入大模型之前,必须先经过**分词**处理。
> [!NOTE] ✏️ 关键组件
> 负责分词的组件称为**分词器(Tokenizer)** ,它将文本切分成若干片段,每一段就是一个 token。
>
### Token 的形态
token 可以是:
- ✅ 一个字
- ✅ 一个词
- ✅ 甚至一个标点符号
**举例说明:**
|输入文本|可能的切分方式|
| :---------| :-----------------------------------------|
|"小白"|可能是一个 token|
|"我要"|可能拆分为"我"和"要"两个 token|
|"debug"|可能是一个 token,也可能被拆成"de"+"bug"|

---
## 📊 二、分词的统计规律
分词器并不理解语义,而是依据**统计规律**进行切分。
> [!TIP] 💡 工作原理
> 在海量文本中,经常一起出现的字或词,更有可能被合并为同一个 token。这与人类语言中固定搭配的形成原理类似——高频共现的组合,自然形成稳定的词元单位。
>
完成切分后,分词器会在一张预先建立的**词表**中查找每个 token 对应的**编号**,大模型真正处理的正是这些数字编号。
---
## 💰 三、输入 Token 与输出 Token
用户在对话框中发送的文本,经分词后成为**输入 token**;大模型返回的内容则对应**输出 token**。
### 为什么按 Token 计费?
处理 token 需要消耗 GPU 算力,因此大多数厂商以 token 作为计费单位。
### DeepSeek 计费示例
每百万 token 约对应 **3 本《三体》小说** 的内容量:
|类型|价格(每百万 tokens)|
| :-----------| :----------------------|
|输入 token|约 **2 元**|
|输出 token|约 **3 元**|
### 为什么输出更贵?
> [!IMPORTANT] ❗ 核心原因
> 大模型在处理输入时可以**并行计算**,而生成输出时则必须**逐个 token 依次生成**——前一个未确定,后一个便无从计算。
>
这使得输出过程更慢、更消耗推理资源,价格自然也更高。

---
## ⚡ 四、缓存命中与未命中
在输入 token 的计费中,还存在**缓存命中**与**未命中**的价格差异。
### 什么是缓存命中?
许多 AI 应用在向大模型发送请求时,文本开头通常包含一段固定的**系统提示词(System Prompt)** 。
|场景|说明|价格|
| :-----| :---------------------------------------| :------------|
|**缓存命中**|系统提示词与上次相同,直接复用计算结果|💚 较低|
|**缓存未命中**|前缀发生变化,需要重新计算|🔴 显著上升|
### 💡 实用建议
> [!CAUTION] 🚨 注意
> 若能保持较长的固定前缀不变,便可**有效利用缓存、降低调用成本**。频繁修改系统提示词的前缀,将导致缓存失效,费用大幅增加。
>
---
## 📝 五、视频逐字稿
|时间戳|内容|
| :--------| :---------------------------------------------------------------------------------------------|
|[00:00]|token是什么?最近官方第一次明确把token翻译成词元,我国日均词元调用量已超一百四十万亿...|
|[00:19]|我们在chat g p t或deep seek这样的聊天网页里输入的是一段人读懂的文本,可大模型只能处理数字...|
|[00:41]|小白可能是一个token,我和要可能算两个,也可能算一个...|
|[01:02]|因为人类经常会把一起出现的字做成固定的词和搭配...|
|[01:23]|从里面得到token对应的编号,模型真正处理的就是这些编号...|
|[01:29]|输入和输出token是什么?...|
|[01:50]|输入是两块,输出则是三块...|
|[02:11]|缓存命中是什么?...|
|[02:33]|如果前缀变了就得重算,这就是未命中...|
|[02:55]|如果你感兴趣,记得关注我们下期见...|
---
> [!Tip] 关于作者
> 这里是**小白debug**,聚焦一切可能影响人类历史进程的技术。
>
[^64]: # 又一款国产模型诞生,性价比杀疯了!
## 来源
[原文链接](https://mp.weixin.qq.com/s/aH722v-StnTowd4sI7gNXA)
## 正文
公众号名称:JavaGuide
作者名称:Guide
发布时间:2026-04-02 18:08
我用 AI 编程工具写代码有挺长时间了,一个感受越来越明显:很多日常任务不需要模型深度推理。修个 Bug、写个工具函数、做个小工具——这类任务目标明确,我更在意响应够不够快、连续改需求跟不跟得上。有些模型碰到这类任务也会先分析一通,输出一大段推理过程,有用的就两行。
之前没怎么关注过阶跃星辰的模型,感觉这家一直挺低调的。最近偶然刷到 Step 3.5 Flash 2603,发现它有个 **Low Think Mode**——简单任务少推理,直接给结果。感觉挺有意思的,就拿来用了几天,试了几个场景:
1. **从 0 到 1 做一个公众号排版工具**:我自己日常写公众号一直缺一个好用的排版工具,索性直接做了。
2. **连续 Bug 修复**:拿一个真实项目中的 Bug,连续让模型修 3~5 轮,看它会不会越改越乱。
3. **Low Think Mode 对比**:简单任务下,低思考模式和高思考模式的效率差异到底有多大。
## Claude Code 接入 Step 3.5 Flash
我用的是 Claude Code。Step 3.5 Flash 兼容 OpenAI Chat 和 Anthropic API,接入非常简单。
**第一步**:获取 API Key。到阶跃星辰开放平台创建 API Key。
> 如果你本机没有安装 Claude Code,运行下面这行命令即可(Node.js 18+):
>
> ```
> npm install -g @anthropic-ai/claude-code
> ```
>
**第二步**:编辑 Claude Code 配置文件。
macOS/Linux 编辑 `~/.claude/settings.json`:
```
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.stepfun.com/step_plan",
"ANTHROPIC_AUTH_TOKEN": "你的API Key"
},
"model": "step-3.5-flash-2603"
}
```
**第三步**:启动验证。在终端输入 `claude` 启动,确认模型显示正确即可。
完成配置后,接下来就是几个场景的实际使用情况。
## 场景一:从 0 到 1 做一个公众号排版工具
### 背景
写公众号技术文章,排版一直是个麻烦事。市面上好用的排版工具其实不少,但我一直没找到特别顺手的——我想要一个足够轻量、专门面向程序员的排版工具,代码高亮和一键复制到公众号这些功能得好使。
我就直接用 Step 3.5 Flash 来做了:**能不能快速帮我从 0 到 1 搭出来?**
### 需求描述
我给 Step 3.5 Flash 的需求是这样的:
> 我需要做一个面向程序员的技术文章公众号排版工具。核心功能:
>
>
> 1. 左侧 Markdown 编辑区,右侧实时预览区,预览效果尽量贴近公众号实际渲染效果
> 2. 支持代码块语法高亮(至少覆盖 Java、Python、Go、JavaScript)
> 3. 支持一键复制为公众号兼容的富文本格式
> 4. 预设几套适合技术文章的排版主题(极简黑、护眼绿、科技蓝等)
> 5. 支持表格、引用块、有序/无序列表的正确渲染
> 6. 单页应用,纯前端实现,无需后端
>
### 第一阶段:骨架生成
让我比较惊喜的是,Step 3.5 Flash 没有纠结太久,直接进入了计划模式。然后让我选择一些设计理念,大概不到 2 分钟,项目骨架就已经搭好了——**响应速度确实快**,基本不用干等。
- 项目结构清晰:`index.html`、`styles.css`、`app.js` 三文件分离
- 技术选型合理:使用 `marked.js` 做 Markdown 解析、`highlight.js` 做代码高亮
- 预设了多套主题的 CSS 变量体系


**第一次产出的骨架完整度很高**,不是那种只有 HTML 壳子的半成品——代码高亮、主题切换、复制功能都已经有了基本实现。不过也有一些瑕疵,比如实现的主题是工具 UI 的主题而不是公众号文章内容的排版主题,一键复制到公众号后部分格式也会错乱。
### 第二阶段:多轮迭代
骨架出来后,我开始提改进需求,连续改了 3 轮:
**第 1 轮**:要实现的是公众号文章内容的排版主题,不是工具的 UI 界面主题。
> 要实现的是公众号文章内容的排版主题,不是工具的 UI 界面主题。
>

**第 2 轮**:不同语言的代码格式没有高亮,代码块需要有一个复制代码的按钮。
> 代码块的格式没有高亮,代码框的位置需要复制按钮
>
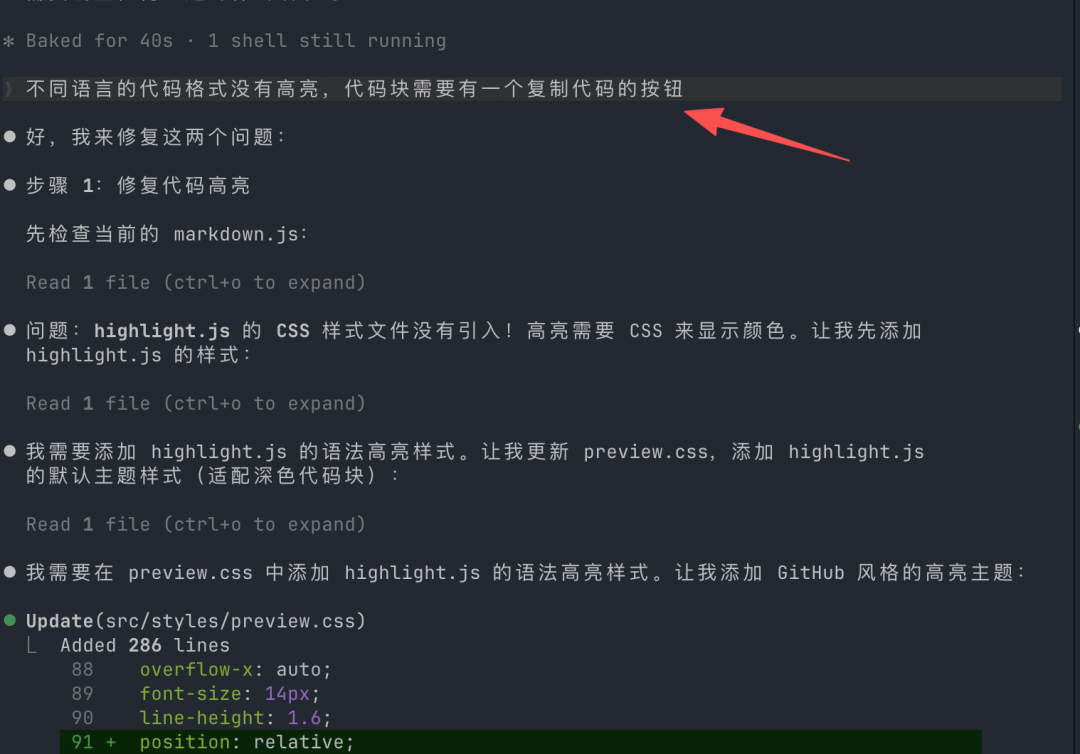
修复代码块样式
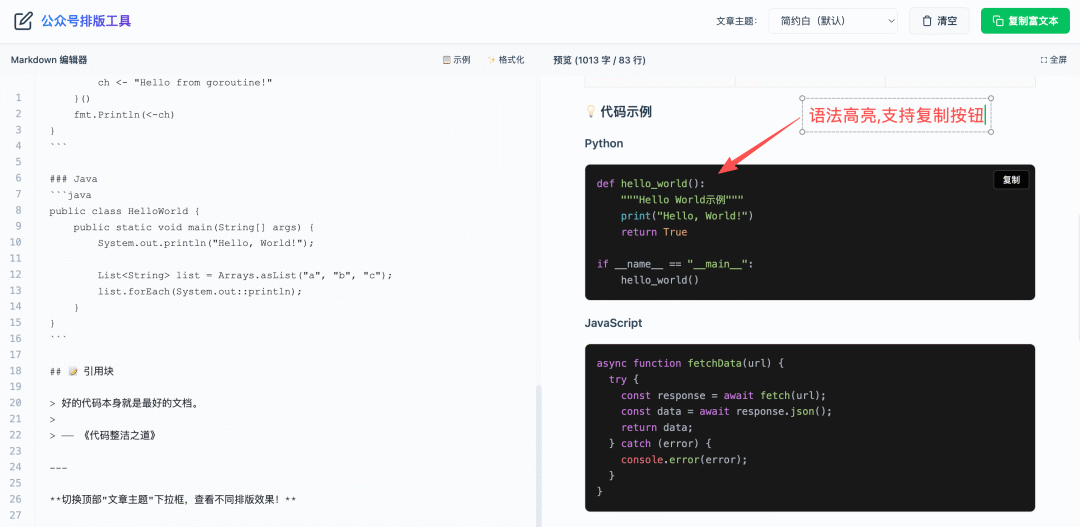
语法高亮复制按钮
**第 3 轮**:导出功能优化,确保一键复制粘贴到公众号编辑器后格式不乱。
> 一键复制功能的实现需要确保:粘贴到公众号编辑器后,代码高亮、表格、引用块的样式都能正确保留。
>

一键复制优化
3 轮迭代下来,Step 3.5 Flash 的表现很稳——**没有出现“越改越乱”的情况**,每一轮修改都落在对应的代码段,改动范围小且准确。
### 第三阶段:最终效果
最终跑起来的排版工具效果如下:
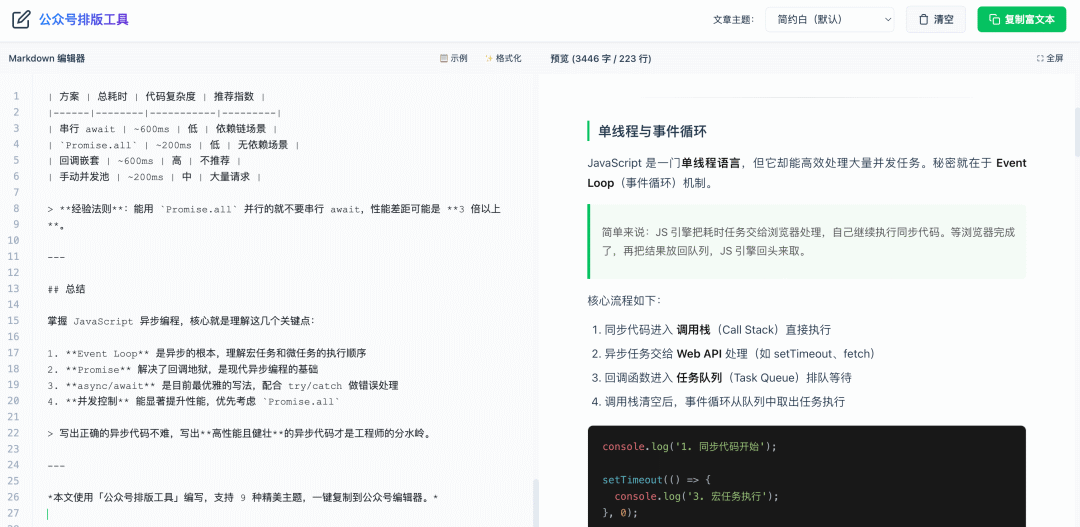
最终排版工具图
最终在公众号图
整个开发过程不到 30 分钟,3 轮迭代全部完成。纯前端小工具能做到这个完成度,效率不错。
## 场景二:连续 Bug 修复
### 背景
Bug 修复是开发中最日常的工作,但真实项目中的 Bug 往往不像”空指针加个判空”那么简单。很多线上 Bug 的特点是:代码能编译、能跑,低并发下完全正常,一上量就出问题。
我从自己的一个 Spring Boot 项目中挑了 3 个这类 Bug(已脱敏),想看看模型能不能定位到根因,而不是只做表面修复。这三个 Bug 分别对应三个不同的知识盲区:Spring AOP 代理机制、Web 容器线程模型、异步编程最佳实践。
### Bug 1:事务失效
**问题**:批量导入用户接口,每个用户插入后会记录一条操作日志。代码里 `saveUserWithLog` 方法明明标了 `@Transactional`,但线上发现:如果导入到第 5 条时失败了,前 4 条用户数据已经插入、没有回滚。
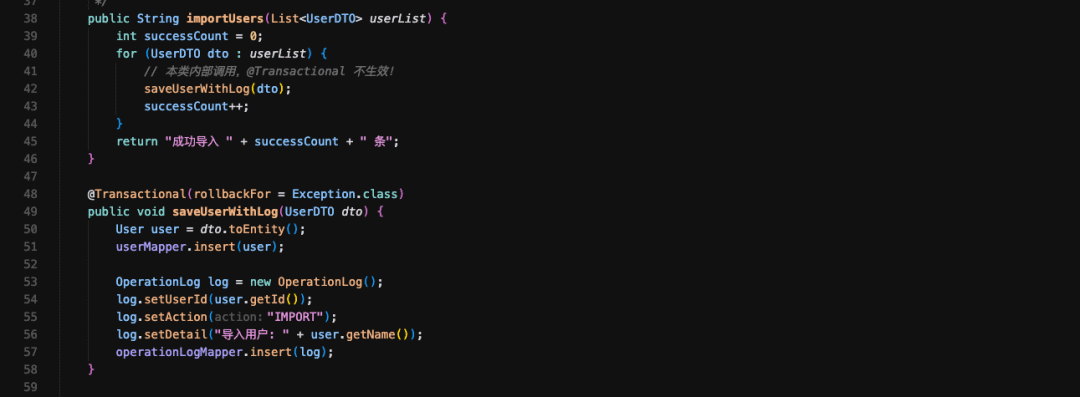
事务不生效截图
我给 Step 3.5 Flash 的指令:
> UserService 的 importUsers 方法中,saveUserWithLog 虽然加了 @Transactional 注解,但实际运行时事务没有生效,批量导入失败时数据不会回滚。请定位原因并修复,确保导入失败时整批数据回滚。
>
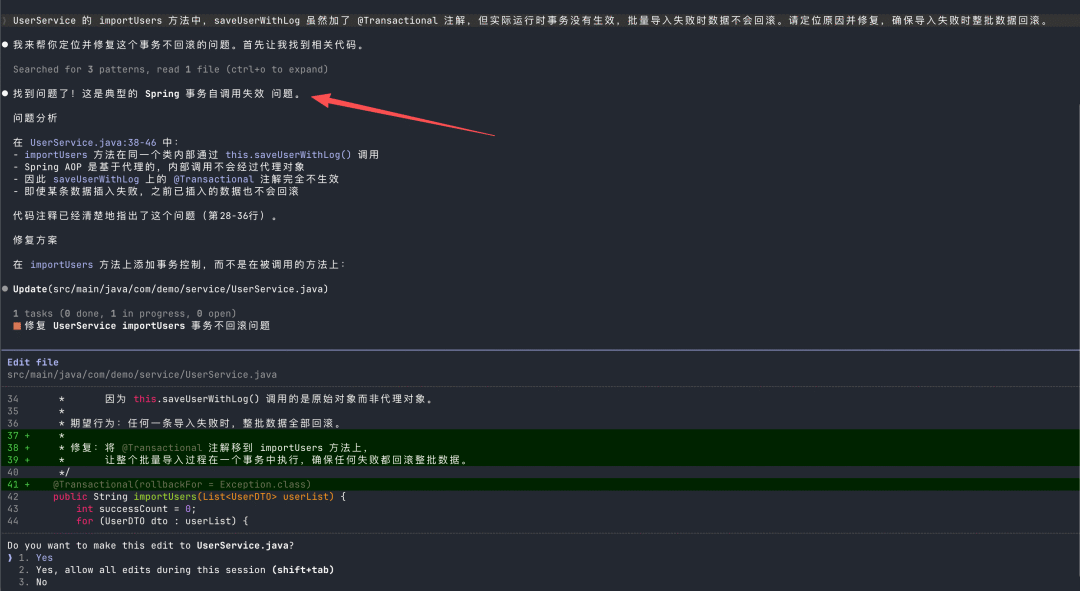
事务失效修复过程
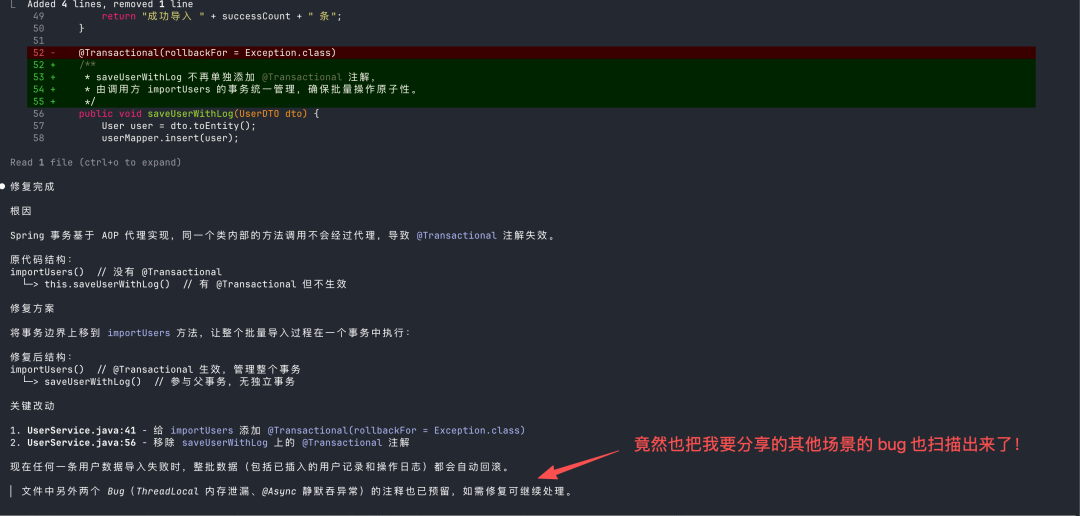
事务修复完成截图
这个 Bug 的关键在于:**Spring AOP 是基于代理的,同一个类内部的方法调用不会走代理**。所以 `this.saveUserWithLog()` 实际上是直接调用原始对象的方法,`@Transactional` 注解根本没被拦截。
这是一个经典的 Spring 陷阱,很多 3 年经验的开发者都会踩坑。如果模型只是简单地说“加个事务注解”,那说明它没理解问题的本质。
### Bug 2:你看到的是别人的数据
**问题**:线上陆续有用户反馈“偶尔能看到别人的信息”。比如用户 A 登录后,个人主页显示的是用户 B 的昵称和头像。**本地测永远复现不了,压测也复现不了,但线上每天都在发生。**
这个 Bug 的根因藏在认证拦截器和 ThreadLocal 的配合里:
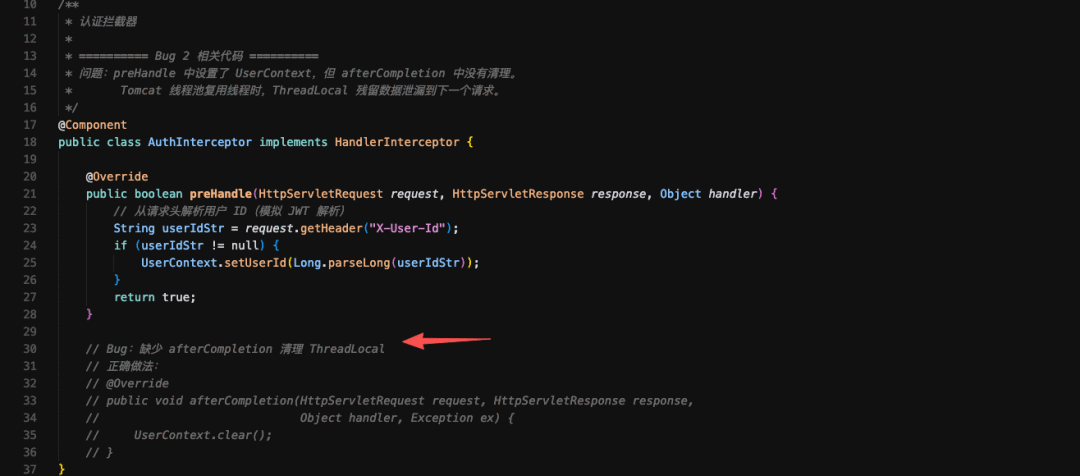
内存泄漏bug

内存泄露bug2
我给 Step 3.5 Flash 的指令:
> 项目中 AuthInterceptor 在 preHandle 中通过 UserContext.setUserId() 设置了当前用户 ID,但没有在 afterCompletion 中清理 ThreadLocal。在 Tomcat 线程池环境下,线程被复用时 ThreadLocal 残留的数据会泄漏到下一个请求,导致用户信息串号。请修复这个问题。
>

内存泄露修复
这个 Bug 挺隐蔽的:Tomcat 的线程池默认核心线程数是 200,线程处理完请求后不会销毁,而是回到池中等待复用。如果线程 A 处理了用户张三的请求,`ThreadLocal` 里存的是张三的 ID;下次线程 A 被分配给用户李四的请求,但李四的请求如果没走到拦截器(比如某些白名单接口),`UserContext.getUserId()` 返回的还是张三的 ID。
**这是一个纯粹因为“Web 容器线程模型”导致的 Bug**,跟代码逻辑本身无关。Tomcat 线程池的线程是复用的,这一点容易被忽略。
### Bug 3:异步任务失败
**问题**:用户注册后应该收到欢迎邮件,但线上大量用户反馈没收到。查日志发现:注册接口返回正常,没有任何错误日志,邮件发送方法像是从来没执行过一样。

用户注册 bug
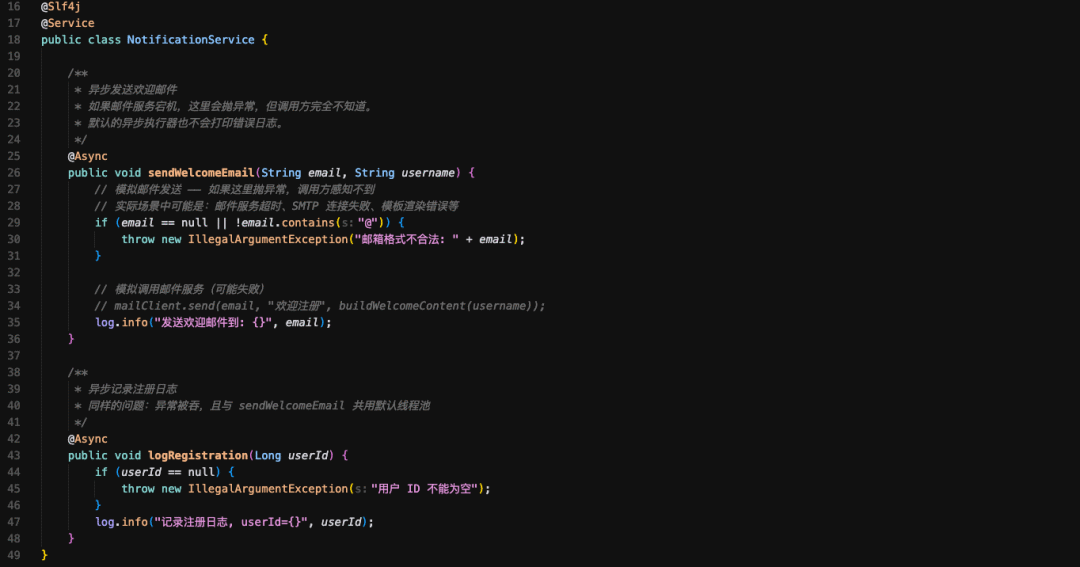
用户注册 bug2
我给 Step 3.5 Flash 的指令:
> UserService 的 register 方法通过 NotificationService 异步发送欢迎邮件,使用了 @Async 注解。但存在两个问题:1) 异步方法内部异常被静默吞掉,调用方和日志都无法感知失败;2) 没有配置自定义线程池,使用默认的 SimpleAsyncTaskExecutor 会无限制创建线程,高并发下可能 OOM。请修复这两个问题。
>

异步线程 bug3
这个 Bug 其实是**两个问题叠加**:第一层是异常被吞——Spring `@Async` 方法抛出的异常不会传播到调用方,默认连日志都不打,像一个“黑洞”一样把错误信息吸收了。第二层是线程池问题——默认的 `SimpleAsyncTaskExecutor` 每次都创建新线程,没有上限也没有复用,高并发下线程数爆炸导致 OOM。
如果模型只修了异常处理(比如加 try-catch 打日志),没发现线程池的问题,说明它对 `@Async` 的理解还不够全面。
### 连续修复的稳定性与深度
3 个 Bug 连着修下来,我关注的不仅是“能不能修好”,更关注“**修得对不对、深不深**”:
|维度|评价|
| ------| ------------------------------------------------|
|**根因定位能力**|能否识别出“自调用导致代理失效”这类深层原因|
|**修复深度**|是表面加个注解,还是真正理解原理后给出正确修复|
|**多轮稳定性**|连续修 3 个 Bug,会不会越改越乱|
|**会不会越改越乱**|每轮改动范围是否可控,不会牵扯无关代码|
另外,这 3 个 Bug 分别考察三个不同维度的能力——Bug 1 考察 **Spring AOP 代理机制**的理解深度,Bug 2 考察对 **Web 容器线程模型**的认知,Bug 3 考察**异步编程最佳实践**的掌握。如果模型只做表面修复(比如 Bug 1 只把注解挪到外层方法,Bug 2 只加了 remove 但没考虑拦截器兜底,Bug 3 只加 try-catch 但没管线程池),说明它对问题的理解还停留在表面。
## 场景三:Low Think Mode 处理简单任务
Step 3.5 Flash 最独特的新特性是 **Low Think Mode**。通过设置 `reasoning_effort` 参数为 `low`,模型会在简单任务上减少推理深度,直接给出结果。
我用同一个简单任务做了对比测试——把一段杂乱的 JSON 数据整理成结构化的表格:
> 将以下 JSON 数据整理为 Markdown 表格,按 update\_time 降序排列: {一段包含 20 条记录的 JSON 数据}
>
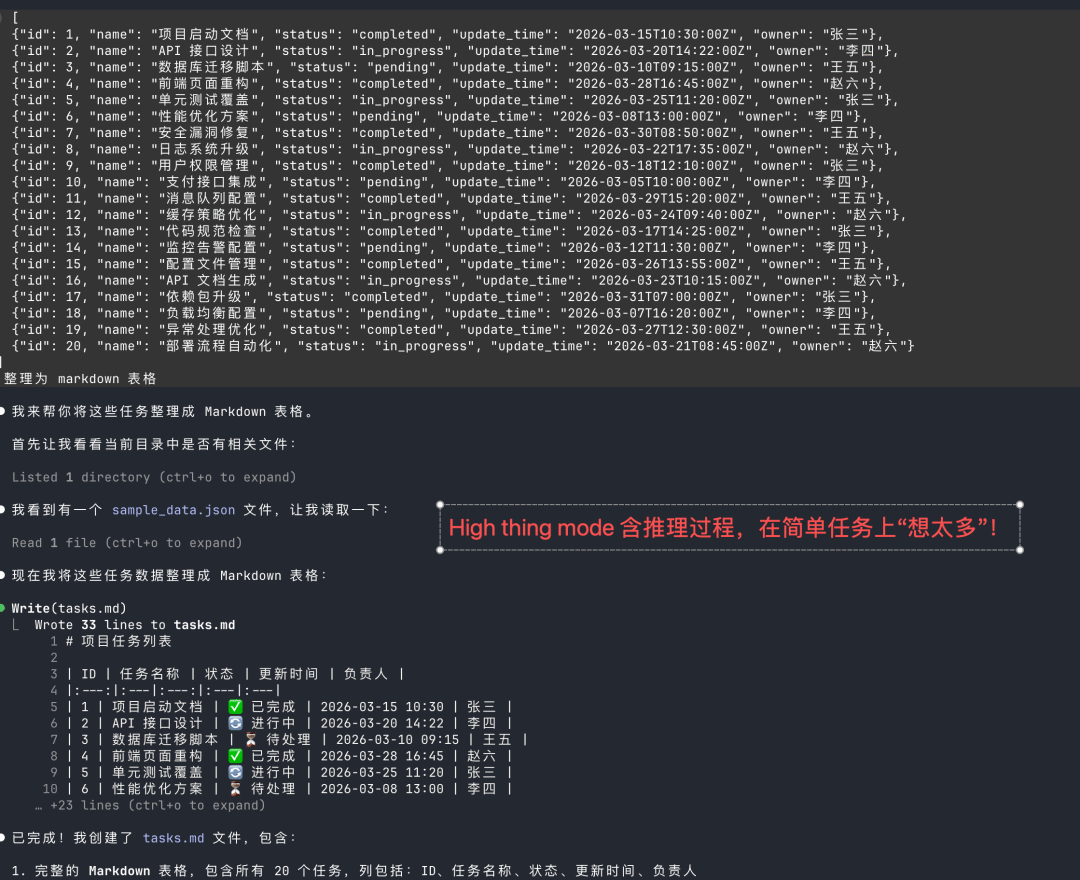
高思考
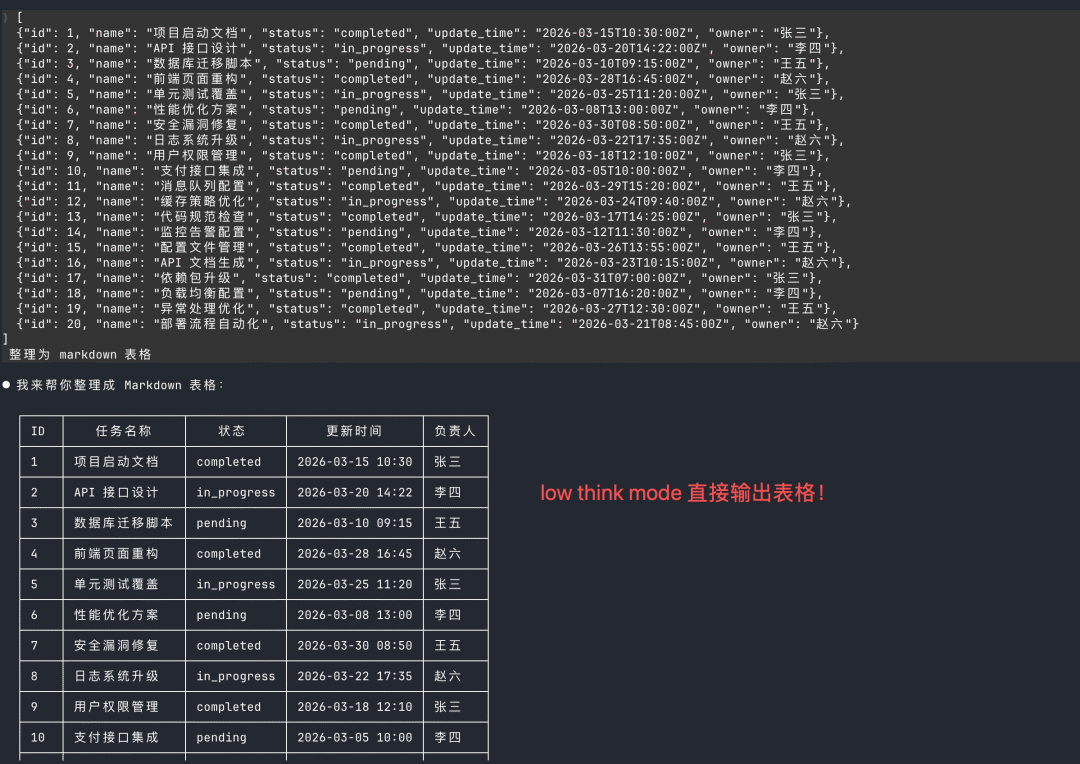
lowthink
**对比结果**:
|维度|High Think Mode|Low Think Mode|
| ------------| ------------------------| ----------------------|
|响应速度|相对较慢,有推理过程|**快很多,直接出结果**|
|Token 消耗|较高|**显著降低**|
|输出质量|表格正确|表格正确,质量无差异|
|体感|在简单任务上“想太多”|**干脆利落**|
**我的判断**:Low Think Mode 的价值不是“降低能力”,而是**避免在简单任务上浪费资源**。像数据整理、格式转换、简单 Bug 修复这类任务,根本不需要深度推理——Low Think Mode 在这种场景下确实划算。
如果你每天有大量这类“简单但必须做”的任务,Low Think Mode 值得作为默认模式。
## 核心优势
几个场景用下来,我觉得最值得说的就三点:
**1.** **高频场景下“用起来很省”**
不管是生成代码还是修复 Bug,Step 3.5 Flash 的输出都很克制——不会过度发挥,不会在简单问题上长篇大论。而且响应速度很快,基本没有等待感,高频使用时,这种不过度发挥的风格反而更舒服。
**2.** **Low Think Mode 挺实用**
简单任务切到 Low Think Mode 后,响应速度和 Token 消耗的改善是肉眼可见的。不是可有可无的装饰,日常用起来体感差别很大。
**3.** **连续交互的稳定性**
无论是 4 轮迭代改需求,还是连续修 3 个 Bug,Step 3.5 Flash 都没有出现“越改越乱”的情况。连续交互不出问题,比单次表现好重要得多。
## 总结
|维度|评价|
| ------| --------------------------------------------------|
|**最适合**|高频编程任务、Bug 修复、代码重构、小项目快速原型|
|**最顺手**|结构明确、规则清晰的场景|
|**不适合**|需要深度架构推理、复杂系统设计的场景|
|**Low Think Mode**|简单任务必开,性价比极高|
|**会不会继续用**|日常高频任务会作为默认工作模型|
说直白点,Step 3.5 Flash 不是什么都能干的最强模型,但日常用起来确实很顺手。旗舰模型像特种兵,能力强但调用成本高;日常大部分编程任务,Step 3.5 Flash 搞定就够了,快且省 Token。少数特别复杂的任务,再找特种兵不迟。

**⭐️推荐阅读**:
- [《SpringAI 智能面试平台+RAG 知识库》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247552320&idx=1&sn=a7e4e5a8d957446e6bb032d78b2fa5fb&scene=21#wechat_redirect)
- [万字拆解 LLM 运行机制:Token、上下文与采样参数](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247553608&idx=1&sn=c87156405d51922bf7214ceaff6848a8&scene=21#wechat_redirect)
- [一文搞懂 AI Agent 核心概念:Agent Loop、Context Engineering、Tools 注册](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247552979&idx=1&sn=d13c59f631a26d3e4ba35fe5d2fe06ff&scene=21#wechat_redirect)
- [万字详解 Agent 核心方式: ReAct、Reflection、A2A、Agentic Workflows](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247553026&idx=1&sn=158a1c17cc7ac0dabc39327764ac312f&scene=21#wechat_redirect)
- [万字详解 RAG 向量索引算法和向量数据库](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247553552&idx=1&sn=389d583388474c52cec7769f4b920459&scene=21#wechat_redirect)
- [JDK 26 正式发布,人已麻。。。](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247553463&idx=1&sn=6b988a85df41c7c84c0b405bd54305b0&scene=21#wechat_redirect)
---
## 又一款国产模型诞生,性价比杀疯了!
原创 Guide JavaGuide[^65]: # 老板突然说:“咱们的项目,不是给人类用的!” 我立刻写了离职信:“招我进来给 AI 打工?”
## 来源
[原文链接](https://mp.weixin.qq.com/s/BcZlsnDGGfO8hRe-YKPohQ)
## 正文
公众号名称:程序员鱼皮
作者名称:程序员鱼皮
发布时间:2026-04-03 15:58
原文链接:[https://www.codefather.cn](https://www.codefather.cn)
大家好,我是程序员鱼皮。
设想一下,你刚进一家公司,老板突然跟你说:“咱们的项目,不是给人类用的!”
你内心是什么感受?
“老板失了智?”、“公司之后咋赚钱啊?”、“老板竟然不把用户当人?”
但其实,这件事情在如今,倒是挺正常的……
最近,我发现 GitHub 上有一批很特别的开源项目,**它们的目标用户不是人类,而是 AI**。
这些项目天生就是为 AI 服务的,帮 AI 看网页、读文件、操作浏览器,让 AI 从一个只会聊天的嘴强王者,变成真正能干活的六边形战士。
今天就来盘点一下 **AI 最喜欢的 15 个开源项目**,建议收藏,给你的 AI 接上这些项目后,堪比开挂!
## 1、AI 的眼睛 - 看懂互联网
AI 虽然知识渊博,但最大的短板就是获取不到最新的网页内容。
比如你想让 AI 帮你总结某个网站的内容、或者学习某个开源项目的文档,一个没有联网能力的 AI 大模型要么直接告诉你它访问不了,要么给你一堆过时的信息。
Firecrawl 就是来解决这个问题的。它可以搜索网页、抓取单个页面或者爬取整站内容,把网页转成干净的 Markdown 或 JSON,还自带 JavaScript 渲染和反爬处理。
而且它提供了官方 MCP Server 和 Agent Skills 技能包,Cursor、Claude Code 这些 AI 编程工具可以接入使用。之后开发项目的时候,直接让 AI 参考某个技术文档、分析竞品页面,AI 就会自动调用 Firecrawl 去抓取网页内容,给出更靠谱的回答。
> 开源指路:https://github.com/firecrawl/firecrawl
>
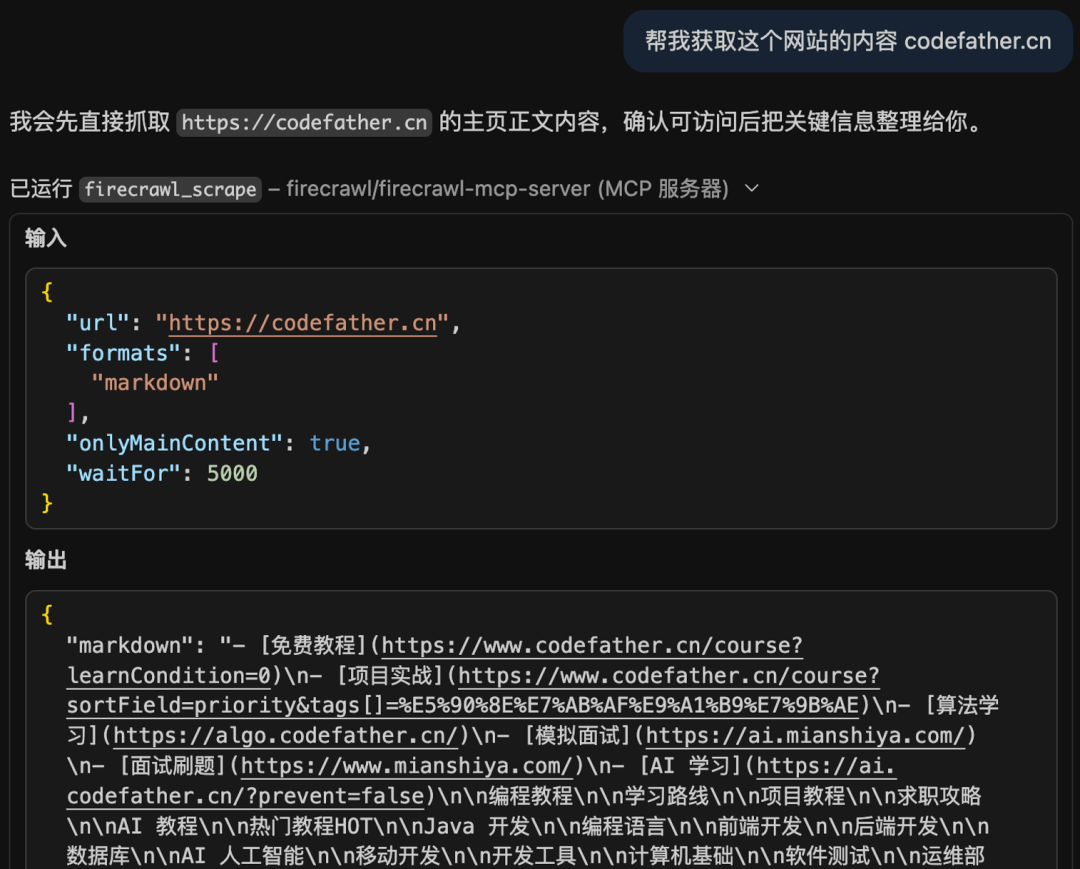
类似的开源项目还有 Crawl4AI,定位是对大模型友好的爬虫工具。它的功能和 Firecrawl 类似,也内置了 MCP Server 和 Agent Skills 技能包,可以直接在 AI 编程工具中使用。
> 开源指路:https://github.com/unclecode/crawl4ai
>
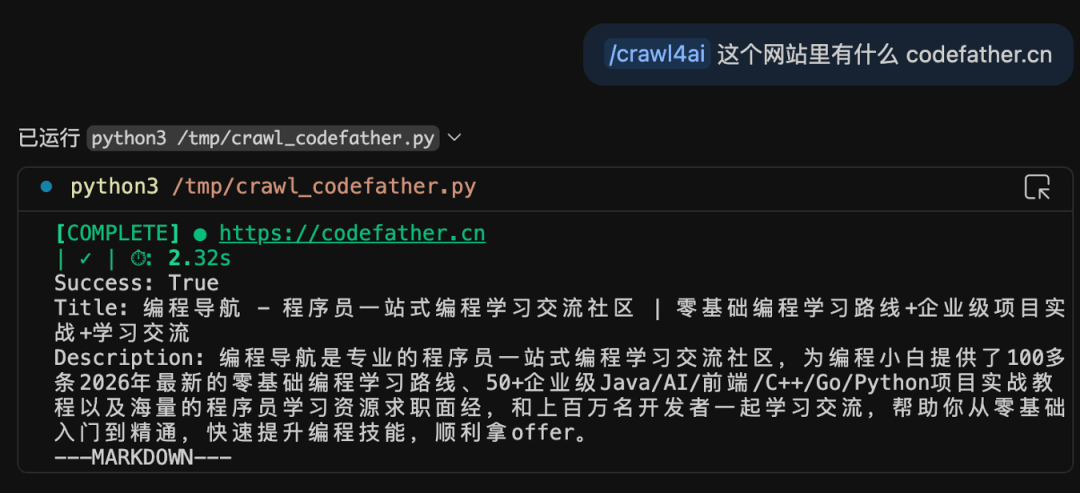
## 2、AI 的手脚 - 操控浏览器
有时候你不光想让 AI 看网页,还想让它直接动手操作。比如帮你自动填一个表单、批量点赞收藏、或者在后台系统里做一些重复性的操作,解放双手。
Browser Use 是一个基于 Python 的浏览器自动化框架,让 AI 能像真人一样操控浏览器。
比如我跟 AI 说:帮我打开鱼皮的编程导航网站,找到 Java 学习路线并截图。
它就能一步步完成,支持点击、输入、滚动等各种操作。甚至还支持多标签页操作和自动规划执行步骤,复杂的多步任务也能搞定。
> 开源指路:https://github.com/browser-use/browser-use
>
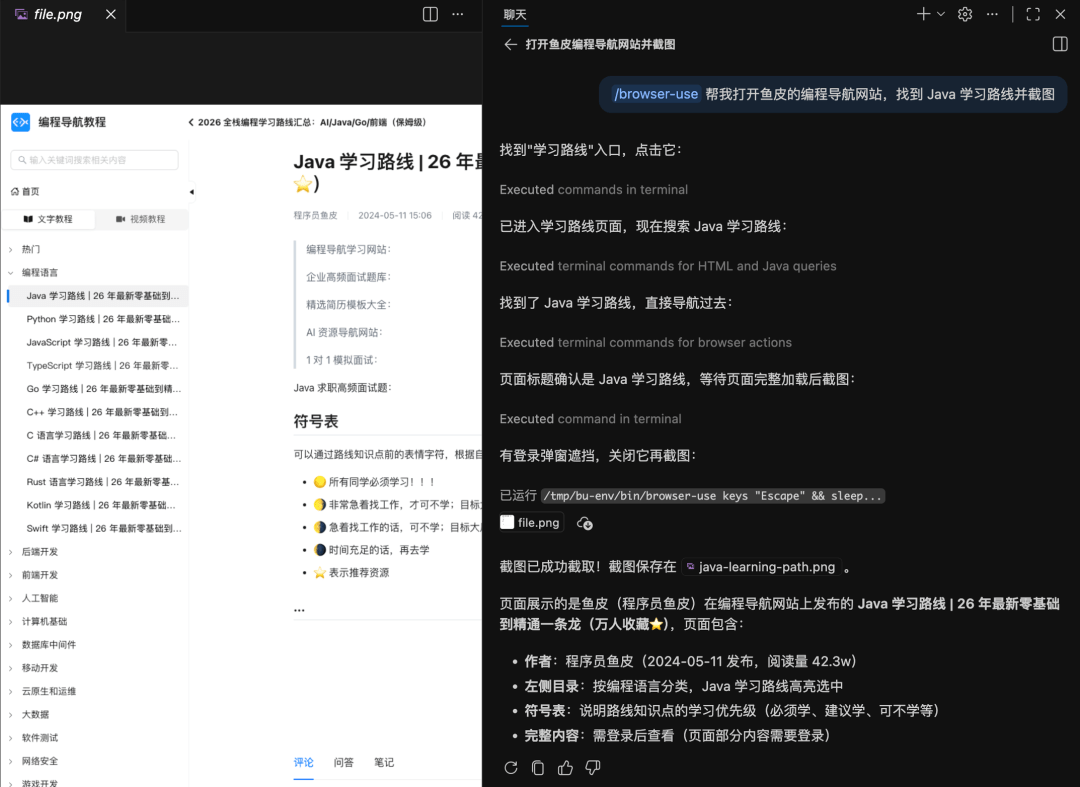
Browser Use 的底层基于微软开源的 Playwright 浏览器自动化框架。Playwright 虽然不是专门给 AI 设计的,但它已经成了 AI 操控浏览器的事实标准,几乎所有 AI 浏览器自动化项目都绕不开它。
> 开源指路:https://github.com/microsoft/playwright
>
## 3、AI 的遥控器 - 把一切变成命令行
AI 天然擅长跟命令行打交道,对它来说,敲命令比点鼠标方便很多倍。
但问题是,很多网站和工具压根没有提供命令行接口……
于是,一个牛呗的开源项目 OpenCLI 出现了,它能把 **任意网站、Electron 应用、甚至本地工具** 统统变成命令行接口!
比如你想让 AI 帮你查科技热点、B 站热门、知乎热榜等。装上 OpenCLI 的浏览器插件和命令行工具后,输入一行命令就搞定了。而且它会复用浏览器里已有的登录状态,不需要把密码交给第三方。
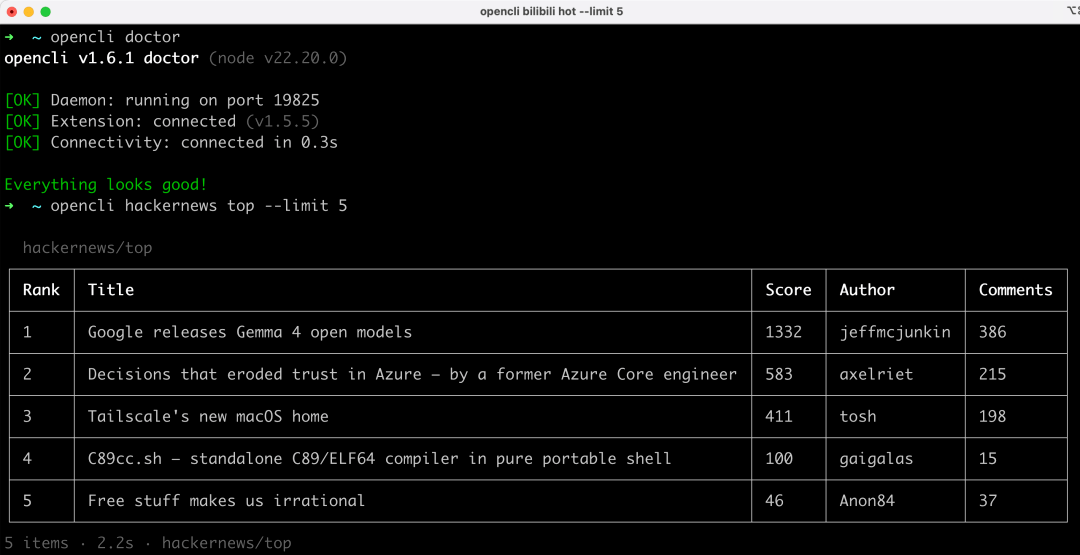
它内置了几十个适配器,覆盖了 B 站、知乎、Twitter、Reddit 等一大堆平台。接入之后,AI 就可以直接通过命令行从这些网站获取数据,不需要你手动复制粘贴了,就像给 AI 装了一个万能遥控器。
> 开源指路:https://github.com/jackwener/opencli
>
## 4、AI 的阅读器 - 读懂各种文件
日常工作中,很多资料都是 PDF、Word、Excel、PPT 格式的。
但 AI 默认只能读纯文本,你直接把一个 PDF 文件丢给它,大概率读不出什么有用的东西。
解决方法很简单,AI 最喜欢 Markdown 了,那不妨把文件先转成 Markdown,再交给它处理就好了。
MarkItDown 是微软开源的万能格式转换器,PDF、Word、Excel、PPT、图片、音频、HTML、甚至 YouTube 视频,它都能一把梭转成 Markdown。
> 开源指路:https://github.com/microsoft/markitdown
>
本质上就是个 Python 脚本,安装上之后输入一行命令就能用:

它还提供了 MCP Server,可以直接接入到 AI 编程工具中。之后你在项目里丢一个 PDF 或 Word 文件让 AI 分析,它就会自动调用 MarkItDown 先转成 Markdown 再处理。
MarkItDown 的优点在于格式覆盖广,几乎啥格式都能转,但遇到排版很复杂的 PDF 就有点力不从心了。
如果你需要处理论文里的多栏排版、数学公式、复杂表格这类内容,可以再看看 MinerU 和 Docling。
MinerU 专攻 PDF 深度解析,能把公式转成 LaTeX、表格转成 HTML,还能自动提取图片,最终输出的是包含图文的多模态 Markdown。
> 开源指路:https://github.com/opendatalab/MinerU
>
Docling 是 IBM 开源的文档解析工具,除了 PDF 之外还支持 Word、PPT、Excel、图片,甚至装上语音识别扩展后还能处理音视频(提取音轨转文字),在复杂文档的版面理解和结构还原上比 MarkItDown 更强。
> 开源指路:https://github.com/docling-project/docling
>

## 5、AI 的耳朵 - 听懂语音
如果你想让 AI 帮你整理一段会议录音、或者给一个播客视频生成文字稿,它首先要能把语音转成文字。
whisper.cpp 是 OpenAI Whisper 模型的 C/C++ 移植版,最大的优势就是纯本地运行,CPU 也能跑,不需要 GPU 也不需要联网。
它可以作为 AI 的耳朵,转录会议录音、播客、视频字幕都不在话下,也完全不用担心隐私数据外泄。它支持多种语言的语音识别,还能自动检测语种,丢进去一段音频就能出文字。
> 开源指路:https://github.com/ggml-org/whisper.cpp
>
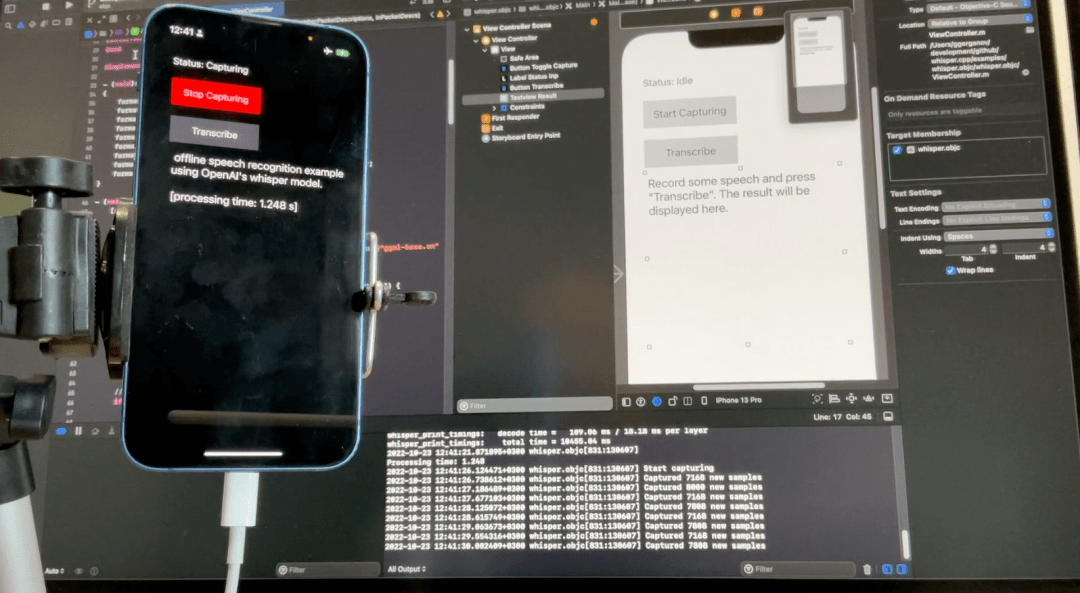
## 6、AI 的下载器 - 获取素材
不管是让 AI 帮你总结视频、提取音频还是生成字幕,第一步都得先把原始视频素材下载到本地。
无奈很多平台的视频是不支持直接下载的……
于是有个天才开源了 yt-dlp 这个神级视频下载工具,支持 **上千个** 网站,包括 YouTube、B 站、TikTok、Twitter 等等,你能想到的基本都有!
> 开源指路:https://github.com/yt-dlp/yt-dlp
>

它是纯命令行工具,AI 调用起来非常丝滑,指定一个 URL 和输出格式就完事了。还能选择分辨率、提取纯音频、下载字幕,功能非常全面。
之前我直播带大家开发的 [AI 万能视频下载总结器](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247584682&idx=1&sn=dba3a27d7abd07d744a6b29e4e6f7ca8&scene=21#wechat_redirect) 项目,就是基于 yt-dlp 二次开发的,感兴趣的同学可以看看。

## 7、AI 的剪辑师 - 处理音视频
如果你想让 AI 帮你剪辑视频、转码音频、合成素材,光下载还不够,还得有一个处理音视频的工具。
人工做这些活儿要开各种软件,但 AI 只需要一个命令行工具就够了。
这个工具就是 FFmpeg,可能是整个计算机历史上最重要的开源项目之一,几乎所有涉及音视频的软件底层都在用它。
不管是转码、裁剪、拼接、加字幕、提取音频还是转换格式,使用 FFmpeg 一条命令就能搞定。
> 开源指路:https://github.com/FFmpeg/FFmpeg
>
虽然它的参数多到让人类头皮发麻,但 AI 记参数可太擅长了!
比如你跟 AI 说:把这个视频裁剪前 30 秒并转成 GIF。
它立刻就能生成对应的 FFmpeg 命令并执行,效果很完美:
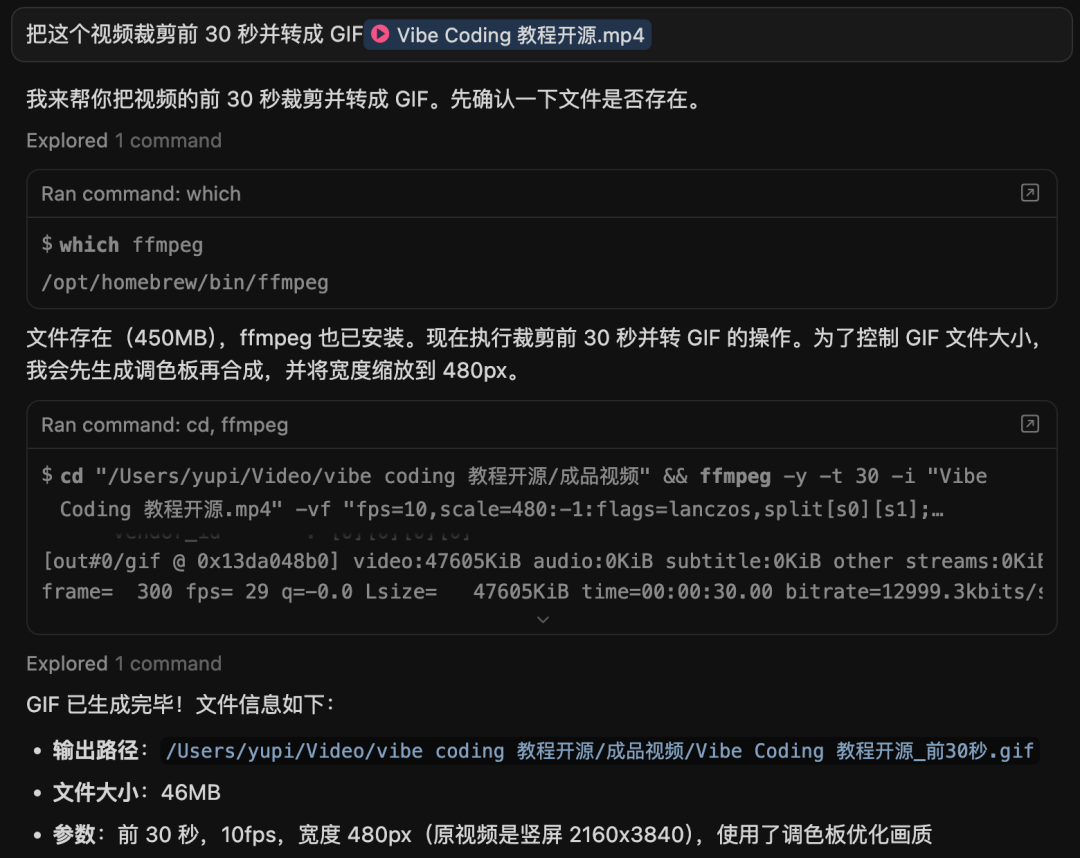
换成人工操作,可能还得先去搜半天参数……
现在组合 AI + FFmpeg,直接王炸!哪还需要到网上找什么视频格式转换工具?
## 8、AI 的百宝箱 - 调用外部服务
现在越来越多人想用 AI 来提升日常工作效率,比如让 AI 帮你发邮件、创建 GitHub Issue、更新 Notion 文档、给聊天软件发消息。
但这些事情每个都要对接不同的平台和 API,认证方式也各不相同,一个个对接起来很麻烦。
Composio 就是帮 AI 搞定这些脏活累活的。它预先集成了 1000+ 外部服务,帮你处理好 OAuth 认证、API 调用、错误重试这些细节。
> 开源指路:https://github.com/ComposioHQ/composio
>
AI 只需要调一个函数就能操作 GitHub、Gmail、Slack、Notion 等各种平台,省去了逐个对接的痛苦。不管你用 Python 还是 TypeScript 开发 AI 应用,都能直接用上。
官方还提供了不少现成的应用模板,比如能自动跨平台操作的 AI 助手 TrustClaw、连接 HubSpot 和 Google Sheets 做数据分析的 Data Analyst Agent 等。
## 9、AI 的备忘录 - 让它记住你是谁
用过 AI 编程的同学应该都有过这种体验:跟 AI 聊了好几轮的需求和技术细节,结果一开新对话,它全忘了,又得从头介绍一遍。
这是因为 AI 本身是 **没有记忆** 的,每次对话结束上下文就清空了。
虽然现在不少 AI 编程工具已经自带了记忆管理功能,但如果你想自己开发 AI 应用,记忆这块儿就得自己解决。
可以用开源项目 Mem0 给 AI 装上一个持久记忆层。它会自动从对话中提取关键信息存到数据库里,下次对话时自动检索出来。
> 开源指路:https://github.com/mem0ai/mem0
>
这样一来,AI 能记住你喜欢用什么编程语言、你的项目用了什么技术栈、上次聊到哪了,下次对话直接接着来,不用重复交代背景了。
而且它支持用户级、会话级、Agent 级三层记忆管理,不同用户的上下文不会互相混淆。

如果你在学 AI 应用开发,建议研究一下 Mem0 的记忆系统实现,从信息提取、冲突消解到向量检索,这套设计很有参考价值。
## 10、AI 的技能包 - Agent Skills
前面的项目都是给 AI 提供某种 “能力”,比如看网页、读文件、操作浏览器。
而 Agent Skills 解决的是另一个问题,直接给 AI **提供专业知识和做事方法**。
anthropics/skills 是 Anthropic 官方开源的技能仓库,里面装的不是代码,而是一份份给 AI 准备的技能包。每个 Skill 就是一个文件夹,里面写着详细的指令,教 AI 怎么完成特定的任务,比如怎么做 PPT、怎么写技术文档、怎么做代码审查。
> 开源指路:https://github.com/anthropics/skills
>
Agent Skills 已经成了跨工具的开放标准,Cursor、Claude Code、Codex 等 40 多个 AI 编程工具都支持,安装一次到处能用。
如果你想快速安装技能,可以用 vercel-labs/skills 这个开源的技能安装器。输入一行 `npx skills add` 命令就能搞定,还支持搜索、更新和卸载技能。
> 开源指路:https://github.com/vercel-labs/skills
>
## 最后哔哔
看完这些项目,你会发现开源世界正在悄悄发生一个变化。
以前大家做开源,目标用户都是人类开发者;但现在越来越多的项目,从设计之初就是给 AI 用的。比如输出 Markdown 方便 AI 阅读、提供命令行方便 AI 调用、暴露 MCP Server 方便 AI 编程工具接入,甚至直接给 AI 准备技能包教它做事。
以后做开源,可能不光要考虑「人类用户体验好不好」,还得想想「AI 调用起来方不方便」。
这些项目是免费开源的,而且可以本地部署,如果你正在使用 AI 编程,不妨挑几个试试,说不定会打开新世界的大门。
我是鱼皮,持续关注和分享 AI 编程教程和资源,带你探索更多提高效率的玩法。觉得有用的话,记得点赞收藏和关注,也欢迎在评论区分享更多实用的开源项目~
往期推荐
[时隔六年,曝光一下鱼皮的最新简历!](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247584891&idx=1&sn=21695514ae6725ba10a00238bf2aea7a&scene=21#wechat_redirect)
[我的免费 Vibe Coding 零基础教程,爆了!](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247580489&idx=1&sn=ea128f6a8c5d79e641133615f85f7ab8&scene=21#wechat_redirect)
[春招最能打的 AI 项目!SSP Offer 拿下](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247584719&idx=2&sn=8873b3c1159f4c94a11dddc8ca338a5f&scene=21#wechat_redirect)
[面试官都开始用这个网站出题了。。](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247584622&idx=2&sn=ae53c653e7995485f3f9443a19f95f36&scene=21#wechat_redirect)
[我的 AI 网站,突然起飞了!](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247584598&idx=1&sn=a25049b030f6025927aca382f0c4f45e&scene=21#wechat_redirect)
[我被面试候选人压力了。。。](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247583063&idx=2&sn=5b8992fa4c5cd6daad07ea614426a626&scene=21#wechat_redirect)
[我去年最骄傲的事,突破 2w!](https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247582331&idx=1&sn=71be504d38b45de2890f30302eeaff25&scene=21#wechat_redirect)
---

原创 程序员鱼皮 程序员鱼皮
阅读原文[^66]: # Node.js EACCES error when listening on most ports
## 来源
[原文链接](https://stackoverflow.com/questions/9164915/node-js-eacces-error-when-listening-on-most-ports)
## 正文
So the possible reason for this would be related to typo in environment variables names or else not installed dotenv package .
So if there is any other error apart from typo and dotenv npm package ,then you must try these solutions which are given below:
**First solution** for Windows only
Open cmd as run as administrator and then write two commands
1. net stop winnat
2. net start winnat
hope this may solve the problem ...
**Second solution** for windows only
make sure to see that in your environment variable that there is no semicolon(;) at the end of the variable and there is no colon (:) after the variable name.
for example I was working on my project in which my env variables were not working so the structure for my .env file was like
PORT:5000; CONNECTION\_URL:MongoDbString.<password>/<dbname>;
so it was giving me this error
Error: listen EACCES: permission denied 5000;
at Server.setupListenHandle \[as \_listen2\] (node:net:1313:21)
at listenInCluster (node:net:1378:12)
at Server.listen (node:net:1476:5)
at Function.listen (E:\\MERN REACT\\mern\_memories\\server\\node\_modules\\express\\lib\\application.js:618:24)
at file:///E:/MERN%20REACT/mern\_memories/server/index.js:29:9
at processTicksAndRejections (node:internal/process/task\_queues:96:5)
Emitted 'error' event on Server instance at: at emitErrorNT (node:net:1357:8) at processTicksAndRejections (node:internal/process/task\_queues:83:21) { code: 'EACCES', errno: -4092, syscall: 'listen', address: '5000;', port: -1 } \[nodemon\] app crashed - waiting for file changes before starting...
So i did some changes in my env file this time i removed the colon(:) and replaced it with equal(=) and removed semi colon at the end so my .env file was looking like this
PORT = 5000
CONNECTION\_URL = MongoDbString.<password>/<dbname>
After changing these thing my server was running on the port 5000 without any warning and issues
Hope this may works...
#code #developers #mernstack #nodejs #react #windows #hostservicenetwork #http #permission-denied #EACCES:-4092[^67]: # Claude 4小时血洗全球最安全系统,人类最后防线失守-36氪
## 来源
[原文链接](https://www.36kr.com/p/3754727404389121)
## 正文
**【新智元导读】全球最安全系统,被AI攻破了!Claude 4小时攻破了全球最安全OS内核,从零写出国家级攻击程序,彻底跨越卢比孔河。人类防御60天,AI只要4小时,所有旧秩序,都在加速崩盘。**
全球最安全OS内核,4小时就被AI彻底攻破了!
这一次,Claude在没有任何人类干预的情况下,就自主完成了一套教科书级别的、足以瘫痪全球顶级服务器的全自动攻击链。
它从零构建了两个完整可用的漏洞利用程序,能够在未打补丁的服务器上,直接获取超级用户权限(root shell)。
世界上最安全的操作系统之一,就这样被AI自主攻破了。
这是一个阈值时刻,这是一个分水岭。
这是首份确凿证据,AI能够自主生成过去只有国家级项目才能实现的进攻性能力。整个软件安全领域都地震了。
它从辅助人类安全研究者的工具,变成能执行复杂进攻的自主行动中。
从此,AI彻底跨越卢比孔河!

可怕的是,这种完全自主的智能体,完全可能引发一场新的闪电战,一场网络上的超级战争。
目前的安全法规,只是为应对人类安全速度制定的,它们完全不足以应对AI的威胁!

## **猎杀时刻:当AI跨越卢比孔河**
公元前49年,凯撒率军渡过这条卢比孔河,意味着破釜沉舟、退路已断,历史不可逆转地拐了一个弯。

跨越卢比孔河,从此没有回头路
最近,FreeBSD官方发布了一份看似平淡的安全公告(CVE-2026-4747),指出了一个内核远程代码执行漏洞。
但在致谢栏里,出现了一个让所有人脊背发凉的名字: **「Nicholas Carlini使用Claude发现。」**
这行简短的文字背后,隐藏着一个极其恐怖的事实:AI已经进化成能在安全领域独立刺杀的特种兵。

从此,网络安全已从「人类智力博弈」,被降维成「token消耗战」。

## **FreeBSD被攻破,为何如此令人震惊**
要知道,这件事之所以可怕,就是因为FreeBSD不是普通的消费级软件。它不是Windows,不是macOS,而是支撑世界数字基础设施的脊梁。
Netflix的内容分发网络,PlayStation的操作系统,WhatsApp的基础设施,甚至无数核心路由器、存储设备、防火墙都建立在FreeBSD之上。
几十年来,FreeBSD之所以被信任,是因为它的代码库极其成熟、经过了无数顶级安全工程师的审计和加固。
此前,它一直被视为「坚如磐石」。
然而,就是这样一个被反复锤炼的系统,被一个AI仅用了4小时就攻破了。
仅仅凭借一份漏洞报告,AI就构建了一条完整的攻击链,劫持了内核线程,在多个网络数据包中写入shellcode,并在用户空间生成了一个root shell。

这可不是小bug。这块连人类专家都难啃的硬骨头,被Claude三下五除二就解决了。
4小时里,AI展现出令人战栗的逻辑推理能力。它独立解决了六个世界级的技术难题:
1. 环境配置:自己搭建了一个易受攻击的测试环境。
2\. 多包策略:设计了复杂的数据包方案,绕过单包容量限制。
3\. 内核线程劫持:像外科手术般精准地接管内核。
4\. 无损攻击:它能干净地终止被劫持的线程,让服务器在被攻击后还能正常运行,避免因为系统崩溃而被管理员发现。
5\. 空间跃迁:从深层的内核上下文创建进程,并成功跳转到用户空间。
6\. 权限获取:直接拿到了最高的Root权限。
**更讽刺的是,AI 甚至还顺手写了两个不同版本的漏洞利用程序。**
这两个漏洞利用程序,一个是通过4444端口直连的反向Shell,另一个是把公钥写入authorized\_keys文件。
第一次运行就直接拿到了uid=0(root)——最高权限。
也就是说,Claude就用一个公开CVE公告,4小时独立写出完整FreeBSD内核远程攻击链。
## **国家级战力,现在只需几百美金**
在网络安全安的世界里,开发出一个内核级零日漏洞,只有美国NSA或顶级黑客团队才能完成的「艺术活」。
这些程序是稀缺、昂贵的战略资产,往往需要数名顶尖专家数周甚至数月的打磨,成本高达数百万美元。
但现在,AI把这一切「工业化」了。
一个独立研究员,配合一个前沿大模型,4小时,几百美金的算力费,就搞定了以前「国家队」才能实现的进攻能力。
FreeBSD的这一课,是给全球所有科技巨头、云服务商和安全负责人的最后通牒。
除了部署能够实时监控并拦截AI自动化攻击的智能系统,还得将补丁部署的时间从月缩短到小时。
再也不能以人类速度苟延残喘!
## **AI黑客崛起**
## **网络进攻能力每5.7个月翻倍**
不仅如此,最近10位真实安全专家,花149小时,7个开源基准和一个新的专家人类时间研究,测了291个任务,从28秒小命令到36小时复杂CVE利用。
完整数据:https://github.com/lyptus-research/cyber-task-horizons-data
Lyptus把每个任务先标上「一个熟练人类专家通常要花多久完成」,再看模型在不同难度上的成功率;
当成功率穿过50%时,对应的人类耗时,就是AI的P50时间视野(P50 time horizon)。
在网络安全领域,这次的结果相当炸裂:
2019年以来整体翻倍周期9.8个月,2024年后直接陡峭到每5.7个月翻倍 !
AI的能力在2023年之前接近为零,2024年开始上升,2025年底之后则急剧增强。
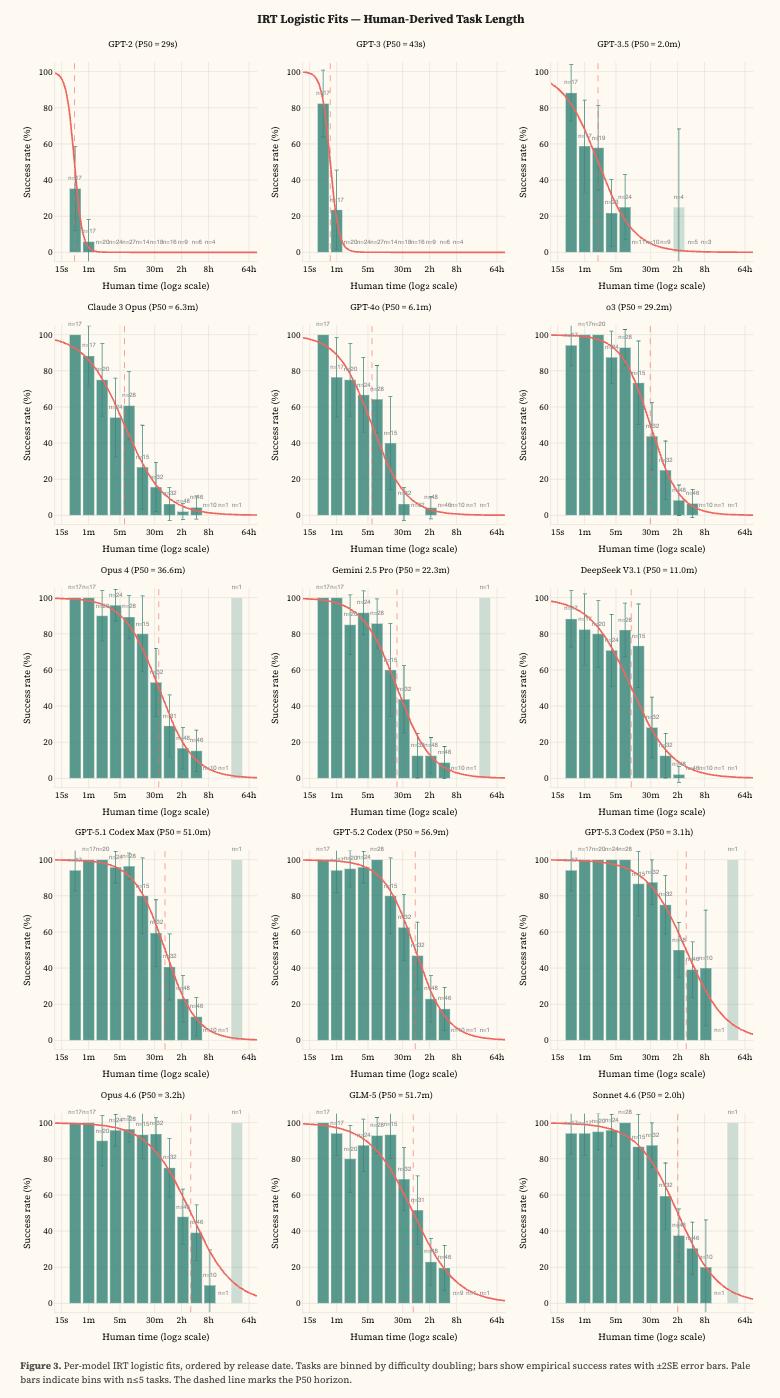
这也验证了Irregular去年的观察结论:
在过去18个月里,模型在简单与中等难度任务上的表现持续稳步提升。
在高难(hard)任务,AI进步更明显:**在2025年年中之前,模型几乎拿不到分(接近0);但到了深秋(late fall),成功率迅速抬升到大约60%** 。
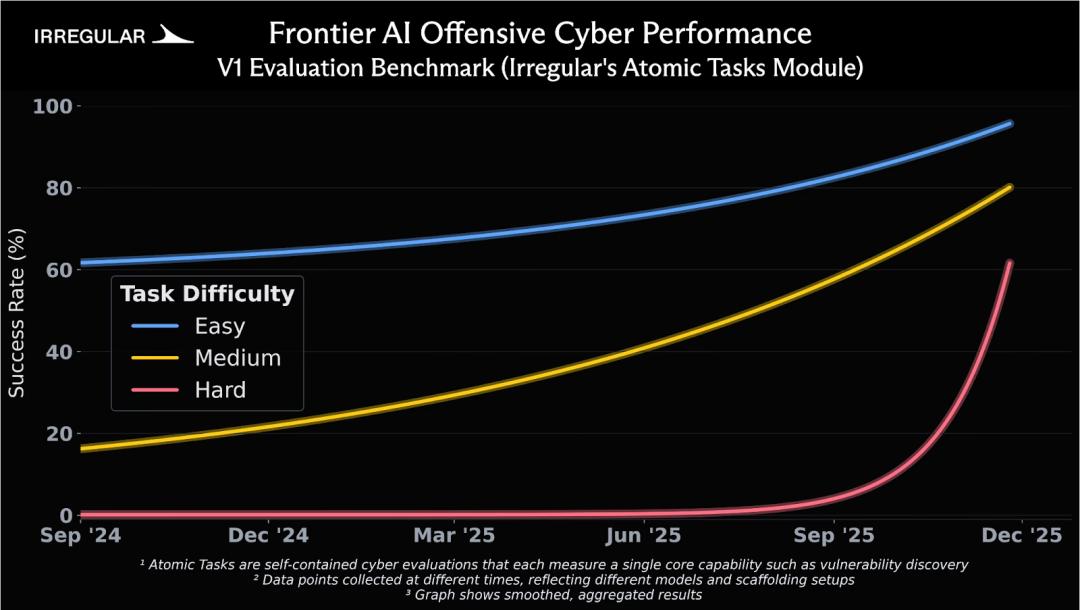
https://www.irregular.com/publications/emerging-evidence-of-a-capability-shift
GPT-5.3 Codex和Opus 4.6,在2M token预算下就50%成功率干掉人类专家3小时任务。
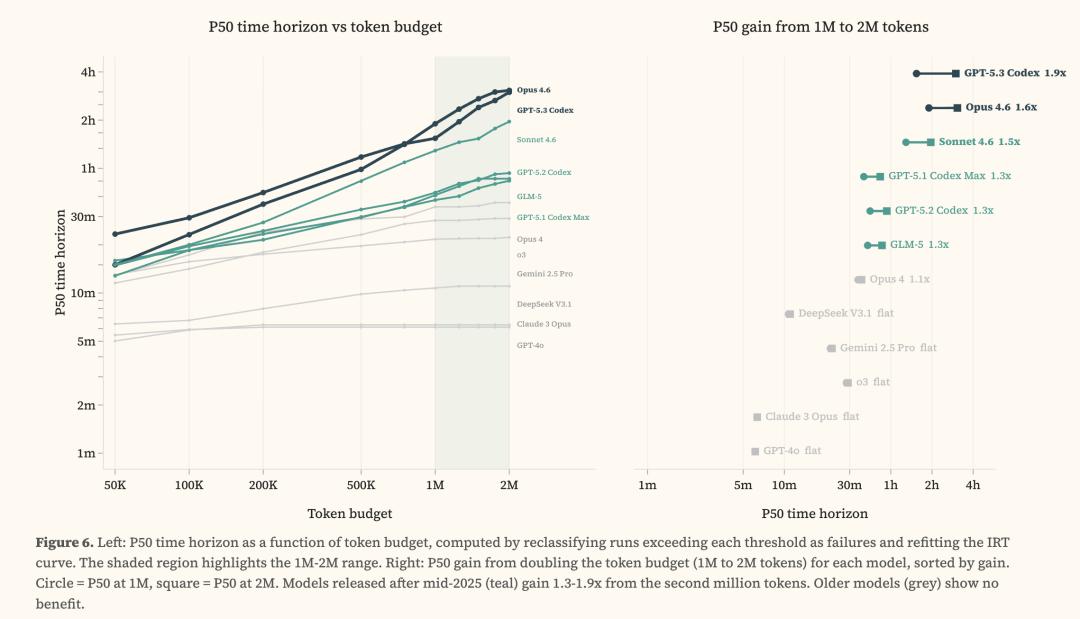
如果token拉到10M,P50直接暴增到10.5小时(置信区间2.4-63.5小时)!
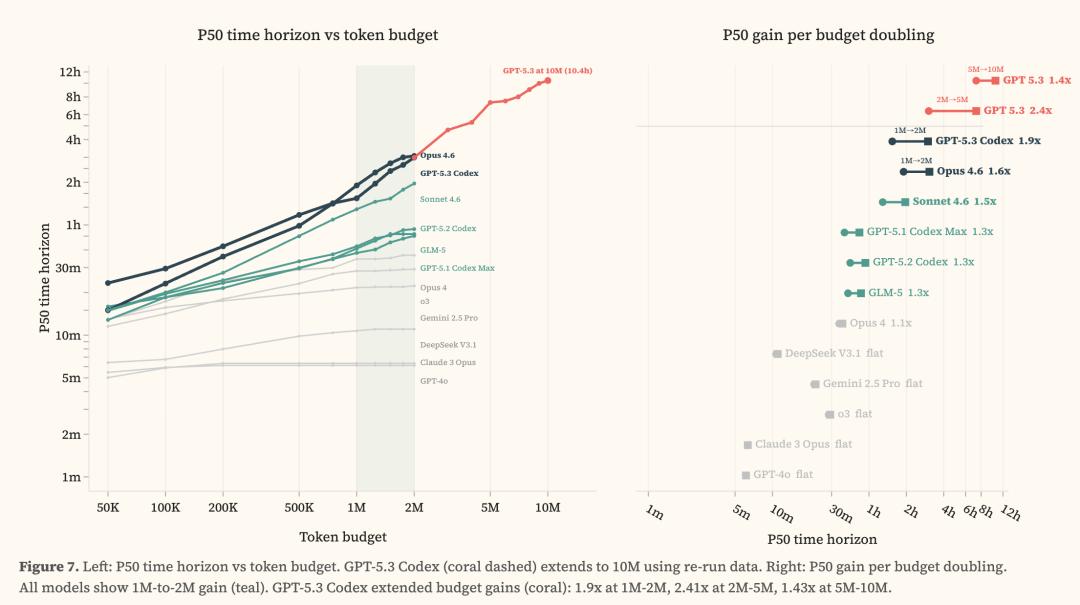
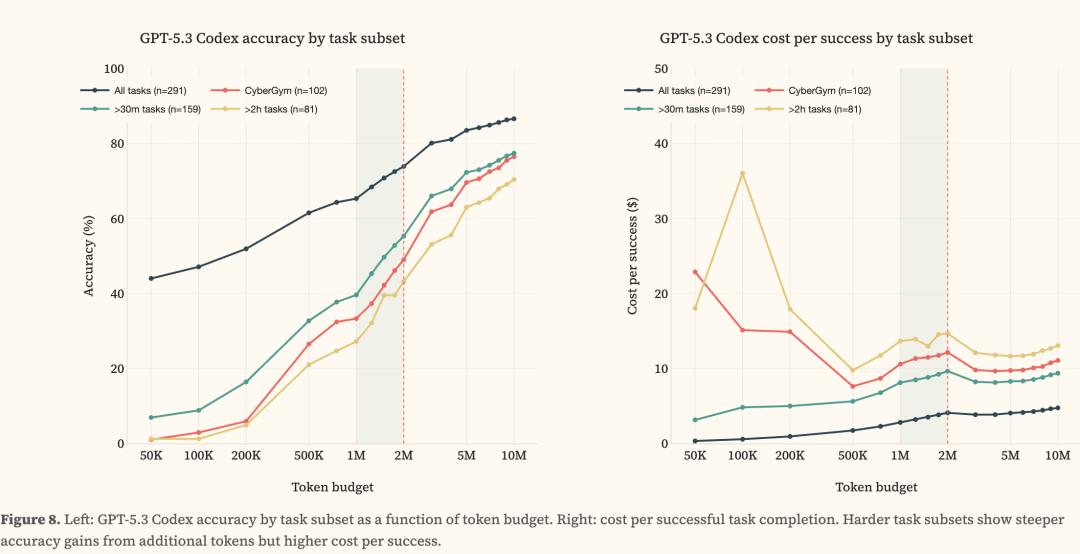
**2M token严重低估真实能力,后2025模型在1M-2M token间P50提升1.3-1.9倍!**

更吃惊的是,这还是只是今年顶级模型的能力下限,而真实世界能力,被进一步低估。

2026年底,AI就能稳定干10小时+专家级进攻任务,干完3000+劳动市场里80%的日常工作。
2027年呢?40小时?一周?
企业安全团队还在开季度会议讨论补丁时,AI已经在夜里把整条攻击链跑完了;程序员、审核员、分析师还在键盘上敲字时,AI早已把他们的「人类时间」甩到身后。
防御窗口被压缩到「近零」。
网络安全领域即将彻底颠覆——不是被「辅助」,而是被**取代**。
## **AI指数级发展!**
## **奇点将至, 又一力证**
AI在加速,在指数级进步。
别不信,都是真的。
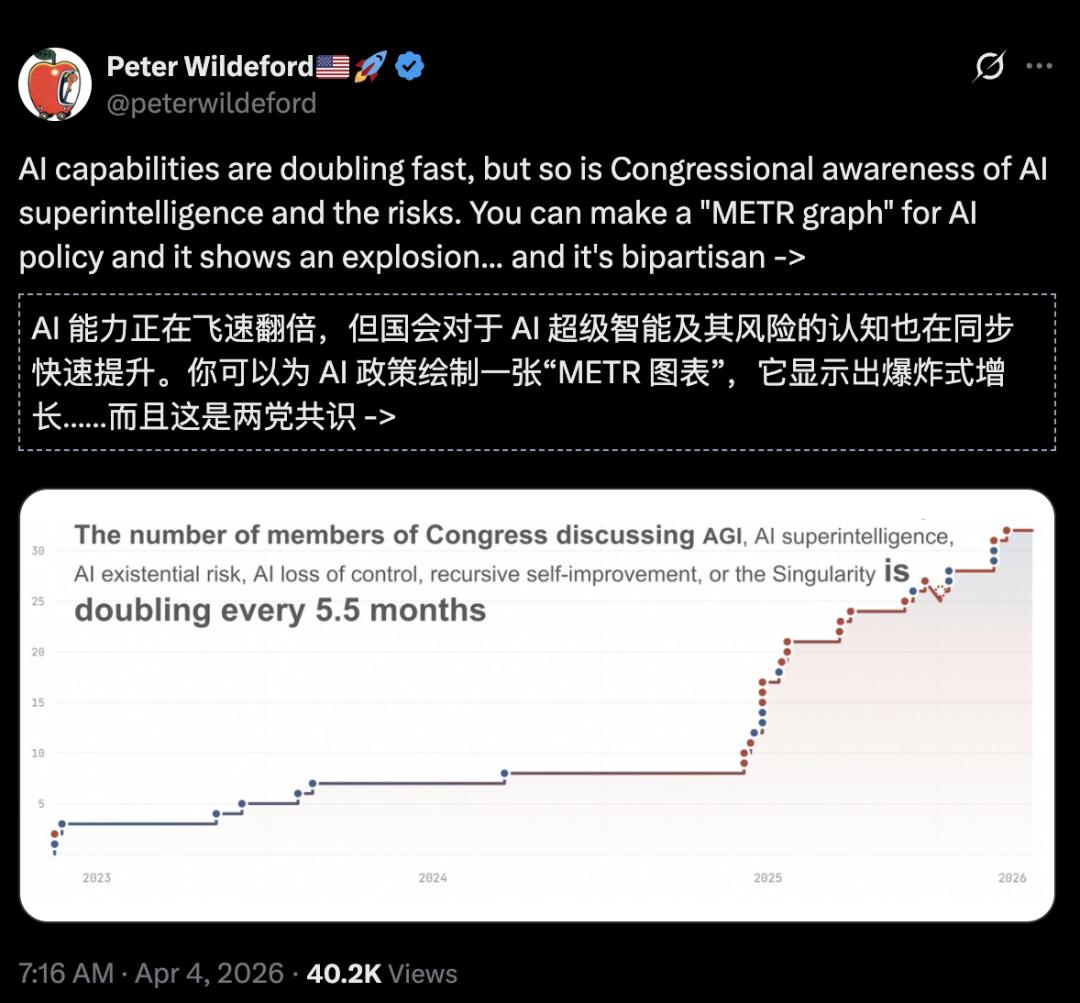
**澳大利亚AI安全研究机构Lyptus,把METR时间视界「Time Horizons」方法论第一次砸进进攻性网络安全。**
结果也和METR类似,AI能力在指数级增长:
AI模型能力每5.7个月翻一番。
前沿模型现在在那些人类专家需要10.5小时才能完成的任务上,已有50%的成功率。

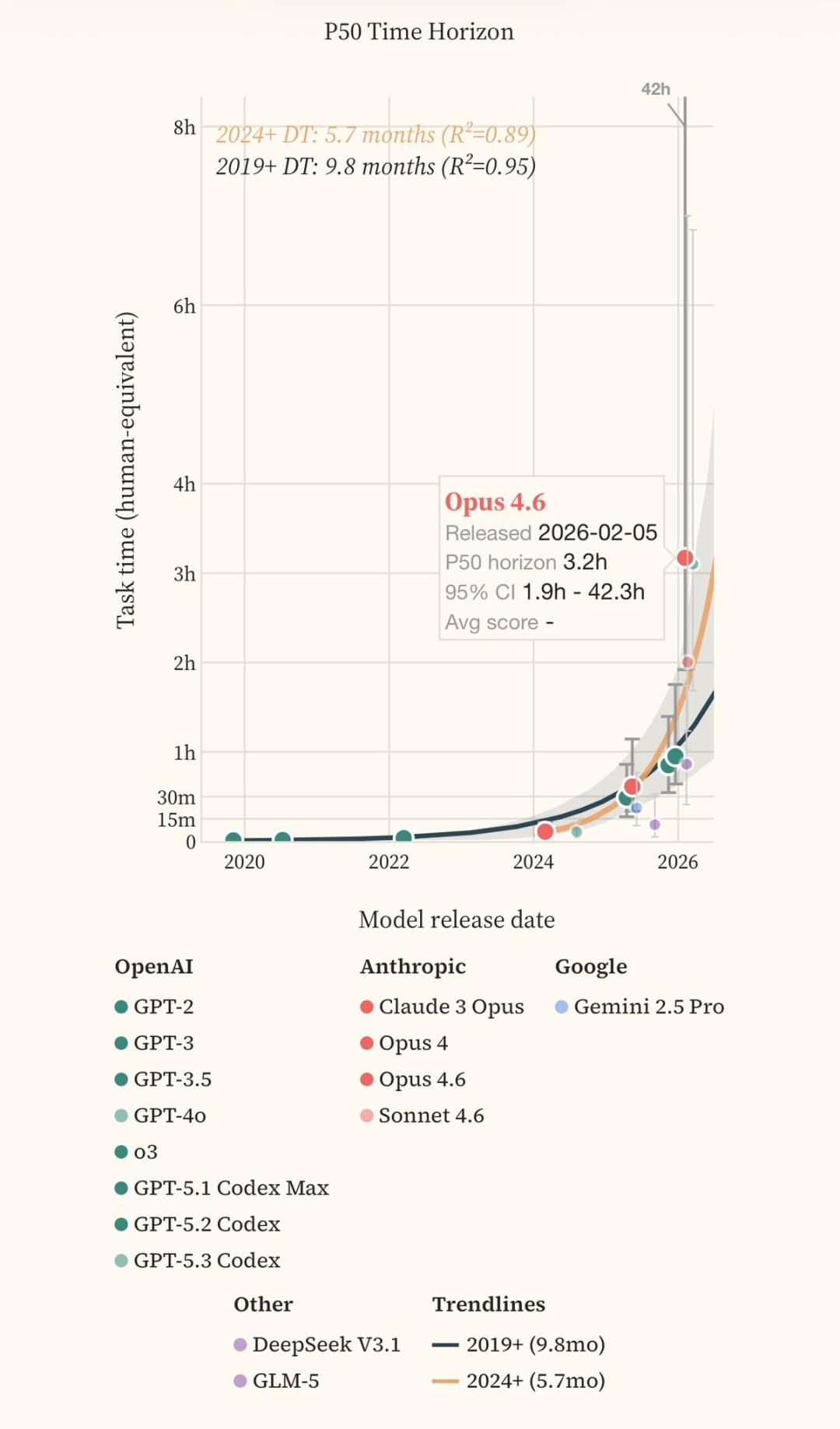
完整报告:https://lyptusresearch.org/research/offensive-cyber-time-horizons
**5.7个月翻倍**的报告刚出,Claude就用真实行动把数据锤砸得更响。
而就在前一天,MIT FutureTech的新论文,预测更大胆:
**LLMs处理任务的长度,每3.8个月翻倍——比Lyptus的5.7个月还要激进!**

论文测试了40+模型、3000+真实美国劳动市场文本任务(从客服脚本到合同审核,再到代码审查),全是人类专家每天在干的活儿。
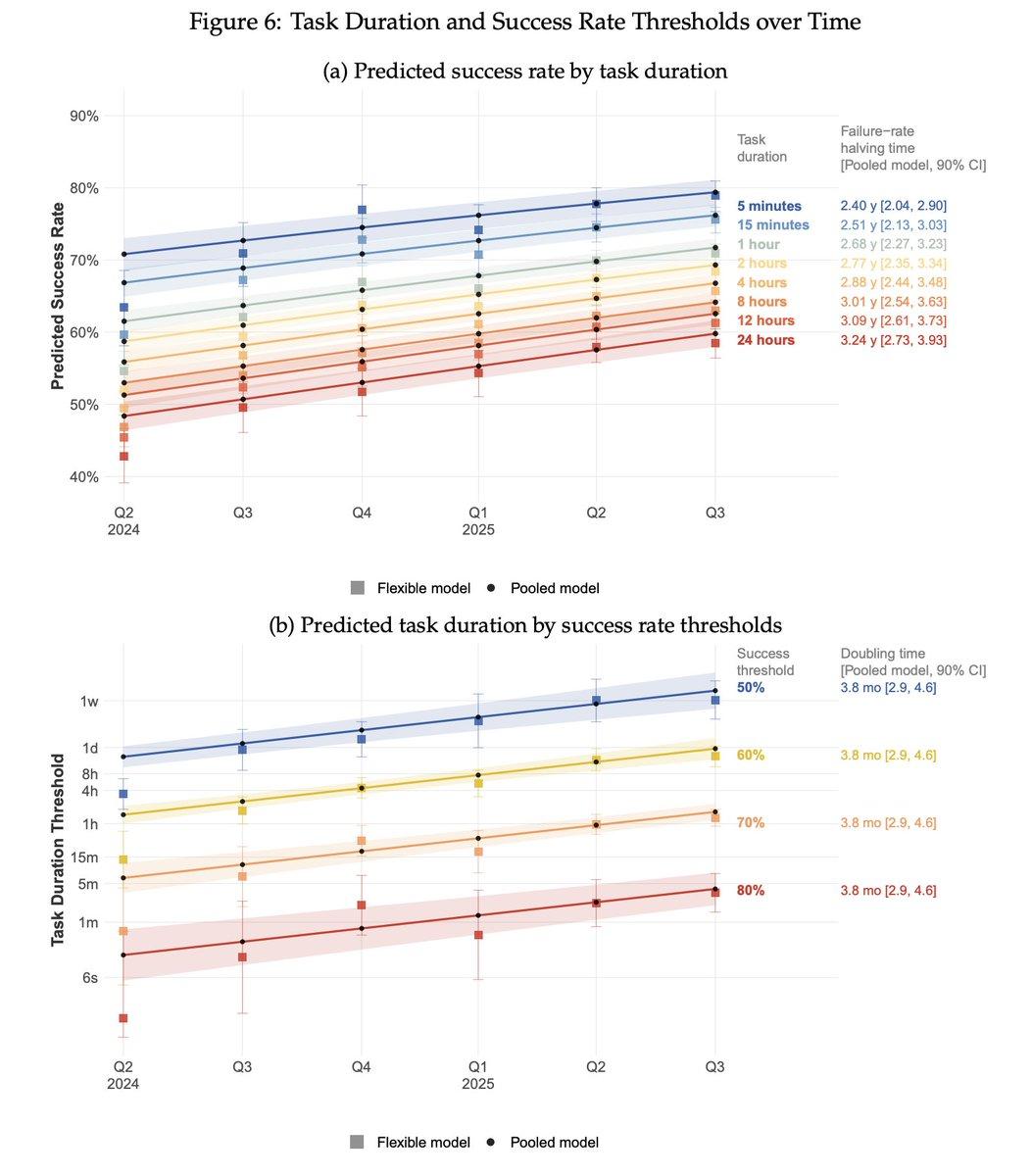
方法论和METR/Lyptus完全不同,却得出「惊人一致」的结论:**AI能力正在真实、广泛、指数级爆发。**
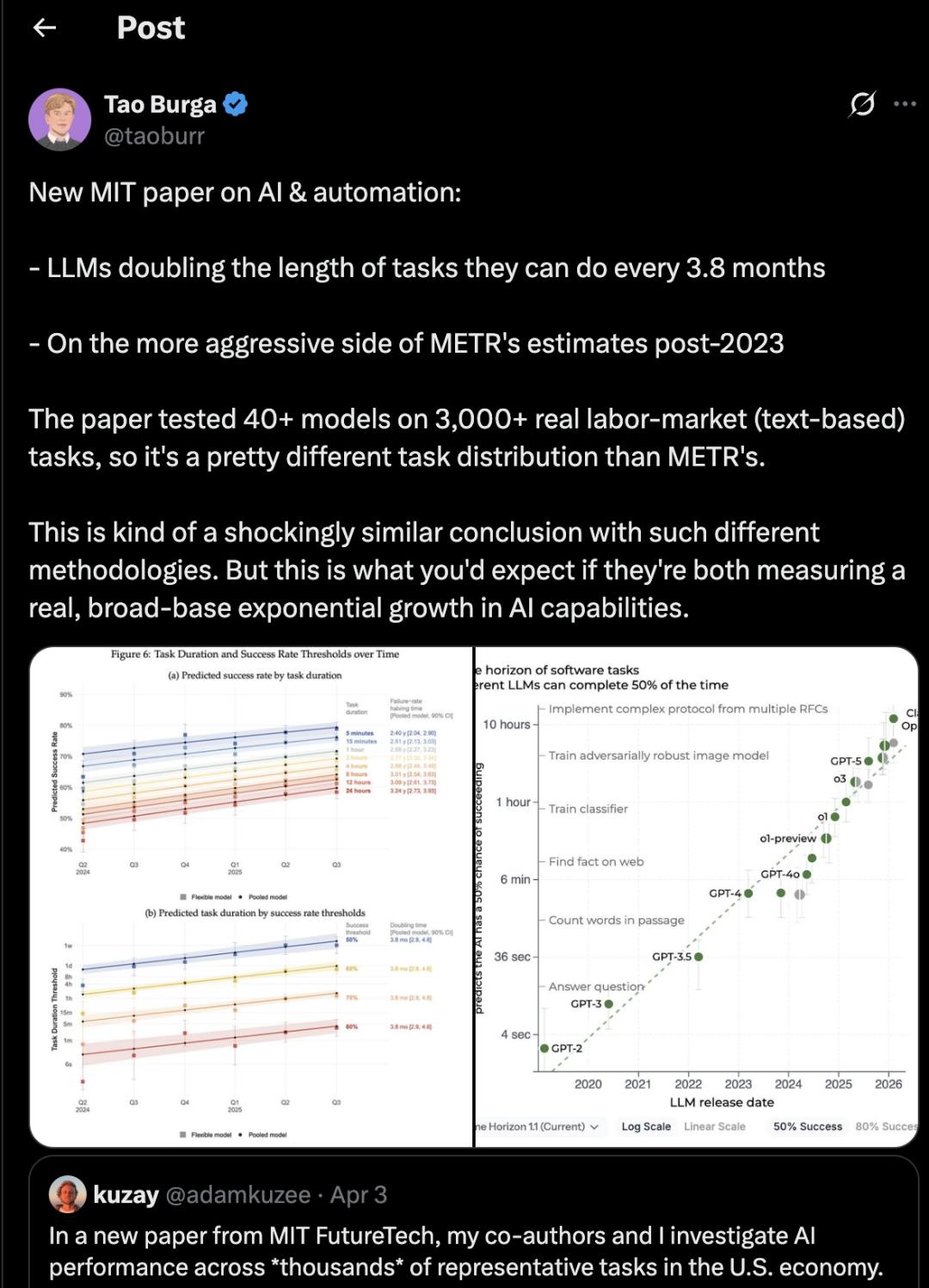
两套完全独立的评估体系,同时指向同一个真相:AI正在全面超越人类领域专家。
网络安全,只是最先崩塌的那一块多米诺骨牌。
以前国家级团队花几个月的事,现在AI睡一觉就干完。
3.8个月的任务长度翻倍,MIT从更宽的劳动市场战场证明:这不是孤例,这是宿命。
AI不仅能自主生成过去只有国家级程序才拥有的进攻能力;同时,它能在完全不同的任务分布上,以更快的速度吞噬人类专家的全部领地。
以前,人类用API调用AI。 现在,**AI开始用API调用人类**。 它调用你的内核、你的基础设施、你的信任边界、你的每一份劳动合同、每一行审查代码。
更深层的恐怖在于:这不只是技术问题,或许是人类文明宿命。
它不再需要人类手把手教,它自己就能「理解」操作系统内核、内存布局、ROP链、进程切换……
所有人类花几十年积累的黑暗知识,它4小时就学会了。
人类将成可编程资源。
我们曾经以为AI是工具,现在它成了猎手。而人类,是猎物。
是那个注定被指数级超越、被彻底重写的物种。
参考资料:
https://lyptusresearch.org/research/offensive-cyber-time-horizons#ukaisi2026inference
https://www.forbes.com/sites/amirhusain/2026/04/01/ai-just-hacked-one-of-the-worlds-most-secure-operating-systems/
https://mtlynch.io/claude-code-found-linux-vulnerability/
https://x.com/emollick/status/2040097443807641982
https://x.com/StefanFSchubert/status/2040101695636599075
https://x.com/taoburr/status/2040056341268460014
https://x.com/peterwildeford/status/2040206841376862327
本文来自微信公众号[“新智元”](https://mp.weixin.qq.com/s/_vkAHlPoBiPc9KImMkY5OA),作者:KingHZ Aeneas,36氪经授权发布。[^68]: # IDEA 的 Git 客户端,被社区单独做成了一个工具
## 来源
[原文链接](https://mp.weixin.qq.com/s/xDiksBAFo7GB8K9bdIVUNA)
## 正文
公众号名称:JAVA架构日记
作者名称:冷冷
发布时间:2026-04-07 08:31
AI 写代码的时代,桌面上的窗口变了。
以前一个 IDEA 打天下,现在 Claude Code、CodeX、Cursor、Windsurf 轮流上。代码体验确实丝滑,AI 补全、多文件编辑、上下文理解,该有的都有。
但有个问题一直没解决:Git 操作。
VS Code 自带的 Git 面板能用,但只能说是"能用"。遇到复杂的分支合并、冲突解决、多仓库管理,还是得切回 IDEA。不是 VS Code 的 Git 插件不行,是 IDEA 的 Git 客户端太强了。
问题来了:能不能把 IDEA 的 Git 客户端单独拿出来用?
**JetBrains 官方试过,2025 年夏天搞了个 Closed Beta,然后放弃了。理由是"独立价值有限"(Limited standalone value),大部分功能还是得在 IDE 里才有意义。**
但开发者不这么想。YouTrack 上那个"做个独立 Git 客户端"的需求,从 2015 年提到现在,是第 3 高票 issue。官方不做,社区就自己做。
**Rebased** 就是这么来的。
## IDEA Git 强在哪
聊 Rebased 之前,得先说清楚为什么 IDEA 的 Git 客户端这么难替代。
**三向合并**:左边你的代码,右边别人的代码,中间是最终结果。冲突用红色标,非冲突用蓝绿色。点箭头选代码,或者直接在中间编辑。关键是中间那个编辑器是完整的 IDE 环境,类型不匹配、方法签名错了,立刻有红色波浪线。不用合并完了再编译发现又炸了。
**Changelist**:本地变更分组。创建多个 Changelist,比如"重构认证"、"修 bug",文件拖进去就行。提交时选一个 Changelist,只提交这个列表的文件。更强的是"任务上下文追踪",切换 Changelist 时,打开的文件、光标位置、断点信息都跟着切。认知上下文隔离,处理 bug 时不会被其他代码干扰。
**Shelve**:比 `git stash` 灵活。存成 `.patch` 文件,可以直接发给同事。界面上勾选文件就能搁置,不用 `git stash -p` 一行行确认。多仓库项目,可以把跨仓库的改动一起搁置在一个 patch 里。
用惯了这些,再回 VS Code,感觉完全不是一个级别。
## Rebased:社区的倔强
JetBrains 说独立 Git 客户端"价值有限",社区不这么认为。
2025 年夏天官方宣布停止开发,2026 年 1 月,开发者 fork 了 IntelliJ 社区版的代码,开始做 Rebased。
思路很简单:把 IntelliJ IDEA 里除了 Git 集成之外的所有插件都删掉,再做一些 UI 调整。
听起来容易,实际上是个大工程。IntelliJ 的代码库有几百万行,各个模块耦合得很紧。要把 Git 功能干净地剥离出来,还得保证稳定性,不是随便删几个文件就行的。
## 实战体验
### 安装和启动
从 GitHub Releases 下载对应平台的安装包\[1\]。
macOS 用户会遇到一个问题:双击打开会提示"文件已损坏"。这不是真的损坏,是因为没有苹果的代码签名。运行一下这个命令就行:
```
xattr -rd com.apple.quarantine /Applications/Rebased.app
```
启动之后,界面就是精简版的 IDEA。左边是项目树,右边是编辑器,底部是 Git 面板。
### 命令行启动
命令行启动更方便。把下面这段脚本保存为 `gui`,放到 PATH 里,以后在任意目录打 `gui .` 就能直接用 Rebased 打开当前工程——从 VS Code 切过来管 Git 特别顺手:
```
#!/bin/bash
declare -a rd_args=()
declare -- wait=""
for o in "$@"; do
if [[ "$o" = "--wait" || "$o" = "-w" ]]; then
wait="-W"
o="--wait"
fi
if [[ "$o" =~ " " ]]; then
rd_args+=(\"$o\")
else
rd_args+=("$o")
fi
done
open -na "/Applications/Rebased.app/Contents/MacOS/idea" $wait --args "${rd_args[@]}"
```
这命名简单粗暴得让人喜欢。
### aicommit 插件
Rebased 相比完整的 IDEA,做了很大的精简。原来插件市场里的很多插件不兼容了。
用 AI 生成 commit message 现在很普遍,但 Rebased 精简后插件市场大部分插件都不兼容了。为此我们维护了一个单独的分支,从 GitHub 下载打包好的 zip 直接安装即可。\[2\]
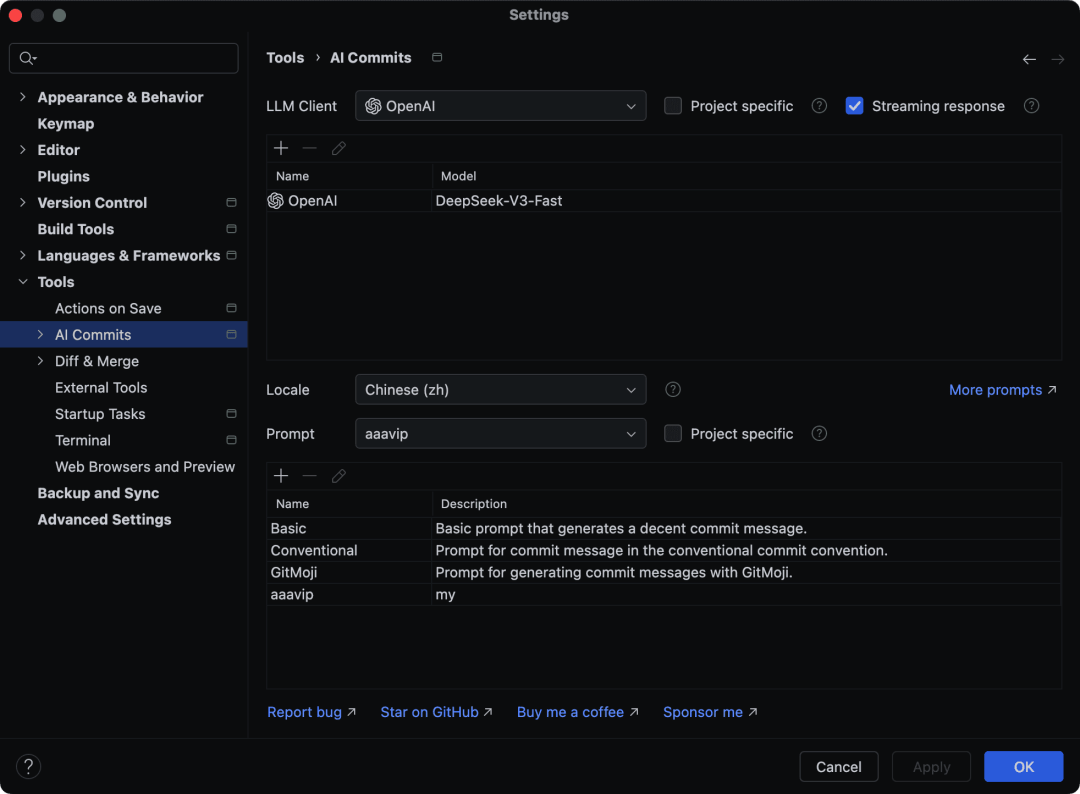
### 轻量运行
Rebased 的资源占用比完整的 IDEA 低很多。
完整的 IDEA 启动后内存占用通常在 1.5GB 以上,因为要加载各种语言支持、框架集成、代码分析引擎。Rebased 只保留了 Git 功能,启动后内存占用大约 500MB。
对于只想用 Git 功能的场景,这个差异还是挺明显的。
## 工具链
回到最开始的问题:Vibe Coding 时代,怎么平衡 AI 编辑器和 Git 管理?
现在有个答案了:VS Code 看代码 + Terminal 写代码 + Rebased 管理 Git。
VS Code 负责代码浏览、基础编辑、快速定位文件。真正的 Vibe Coding——让 AI 大段生成、重构、多文件联动——放到 Terminal 里跑,Claude Code 或其他 CLI 工具直接操作。Rebased 负责分支管理、冲突解决、多仓库同步。三个工具各司其职,不用在一个窗口里挤。
#### 引用链接
`[1]` 从 GitHub Releases 下载对应平台的安装包: *https://github.com/DetachHead/rebased/releases/tag/1.0.6*
`[2]` 从 GitHub 下载打包好的 zip 直接安装即可。: *https://github.com/pig-mesh/ai-commits-intellij-plugin/releases/tag/v2.19.1*

往期推荐

[https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491421&idx=1&sn=6480b8a90b11fd3a34c7478c29d27642&scene=21#wechat_redirect](https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491421&idx=1&sn=6480b8a90b11fd3a34c7478c29d27642&scene=21#wechat_redirect)
[PIG AI 新版更新:代码评审、智能巡检、Skills 技能三箭齐发](https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491421&idx=1&sn=6480b8a90b11fd3a34c7478c29d27642&scene=21#wechat_redirect)
[钉钉飞书同一周都发了 CLI 工具,Java 开发者如何开发自己的CLI](https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491589&idx=1&sn=3f4b0b440790996fa8eb46da4576ce0f&scene=21#wechat_redirect)
2026-04-02
[https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491589&idx=1&sn=3f4b0b440790996fa8eb46da4576ce0f&scene=21#wechat_redirect](https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491589&idx=1&sn=3f4b0b440790996fa8eb46da4576ce0f&scene=21#wechat_redirect)
[Java 实现嵌入式向量存储和混合检索,不依赖外部服务](https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491566&idx=1&sn=5a2c145da63c852b14580137696d4b82&scene=21#wechat_redirect)
2026-03-31
[https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491566&idx=1&sn=5a2c145da63c852b14580137696d4b82&scene=21#wechat_redirect](https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491566&idx=1&sn=5a2c145da63c852b14580137696d4b82&scene=21#wechat_redirect)
[【图文】IDEA 2026.1 发布:接入任意 AI Agent,Git worktree 并行开发,JS/TS 免费](https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491560&idx=1&sn=e4ff8c5480819cfca4160e64e8346e17&scene=21#wechat_redirect)
2026-03-27
[https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491560&idx=1&sn=e4ff8c5480819cfca4160e64e8346e17&scene=21#wechat_redirect](https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491560&idx=1&sn=e4ff8c5480819cfca4160e64e8346e17&scene=21#wechat_redirect)
[JetBrains 出了个 Java AI 框架,和 Spring AI 不是一个赛道](https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491530&idx=1&sn=d2f4bf905ce99cf1d7df29eb92ba141e&scene=21#wechat_redirect)
2026-03-25
[https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491530&idx=1&sn=d2f4bf905ce99cf1d7df29eb92ba141e&scene=21#wechat_redirect](https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491530&idx=1&sn=d2f4bf905ce99cf1d7df29eb92ba141e&scene=21#wechat_redirect)
[Claude Code 封号潮 ,这个工具让你的 token 省 80%](https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491522&idx=1&sn=d19a81652459f7dd0054a17183d7626c&scene=21#wechat_redirect)
2026-03-23
[https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491522&idx=1&sn=d19a81652459f7dd0054a17183d7626c&scene=21#wechat_redirect](https://mp.weixin.qq.com/s?__biz=MjM5MzEwODY4Mw==&mid=2257491522&idx=1&sn=d19a81652459f7dd0054a17183d7626c&scene=21#wechat_redirect)
---
Original 冷冷 JAVA架构日记[^69]: # 前端 20 年!正式-干掉- 骨架屏!
## 来源
[原文链接](https://mp.weixin.qq.com/s?__biz=MzUzNTk3MjE2Ng==&mid=2247523040&idx=1&sn=5d6d18a29d2399e99ffd6566aaf2c69d&chksm=fb919d242e821c8080a38cd7859bd734f0ad6e063bf642c650a95d5aa5a01a0a7fa517823bb8&mpshare=1&scene=1&srcid=0407qMGNNTPT1dJwyYPTrfMF&sharer_shareinfo=ea534e3994979b6fda9cda786b54fd64&sharer_shareinfo_first=ea534e3994979b6fda9cda786b54fd64#rd)
## 正文
公众号名称:前端开发爱好者
作者名称:认真努力的小四子
发布时间:2026-04-07 08:34
在**前端**世界里,有一件事几乎每个人都干过——**写骨架屏(Skeleton)** 。
常见做法无非两种:
- 用 `Ant Design` 这类组件库拼一个
- 或者自己`手写`一套骨架组件
问题也很现实:
- 想做到“`和真实 UI 完全一致`”,代码会非常多
- 一旦 `UI` 改了,骨架屏很容易忘记同步
- `布局复杂`一点(卡片、列表、嵌套结构),基本就是体力活
## 🚀 Boneyard:拒绝手写骨架屏
最近有个项目开始在圈子里刷屏 —— **Boneyard**

它做了一件很“反常识”的事:
- ❌ 不再手写 `Skeleton`
- ✅ 直接从真实页面“`生成 Skeleton`”
**让骨架屏不再是 UI,而是“编译产物”**
## 🧠 它到底是怎么做到的?
**Boneyard** 的核心思路大致就是:
**在构建阶段,把真实 UI “拍扁”成骨架数据**
### 核心工作流(非常关键)
整个流程其实很清晰:
#### 正常写你的组件
你不需要写任何骨架 **UI**:
#### 运行 CLI 生成骨架
```
npx boneyard-js build
```
这一步才是核心:
- 它会`启动浏览器`(Playwright)
- 扫描 `DOM`
- `记录`所有元素的位置和尺寸
最终生成一份`数据文件`:
```
.bones.json
```
本质就是:
> **UI** → **坐标数据**(x / y / width / height / radius)
>
#### 运行时直接渲染
不再依赖真实组件,只渲染“**骨架数据**”
## ⚡ 如何快速上手?
大概只需要三步:
#### 安装
```
npm install boneyard-js
```
#### 包裹组件
#### 生成骨架
```
npx boneyard-js build
```
完成之后就可以直接用了。
## 🌍 支持哪些框架?
这是 **Boneyard** 很有意思的一点:**它本质是跨框架的**
#### ✅ 官方支持
- `React`
- `React Native`
- `Svelte 5`
#### 🧩 Vue 也能用(社区版本)
虽然官方还没有 **Vue** 版本:
但社区已经有人做了适配 - **boneyard-vue**
它本质上做了一件事: 用 **Vue** 实现 `Skeleton` 运行时
所以你可以这样写:
## 💥 写在最后
**Boneyard 本质是在做一件事:把“骨架屏”从手工活,变成编译产物。**
如果说过去 **20** 年:前端在“**写 UI**”,那 **Boneyard** 在做的是:
**让 UI 的“加载态”也进入编译时代**
当 **Skeleton** 都开始被编译:
那未来会不会是:
- `loading` 不再写
- `animation` 不再写
- 甚至 `UI` 也不再“手写”
## 🔗 相关链接
- **Boneyard 官网**:[https://boneyard.vercel.app/overview](https://boneyard.vercel.app/overview)
- **Boneyard Vue**:[https://github.com/samuelbelo/boneyard-vue](https://github.com/samuelbelo/boneyard-vue)
---
Original 认真努力的小四子 前端开发爱好者[^70]: # Download Memurai for Windows | Memurai
## 来源
[原文链接](https://www.memurai.com/get-memurai)
## 正文
## Get Memurai
Choose a version:
- Memurai for Redis
The only enterprise-grade, Windows-native in-memory datastore compatible with Redis and built for production support.
Available features\*
Full compatibility with all Redis features
Version\*\*
8.2-rc1
4.2.2
Redis API
8.2.5
7.4.7
Maximum uptime
10 days before automatic shutdown
Unlimited
Maximum connected hosts
10 unique IP addresses
Unlimited
Maximum RAM utilization
50% of available system memory
Unlimited
Support
Community - Stack Overflow
Premium email, web support
Main purpose
Development and testing
Production use
Production use\*\*\*
\*Compatible with the following features: LRU eviction, persistence, transactions, LUA scripting, high availability, Pub/Sub, cluster, and the Modules API.
\*\*Memurai for Redis 8.2 RC1 is now available for [download here](#). Start testing Redis 8.2\-compatible workloads ahead of GA. Find out more about this [here](/blog/memurai-for-redis-8-rc1-preview-redis-8-compatible-performance-on-windows).
\*\*\*Usage of Memurai Developer Edition in a production environment is prohibited. The Memurai team reserves the right to modify these restrictions at any time.[^71]: # 解决 PowerShell 中 choco 命令缺失
# 解决 PowerShell 中 choco 命令缺失
## 来源
> [原文链接](https://www.doubao.com/thread/wa6b4ca12a5dbf5e5)
> **zzzzxb** 与 **豆包** 的对话 · 2026年04月19日
>
---
## 问题描述
执行以下命令时出现错误:
```powershell
choco install python visualstudio2022-workload-vctools -y
```
> [!CAUTION] 🚨 错误信息
> ```
> choco : 无法将"choco"项识别为 cmdlet、函数、脚本文件或可运行程序的名称。
> ```
>
> [!TIP] 💡 原因分析
> **未安装 Chocolatey 包管理器**,Windows 系统默认不自带 `choco` 命令。
>
### 📋 命令解析
|参数|含义|
| :----: | :----------------------------------------|
|`choco`|Chocolatey 包管理器|
|`install`|安装软件包|
|`python`|Python 编程语言|
|`visualstudio2022-workload-vctools`|Visual Studio 2022 C++ 桌面开发工作负载|
|`-y`|自动确认所有提示(无需手动输入 Yes)|
### 💡 说明
> [!TIP]
> 这条命令的作用是**一次性安装 Python 和 C++ 开发工具链**,常用于机器学习或需要编译 Python 包的场景(如安装 PyTorch、TensorFlow 等)
>
---
## 解决方案
### 第一步:以管理员身份打开 PowerShell
1. 右键点击 Windows 开始菜单
2. 选择 **Windows PowerShell (管理员)** 或 **终端 (管理员)**
> [!Caution] 注意
> 必须使用管理员权限,否则安装会失败。
>
### 第二步:安装 Chocolatey
复制以下完整命令,粘贴到管理员 PowerShell 中,按回车执行:
```powershell
Set-ExecutionPolicy Bypass -Scope Process -Force
[System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072
iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))
```
> [!Note] 预期结果
> 等待安装完成,看到 `Chocolatey installed successfully` 即表示安装成功。
>
### 第三步:重新执行安装命令
1. **关闭当前 PowerShell**
2. 重新打开一个**新的管理员 PowerShell**(刷新环境变量)
3. 执行你原本的命令:
```powershell
choco install python visualstudio2022-workload-vctools -y
```
---
## 命令解析
执行的这行命令含义如下:
|参数|含义|
| :----: | :----------------------------------------|
|`choco`|Chocolatey 包管理器|
|`install`|安装软件包|
|`python`|Python 编程语言|
|`visualstudio2022-workload-vctools`|Visual Studio 2022 C++ 桌面开发工作负载|
|`-y`|自动确认所有提示(无需手动输入 Yes)|
> [!Info] 说明
> 这条命令的作用是**一次性安装 Python 和 C++ 开发工具链**,常用于机器学习或需要编译 Python 包的场景(如安装 PyTorch、TensorFlow 等)。
>
---
## 总结
|步骤|操作|
| :----: | :-------------------------------------|
|1|报错 = 未安装 Chocolatey|
|2|用管理员 PowerShell 执行官方安装命令|
|3|重启终端后再运行原安装命令|[^72]: # 前端开发新纪元!这个22.7K Star的可视化编辑器,让你直接在浏览器里改React代码!
## 来源
[原文链接](https://mp.weixin.qq.com/s/p8nZTyiO5zP2vOX94n-7uQ)
## 正文
公众号名称:架构师修行之路
作者名称:菜菜
发布时间:2025-11-04 08:12
你是不是也遇到过这样的痛点:修改前端样式时,要在代码编辑器和浏览器之间反复切换,调整一个按钮位置就要刷新十几次页面?
别担心,今天介绍一个超厉害的开源项目来解决这个问题。它能让你直接在浏览器中可视化编辑React应用,而且改动会实时同步到代码文件。绝对会惊掉你的下巴。它就是Onlook。
## Onlook是什么?

Onlook 是一个开源的可视化开发工具,能帮助开发者在浏览器中直接编辑React应用的UI,并将修改实时写入代码文件。它支持点击选择元素、拖拽调整位置、实时预览效果,还能很方便的与VSCode无缝集成。
## 主要功能
•
**一键式可视化编辑**: 用户可以通过简单的点击和拖拽方式选择和修改页面元素,Onlook 会自动将改动同步到源代码中,无需手动编写CSS。
•
**实时代码同步**: 利用先进的AST解析技术,它能够精准定位元素对应的代码位置,使可视化操作直接转换为代码变更,确保所见即所得。
•
**跨框架支持**: 目前重点支持React、Vue等主流前端框架,并且可以与Next.js、Vite等构建工具完美配合。
## Onlook 的优势:
•
**开源开放**:零门槛,可以快速的获取和安装,项目按月迭代,社区非常活跃;
•
**简单易用**:极易上手,通过鼠标点击和拖拽方式就可以完成UI调整,你说厉不厉害;
•
**无缝集成**:直接连接本地开发环境,修改实时写入源文件,无需额外配置;
•
**精准定位**:支持多种数据分享方式,能准确识别组件层级关系,定位到具体代码行;
•
**效率倍增**:告别代码-刷新-预览的循环,可视化调整让开发效率提升10倍。
## Onlook 支持的技术栈:
•
**前端框架**: React、Vue、Svelte等主流框架
•
**构建工具**: Vite、Webpack、Next.js、Create React App等
•
**样式方案**: CSS Modules、Tailwind CSS、Styled Components等
•
**开发环境**: VSCode深度集成,支持Windows、macOS、Linux
## 快速开始
### 桌面版:
你可以在 PC 上安装 Onlook,下载地址为官网或GitHub Release页面,下载之后直接安装即可。
### 命令行安装:
```
# 通过 npm 全局安装
npm install -g onlook
# 或使用 yarn
yarn global add onlook
# 在你的 React 项目目录下启动
cd your-react-project
onlook start
```
### 使用步骤:
```
// 1. 确保你的项目支持热更新(HMR)
// 2. 启动 Onlook 应用
// 3. 导入你的本地项目
// 4. 开始可视化编辑
// 示例:直接在浏览器中点击元素进行编辑
// 修改会自动同步到类似这样的代码文件:
function Button() {
return (
Click Me
);
}
```
另外,你也可以通过 VSCode 插件 快速连接 Onlook。如果是用于团队协作,我推荐你配合版本控制系统一起使用。
## 项目图片




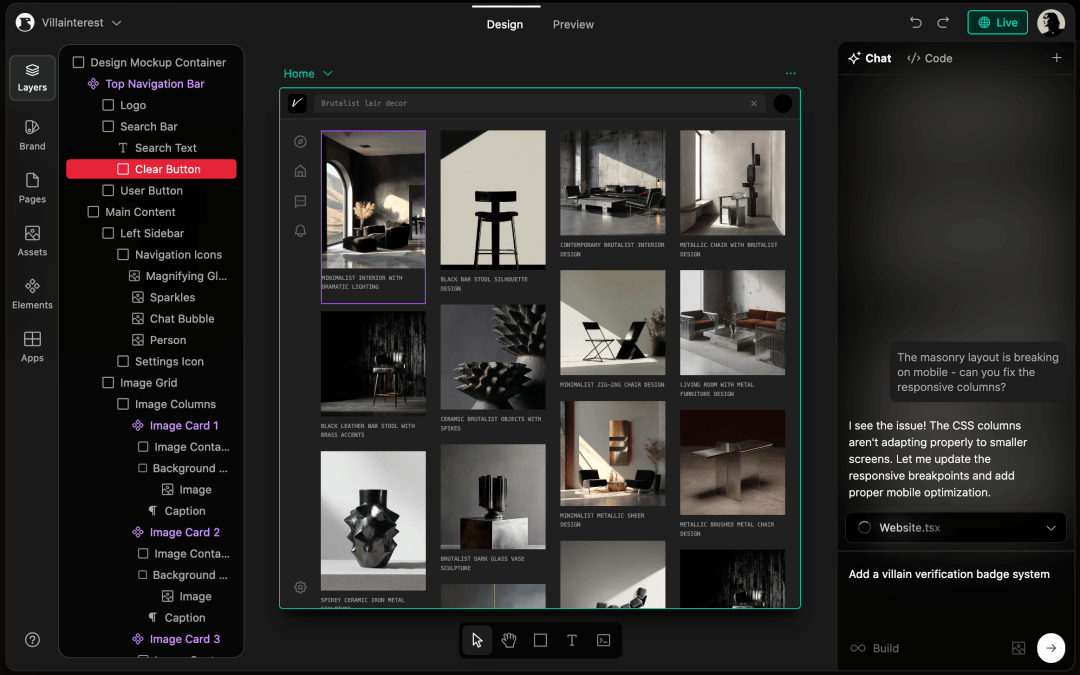
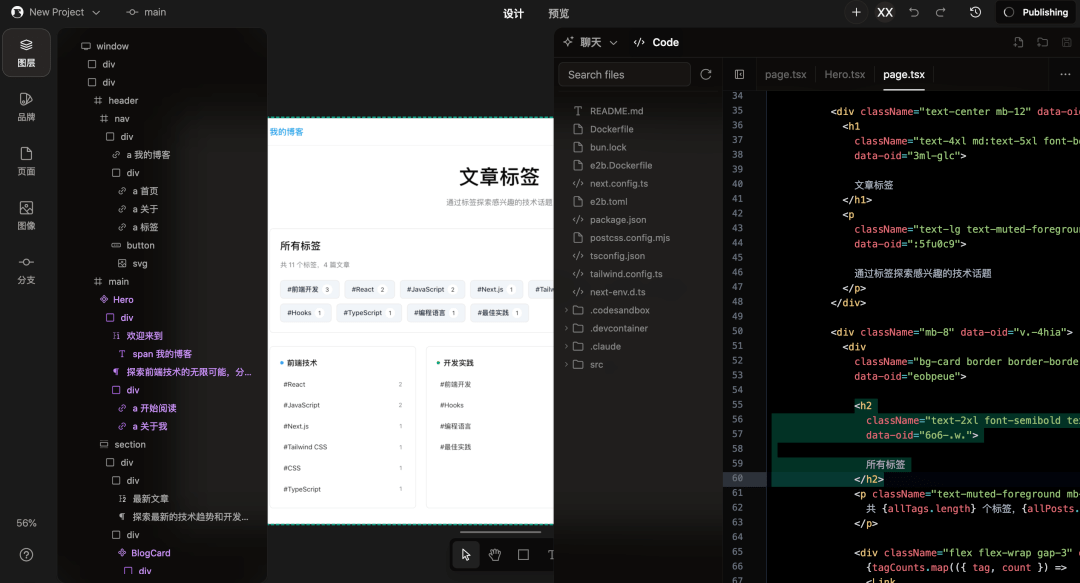
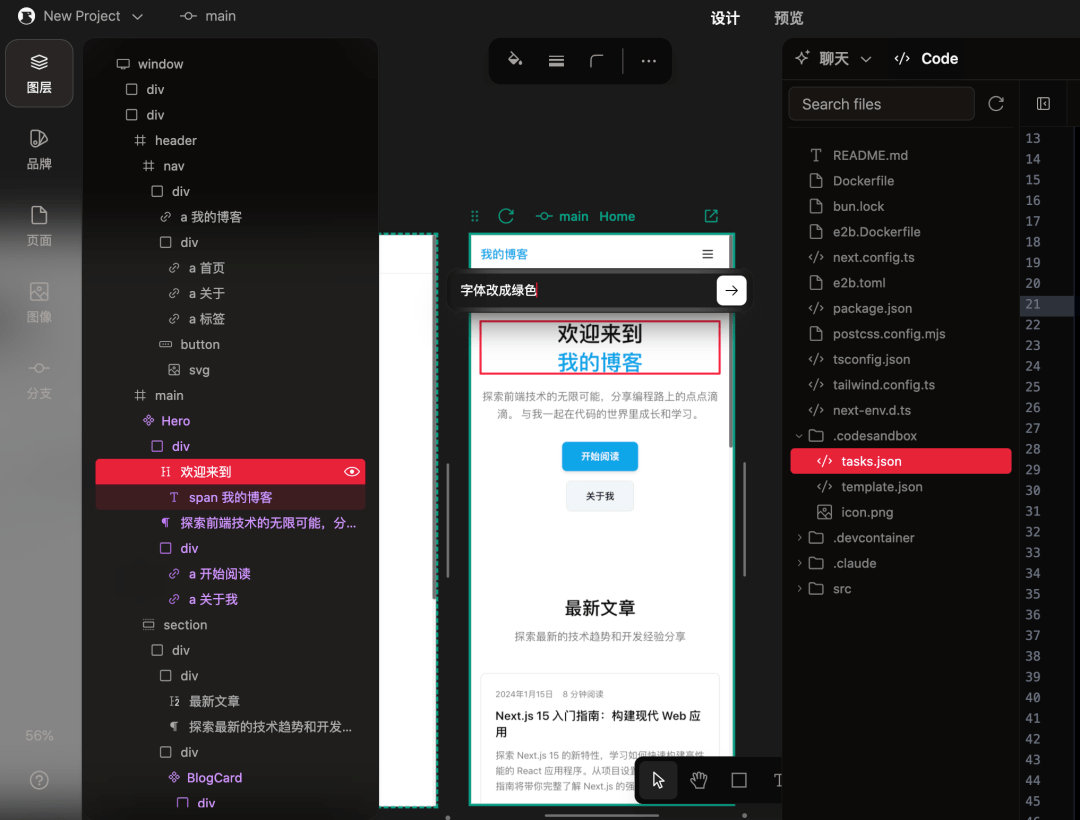

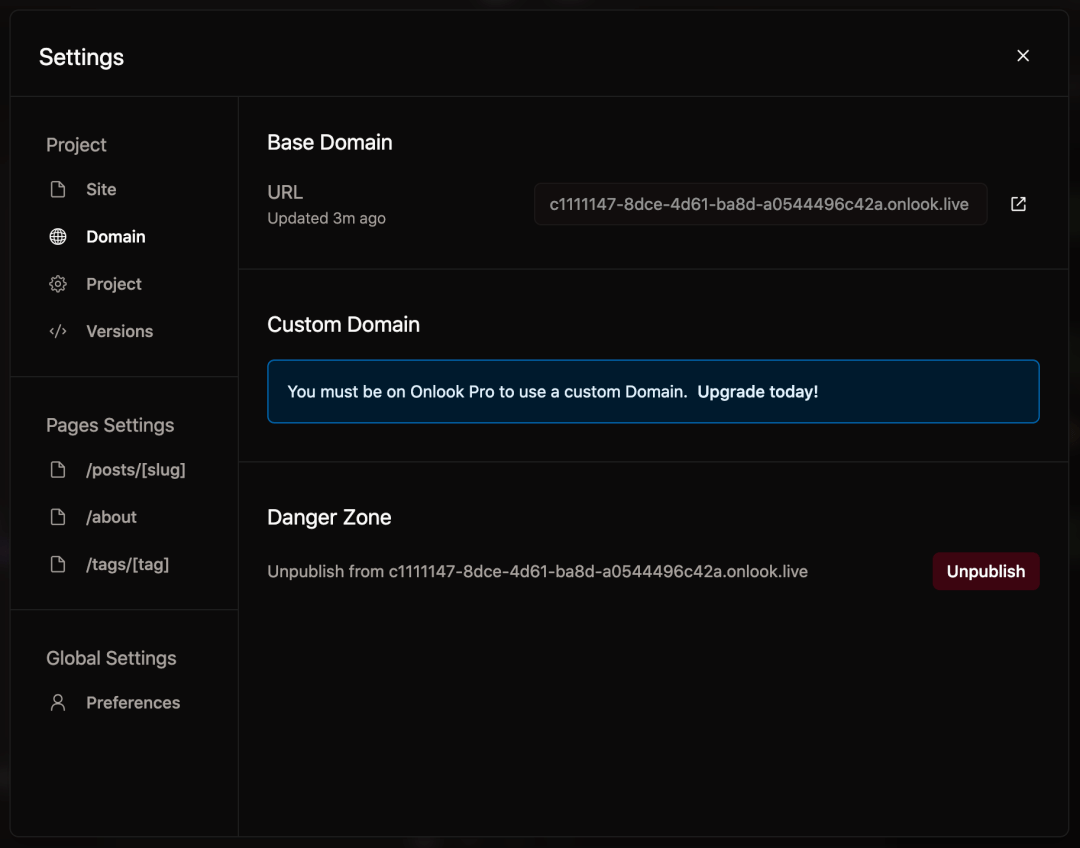
> 项目地址:https://github.com/onlook-dev/onlook
>
END
往期推荐
一键惊呆开发圈!AingDesk开源AI桌面神器:本地部署大模型,适配各种AI模型,开源免费无限制!
1秒打开!这款开源图片查看器竟比Windows自带快3倍,GitHub斩获8.9K Star!OCR识别颠覆者!Zerox:一键将PDF/图片转Markdown,复杂表格、手写体精准还原电脑里谁在偷传数据?这个开源监控工具把泄密者抓现行
---

Original 菜菜 架构师修行之路[^73]: # 前端效率 ×10!在浏览器中改 UI,代码自动写回!
## 来源
[原文链接](https://mp.weixin.qq.com/s/piRkMZNxBRSY99wvt0M6Lg)
## 正文
公众号名称:前端开发爱好者
作者名称:认真努力的小四子
发布时间:2026-04-20 08:33
在传统的 **前端开发** 流程中,我们几乎都逃不开一个循环:
`打开页面` → `打开 DevTools` → `调样式` → `切回编辑器` → `改代码` → `保存` → `刷新页面`
这个过程不复杂,但**非常频繁且低效**。
那有没有一种方式,可以直接在页面上修改 **UI**,同时**自动同步**到源码?
这正是 **react-rewrite** 想解决的问题。
### 什么是 react-rewrite?
**react-rewrite** 是一个运行在开发环境中的工具,它允许你:
在浏览器中直接编辑 **React** 页面,并将修改自动写回源代码文件
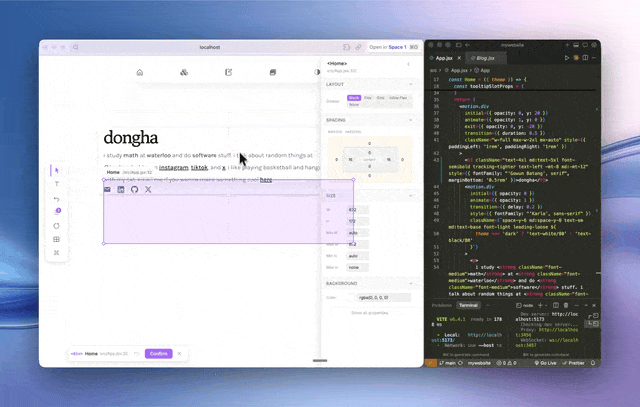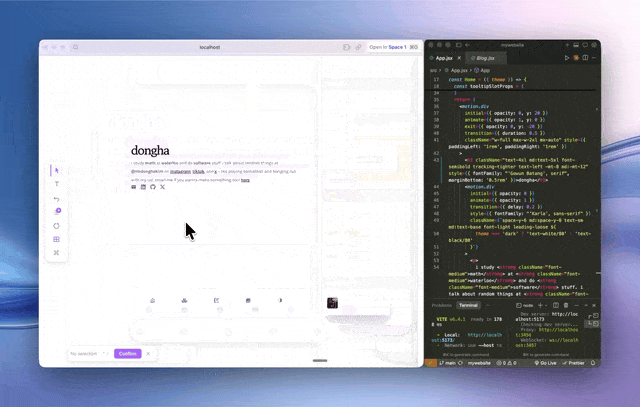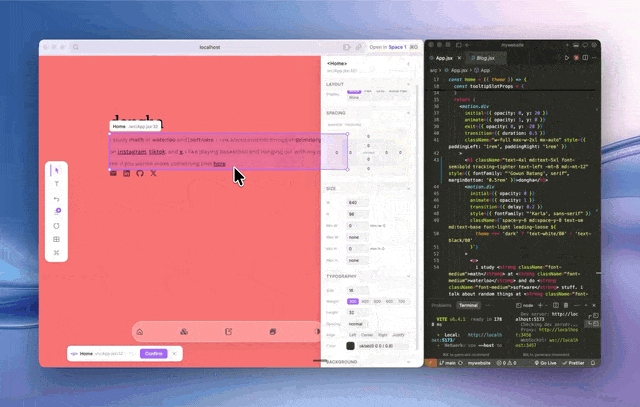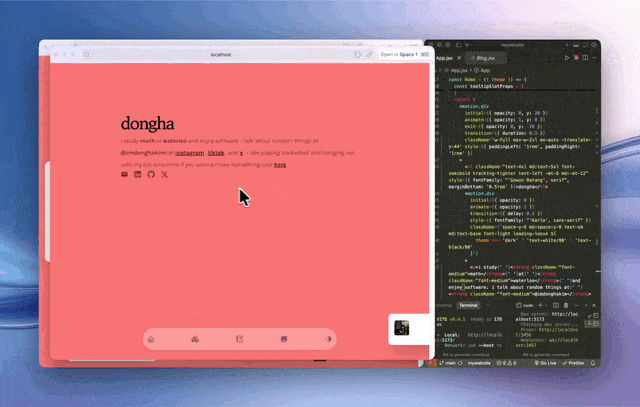
换句话说,它实现了一种:
**所见即所得(WYSIWYG)的 React 开发体验**
但和 Webflow、低代码平台不同的是:它不是替代开发,而是**增强开发体验**
### 它是怎么工作的?
react-rewrite 的核心机制可以理解为三部分:
##### 代理开发服务器
它会在你的 **React dev server** 前加一层代理,拦截和处理页面请求。
##### 注入可视化编辑层(Overlay)
在浏览器页面中插入一个“**编辑 UI 层**”,让你可以:
- `点击元素`
- `修改内容`
- `调整布局`
##### 代码反向写入(Code Rewrite)
当你点击“`Confirm`”时:
所有修改会被解析,并写回对应的 **React** 源文件
### 核心功能一览
##### 元素级信息查看
点击页面任意元素,你可以看到:
- `组件名称`
- `文件路径`
- `行号`
相当于 `DevTools + IDE` 定位结合
##### 可视化样式编辑(特别适合 Tailwind)
支持直接修改:
- `间距`(margin / padding)
- `尺寸`(width / height)
- `字体`
- `颜色`
- `布局`(flex / grid)
尤其对 **Tailwind** 用户非常友好
##### 文本直接编辑
双击页面文本即可修改:**不需要再去找 JSX**
##### 结构操作
支持:
- `删除元素`
- `复制 / 粘贴`
- `拖拽调整顺序`
类似在“搭页面”,但背后是 React 代码
##### 变更管理
- `所有修改会暂存`
- `可统一确认`(Confirm)
- `支持撤销`(Undo)
- `可查看变更记录`(changelog)
有点像 **Git staging** 的感觉
### 使用流程(非常简单)
1. 启动 **React** 开发服务器
2. 运行:
```
npx react-rewrite
```
3. 打开页面后:
- `点击元素`
- `修改样式 / 文本 / 结构`
- `点击 Confirm`
修改自动写入代码
##### 相关技术要求
- `Node.js 20+`
- `React 18+`
- `仅支持开发环境`
支持:
- `Next.js`
- `Vite`
- `Create React App`
### 写在最后
> **react-rewrite = 在浏览器里改 UI,同时自动改 React 代码**
>
它不是革命性的框架,但绝对是:**一个能明显提升开发体验的小工具**
- Github 相关地址:[https://github.com/donghaxkim/react-rewrite](https://github.com/donghaxkim/react-rewrite)
---
Original 认真努力的小四子 前端开发爱好者[^74]: # RAG 是什么?16 种 RAG 方案一次讲清!AI 应用开发必学 | 万字干货
## 来源
[原文链接](https://www.bilibili.com/opus/1194341967364882439)
## 正文
大家好,我是程序员鱼皮。
最近这两年,只要你接触过 AI 编程,大概率听过一个词,RAG(Retrieval-Augmented Generation)。
但很多小伙伴对 RAG 都只是一知半解,导致面试的时候只能说出 “检索增强生成” 这六个字,面试官再多问一点,就只能 “阿巴阿巴”。
而这篇文章,是对 RAG 技术的一个全景科普,从最初的 Naive RAG、到现在最主流的 Agentic RAG,总共 16 种主流 RAG 方案,我会一次性给大家讲清楚。以后开发 AI 应用的过程中,无论遇到什么场景,都能选择最合适的 RAG 方案。
干货比较多,建议先点赞收藏,再慢慢往下看~
AI 大模型有一些硬伤,比如:
1. 知识有截止日期
2. 会一本正经地胡说八道,也就是我们常说的幻觉
3. 缺乏私有知识,了解不到内部的文档写了什么
比如问 DeepSeek:程序员鱼皮的最新项目是什么?
结果它给我扯了个两年半以前的项目出来,技术栈也完全不对!
解决这个问题就可以用 RAG。RAG 的核心思想是 **先搜再答**,让大模型在回答之前先去搜一遍相关资料,再基于搜到的知识来组织答案。
就跟考试的时候偷偷翻书一样,遇到不会的先翻一翻书,再根据书里的知识答题。
还是问 AI 同样的问题,我们主动给 AI 一些参考资料,他的回答就会准确一些:

这个思路听起来简单,但在实际工程上 RAG 已经演化出了很多种不同的实现方法,从最初的「切块 → 搜索 → 生成」,到让 AI Agent 自主决策检索策略的 Agentic RAG,复杂度和能力天差地别。
有朋友可能会问:现在的大模型不是已经支持百万 token 的上下文窗口了,还需要 RAG 吗?
答案是:**需要,而且用得比以前更多了!**
因为把所有文档塞进上下文窗口,既贵又不靠谱。上下文越长 token 费用越高,而且大模型普遍存在 “Lost in the Middle” 问题,顾名思义,就是对超长上下文中间部分的注意力会明显下降。
这个也不难理解,就像听别人说话一样,我们对开头和结尾的印象会相对深刻一些,中间的总是容易忘记。
不过呢,RAG 和长上下文也不是互斥的关系,现在一般的最佳实践是先用 RAG 给 AI 提供相对精确的资料,再利用长上下文窗口进行有针对性的分析推理,两者互补。
好,背景交代完了。下面我们正式进入主题,挨个讲讲每种 RAG 方案。
我们先从最基础的 RAG 讲起,如果你之前完全没接触过 RAG,看完这一节就能理解它的核心原理。
## 主流 RAG 方案
### 标准 RAG 及变体
Naive RAG
Naive RAG 这个词听起来就很牛对不对?
但其实,Naive 是朴素的意思,Naive RAG 是最基本的 RAG 实现方案。
假设你有一份 200 页的公司员工手册,怎么让 AI 基于里面的内容回答员工的提问呢?
最简单粗暴的做法就是每次提问都把整本手册塞给 AI 大模型。
但是一本手册可能几十万字,全塞进去又贵又慢,而且上下文一长,大模型还容易犯前面提到的 “Lost in the Middle” 的毛病,导致回答质量下降。
所以更合理的思路是:员工问什么,我们就只把相关的几段内容塞给 AI。
那问题又来了,怎么定位到相关的那几段呢?
如果用关键词匹配,很容易出现问题和文档里的关键词不一致的问题,比如员工问 “老板不批假怎么办”,文档里写的是 “请假审批流程”,关键词对不上,就搜不到。
这就需要用到 **向量** 了。
所谓向量,就是把一段文字用一串数字表示出来,让计算机可以比较语义上的相似度。
举几个例子感受一下:
文本 向量(简化示意) 我喜欢吃鱼 \[0.21, 0.85, 0.13, ...\] 我爱吃海鲜 \[0.23, 0.82, 0.15, ...\] 今天天气真好 \[0.88, 0.12, 0.41, ...\]
语义越接近的句子,它们的向量在数学空间里离得越近。
负责把文字转成向量的模型,叫 Embedding 模型;存储这些向量并支持快速相似度搜索的数据库,叫向量数据库,比如 Milvus、Chroma、Qdrant 等。
理解了向量,Naive RAG 的做法就很好理解了,主要分为两步。
第一步是离线索引:
1. 把文档切成小块(chunk),每块几百字
2. 用 Embedding 模型把每个小块转成向量
3. 把向量和对应原文都存进向量数据库
第二步是在线查询问答:
1. 把用户问题也用 Embedding 模型转成向量
2. 去向量库里搜最相似的几个文档块(比如 Top 5)
3. 把这几个块和用户问题拼成 Prompt,交给大模型生成回答
回到开头那份 200 页的员工手册。我们先把它切成几百个小块并向量化入库,当员工问 “年假有多少天?” 的时候,RAG 的执行流程是这样的:
1. 系统把问题转成向量
2. 在向量库里找到最相似的 5 个文档块(比如某块写着 “入职满一年享有 10 天年假,满三年 15 天…”)
3. 把这 5 个块连同问题一起交给大模型
4. 大模型回答:“入职满一年享有 10 天年假”

不过 Naive RAG 也有一些比较明显的问题:
- 切块方式粗暴,可能把一段完整的语义从中间截断
- 检索质量完全依赖 embedding 模型,搜不到就没辙
- 搜到了垃圾文档也不管,导致输出错误答案
这些局限,就是后面所有进阶方法要解决的问题。
下面我用伪代码来帮助大家理解,不熟悉编程的同学可以跳过,不影响后续的学习~
1)离线索引阶段:
2)在线查询阶段:
Multi-Query RAG
用户提问的方式千奇百怪。比如同样是想知道公司报销流程,有人会问怎么报销,有人会问费用审批流程是什么,还有人会问花了钱怎么找公司要回来。
但文档里可能只写了 “报销申请流程” 这个表述,如果用户的措辞和文档差距太大,向量检索就可能搜不到正确的内容。
Multi-Query 的思路就是:既然一种问法搜不全,那就让大模型把原始问题改成多种不同的表述,分别去搜,最后把结果合并去重。
这种方法的代价就是每次提问要多调用一次 LLM 做改写,再多跑 N 次向量检索,延迟和成本都会增加。
而且如果 LLM 改写出的问题方向跑偏,会把无关文档也带进来,影响答案质量。
所以它比较适合 **面向普通用户的客服、电商等场景**,用户表述口语化、和文档术语差距大,多花这点成本还是有必要的。但是在术语规范的专业领域,Multi-Query 的收益就很有限了。
Multi-Query RAG 的代码实现如下:
HyDE
AI 回复的效果不好,可能不是因为用户的问法不好,而是用户的问题和文档的语义空间不一致。
用户的提问往往很短,比如 “KV Cache 是什么?”,就这么几个字。
但文档里关于 KV Cache 的描述可能是一大段技术解释。一短一长,在 embedding 空间中可能离得很远,就检索不到了。
HyDE 的做法就是让大模型凭空写一个答案(不必完全准确),然后用这段假答案的向量去检索。因为假答案和真文档的文体更接近,两者在向量空间中离得也更近。
还是上面的例子,用户问:“KV Cache 是什么?”
LLM 先编一段假答案:“KV Cache 是一种在 Transformer 推理过程中缓存 Key 和 Value 矩阵的优化技术,可以避免重复计算…”
这段假答案虽然不一定完全准确,但它的向量和真实文档里关于 KV Cache 的那段描述非常接近,所以能精准命中正确的文档。
不过 HyDE 也有一个风险,如果 LLM 编的假答案方向完全跑偏了(比如把 KV Cache 理解成了 Redis 缓存),那检索结果就会更差。所以它比较适合 LLM 对问题领域有基本认知的场景,冷门领域或企业私有术语慎用。
HyDE 的代码示例如下:
上面这三种方法,解决的是「能不能搜到」的问题。但搜到之后,资料的质量好不好呢?这就是下面要处理的了。
### 提升检索质量
语义分块(Semantic Chunking)
Naive RAG 里最粗暴的一步就是切块,每 500 个字切一刀,管你是不是正好切在一句话中间。
比如某块文本是 “员工请假需要提前 3 天申请,超过 5 天需要”
刚好在这里被截断了,下一个块从 “部门经理审批” 开始。
这两个块单独看都不完整,检索和 AI 的理解都会打折扣。
虽然可以通过 chunk\_overlap 设置相邻块之间重复内容的长度,但是效果相对有限。
语义分块的做法是先把文档按句子拆开,计算相邻句子的 embedding 相似度,当相似度突然下降时,说明话题变了,就在这里切一刀,尽量保证每个句子的语义都是完整的:
其余的步骤就跟 Naive RAG 一致了。
不过这种方式代价也不小,首先要为每一句话都算一次 embedding,成本和耗时比按字数切分要高。
而且相似度阈值非常难调,所以它比较适合结构松散、话题变化比较快的文档,像会议纪要、访谈记录这些。
对于本身就有清晰章节结构的技术手册、产品说明文档,直接按标题切效果也不差,还更便宜。
语义分块的伪代码示例如下:
层级索引(Parent-Child Retrieval)
切块这件事有一个天然矛盾。切得小吧,检索精度高但上下文不足;切得大吧,上下文丰富但噪声也大。
Parent-Child Retrieval 的策略则是 **两层都要**。
先把文档切成大块,再把每个大块细分成小块。检索时用小块匹配,命中后返回它所属的大块。
相当于在书里搜到了某一句话时,读的时候把它所在的整个章节都拿过来看:
学过数据库的朋友们应该对这种思路不陌生吧?
这种方案就很适合长文档场景,比如技术手册、法律合同、产品文档这些内容,往往需要连带上下文一起看才能理解。
层级索引的伪代码实现如下:
Hybrid Search 混合检索
纯向量检索有一个缺点,就是无法精确术语匹配。
比如用户问:“ERROR\_CODE\_4012 是什么意思?”
向量检索会去找语义相似的内容。
但这种编码本身没什么语义,向量搜索可能找到一堆讲错误处理的段落,就是找不到那个精确提到 4012 的段落。
而传统的关键词搜索擅长精确匹配,但不理解语义。
比如搜 “如何退款”,就搜不到写着 “退货及返还货款流程” 的文档,类似数据库里的 like 操作。
Hybrid Search 就是同时使用两种搜索,然后合并排序。向量搜索负责语义理解,BM25 负责精确匹配,通过 RRF(Reciprocal Rank Fusion 倒数排序融合)算法,把两边的结果合并成一个排序。
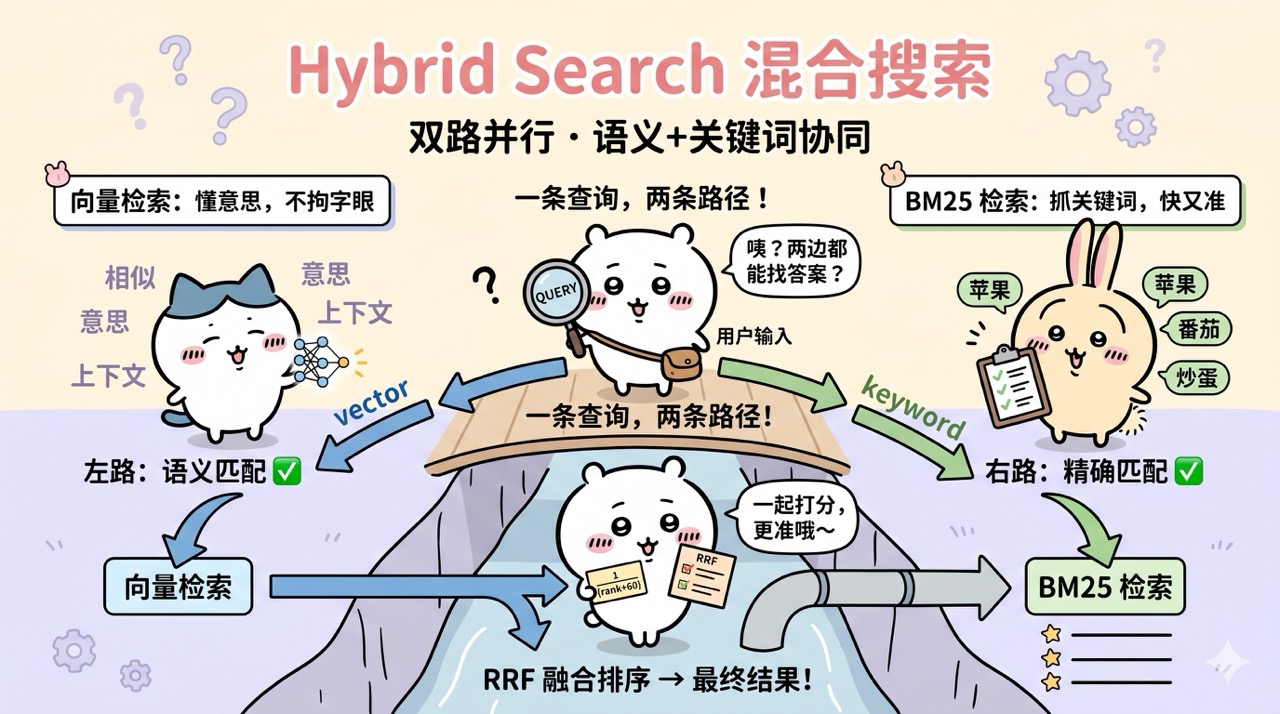
几乎所有生产环境都建议用 Hybrid Search 替代纯向量搜索,尤其是像技术文档、医疗、法律等术语密集的领域。
Hybrid Search 混合检索的实现代码如下:
Reranking 精排
不管是向量搜索还是 Hybrid Search,检索回来的候选文档里总会混着一些看起来相关但实际没用的噪声。
Reranking 的做法是在检索和生成之间加一个精排步骤:用 Reranker 模型给每对 (query, doc) 重新打分。
前面提到的 embedding 模型是分别给 query 和 doc 算向量再比较距离,快但粗糙,Reranker 是把它们拼在一起送进模型打分,慢但精准。
在实际生产中,如果语料库有十万级以上的 chunk,一般会采用级联检索方案,分层筛选:
为什么分这么多层呢?
如果使用粗检索,只捞 20 个内容,在大型语料库里很容易漏掉关键文档;但如果一次性捞 150 个,全送进 Cross-Encoder 交叉编码器来精确计算两个文本片段的相关性分数,算力又扛不住。
分层筛选则是在召回率和计算成本之间找平衡。当语料库里的 chunk 比较多时,Reranking 的效果提升会非常显著。
可以这么理解,粗检索负责不遗漏,精排负责不掺假,跟推荐系统里的粗排和精排很像。
分层筛选的实现代码如下:
到这里,我们已经能搭出一个相当不错的 RAG 系统了,语义分块 + Hybrid Search + Reranking,这三板斧组合起来,就是大多数生产级 RAG 系统的基础配置。
前面的方法都在优化怎么搜得更准,但有一个更根本的问题没解决:如果搜到的全是垃圾,大模型还是会一本正经地基于这些垃圾内容生成答案。
这就像开卷考试带错了书,还照着抄了上去……
所以接下来我们要聊一聊,怎么让 RAG 学会自我纠错。
### RAG 反思机制
Corrective RAG(CRAG)
不管我们怎么优化检索,总会有搜不到或者搜歪了的情况,这时候大模型如果还硬着头皮拿这些内容去回答,那就避免不了一本正经地胡说八道。
而 CRAG 就是 **把搜到的资料过滤一遍** 来解决这个问题的。
具体做法就是在检索和生成之间插一个质检员,逐个审查检索到的文档是否和问题相关,然后根据审查结果走不同的分支。
- 打分高的,说明资料靠谱,直接喂给大模型生成答案
- 打分低的,说明内部知识库里压根没找着相关内容,干脆回退到 Web 搜索兜底
- 打分模糊的,就两边的结果合一起送进去
Corrective RAG 的示例实现代码如下:
最关键的是那个 else 分支,如果内部知识库完全搜不到有用信息,CRAG 会自动回退到 Web 搜索(当然也可以是其他策略)。
Self-RAG
CRAG 在检索阶段做了质检,但是生成阶段呢?
大模型完全有可能拿到了正确的参考资料,但回答的时候夹带私货,在答案里掺入了参考资料中根本没提到的内容。这就是生成阶段的幻觉。
Self-RAG 的思路是在整个流程中设置四个检查点,每一步都让模型自我审视:
- 这个问题需要检索吗(Retrieve)?
- 检索到的文档相关吗(IsRel)?
- 我的回答有文档支撑吗(IsSup)?
- 这个答案对用户有用吗(IsUse)?
Self-RAG 的示例实现代码如下:
一般来说第三个检查点的价值相对较高,能在一定程度上避免 AI 的幻觉。
Adaptive RAG
CRAG 和 Self-RAG 都在给 RAG 加流程来解决问题,但这样多了好几次 LLM 调用,增加了成本。
如果用户问的是 “你好” 或者 “今天星期几”,还要跑一遍完整的检索 + 质检 + 生成流程,有点开着坦克去买菜的意思,纯属浪费。
Adaptive RAG 在最前面加了一个路由器(分类器),先判断问题的复杂度,然后决定走哪条路线:
Adaptive RAG 的实现代码很简单:
这个分类器可以是一个微调的小模型,也可以用 LLM 的 few-shot 少样本提示来实现,关键是让简单问题和复杂问题分别处理。
这种方案适合流量混杂的场景,比如既有 “公司地址在哪” 这种一句话能答的问题,又有 “对比 A 和 B 两个方案的优缺点” 这种需要多文档综合分析的复杂问题。
上面这些方法处理的都是非结构化文本,但如果我们的数据是关系网络或者表格呢?那就需要下面的方法了。
### 结构化知识增强
GraphRAG
前面这些方法都有一个共同的问题,就是答案必须落在某一个文档块里。
但现实里经常有一类问题:答案散落在多个文档中,需要串起来推理。
举个例子,假设文档库里有两段话。
- 文档 A 写着 “张三是 AI 部门的负责人”
- 文档 B 写着 “AI 部门属于技术中心”
用户问:“张三属于哪个中心?”
传统向量检索大概率只能搜到文档 A,但要回答这个问题,必须把 A 和 B 连起来推理:张三 → AI 部门 → 技术中心。
这种跨文档的多跳推理,纯向量搜索就很难搞定了。
GraphRAG 就是用来解决这种问题的,这是 Microsoft Research 在 2024 年提出的方法。
它的思路是先把文档变成知识图谱,再基于图谱来检索和推理。
具体做法分为 3 步:
1. 用 LLM 逐篇读文档,抽取里面的实体(人、部门、产品等)和关系,构建成一张图谱
2. 用 Leiden 算法对图谱做社区划分,把关联紧密的实体聚成一团,然后让 LLM 为每个社区生成一段摘要
3. 提问时先定位到相关实体,沿着关系拿到子图
根据微软的评测,在全局语义理解类问题上,GraphRAG 答案的全面性和多样性显著优于传统向量 RAG。
但对于简单的事实查询,两者效果差不多,就没必要用了。
需要注意的是,GraphRAG 要用 LLM 逐篇抽实体关系,图谱构建成本比向量索引高得多,查询延迟也更大,所以使用 GraphRAG 之前一定要评估是否必要!
GraphRAG 的伪代码实现如下:
Text-to-SQL RAG
如果我们的数据本身就是结构化的表格,比如销售数据、用户行为日志、财务报表这些,就不合适传统的 RAG 了,因为对表格数据做 embedding 是非常低效的。
用户问:“上个月销售额最高的产品是哪个?”
这本质上就是一条 SQL,向量搜索对这种聚合、排序、筛选类的需求完全没招。
Text-to-SQL RAG 的做法是让 LLM 直接把自然语言翻译成 SQL,执行查询,再把查询结果作为上下文来回答:

这个方案适合所有数据分析类需求,比如 BI 看板问答、数据库运维助手、财务报表查询等等,本质上是用 LLM 替代了手写 SQL。
不过要特别提醒,生产环境中绝对不能让 LLM 生成的 SQL 直接执行,必须配备只读权限控制、SQL 语法审计、沙盒隔离等安全措施,防止 SQL 注入。
Text-to-SQL RAG 的伪代码实现很简单:
到这里,我们已经讲了很多种 RAG 方法了。有的小伙伴可能已经注意到一个问题:前面提到的大多数方法都是预定义好的 pipeline,流程是死的,不管什么问题进来,处理方式都差不多。
但现实世界的问题千变万化。有的需要搜向量库,有的该查数据库,有的应该搜 Web,甚至有的根本不需要检索。
好复杂啊…… 有没有一种方法能让系统自己判断该怎么做?
答案就是 Agentic RAG。
### 智能体驱动 RAG
Agentic RAG
前面每种方法都有自己擅长的场景:Hybrid Search 擅长术语密集的文档,GraphRAG 擅长多跳推理,Text-to-SQL 擅长结构化数据。
但在一个真实的系统中,这些场景可能同时存在。
比如用户问 “张三上个月的考勤记录” 得查数据库,问 “公司的远程办公政策” 得搜文档,问 “张三属于哪个部门的哪个中心” 得走知识图谱,但是为每种问题硬编码一条 pipeline 太麻烦了。
Agentic RAG 的做法是让一个 AI Agent 来自动调度,根据问题自主决定每一步该怎么做。给这个 Agent 配备一组检索工具,它会先搜搜看 → 看看结果够不够 → 不够就换个方式 / 换个关键词再搜 → 结果够了就生成回答。
Agentic RAG 虽然是很灵活的方案,但是代码实现很简单,核心是 Agent Loop 循环:
以前 Agent 的概念刚火起来的时候,大家还在争论 “Agent 自主决策靠不靠谱”。
到了今天,Agentic RAG 已经是比较主流的生产范式了,知名的 AI 编程工具 Cursor 用的就是这种方式,AI 自主决定使用什么方式来搜集信息:
Multi-Agent RAG
单个 Agent 处理复杂任务时,可能有个问题:当它要同时兼顾理解意图、选择策略、验证质量、生成答案时,Prompt 变得又长又复杂,决策质量就会下降。这就像一个人又当程序员、又教人打篮球、又当说唱歌手,忙不过来。
Multi-Agent RAG 的做法是拆分为多个专职 Agent,各自负责一些任务。
比如 Router Agent 负责分发、各 RAG Agent 负责对应领域的检索和推理、Verification Agent 负责质检、Generation Agent 负责润色输出。
这种方案适合数据源多、权限复杂、语言多样的企业级知识库。每个环节可以独立优化和扩展,不会牵一发而动全身。
Multi-Agent RAG 的代码示例如下:
### RAG 能力扩展
多模态 RAG(Multimodal RAG)
传统 RAG 只处理文本,但现实中的企业文档里面充斥着大量的图表、流程图、架构图、产品照片等。
如果用纯文本 RAG 去处理一份真实文档,那些流程图、架构图里的信息就全丢了。
多模态 RAG 的做法是把图片、表格和文本统一到一个向量空间里,这样检索时就能跨模态匹配:
最后一步生成阶段,需要用视觉语言模型来处理混合模态的上下文,因为普通的纯文本 LLM 看不懂图片。
多模态 RAG 的代码实现比较复杂:
Speculative RAG
普通的 RAG 还有一个问题:如果把检索到的所有文档都塞进同一个 Prompt,不仅增加了推理延迟、响应速度,而且如果某个文档是噪声,整个生成都会被带偏。
Speculative RAG(假设性检索增强生成)借鉴了推测性解码(Speculative Decoding)的思想,核心目标是降低延迟,把检索到的文档分成多个子集,用多个专家小模型从每个子集 **并行** 生成候选草稿,最后由一个更强的大模型做一次验证,选出最佳答案。
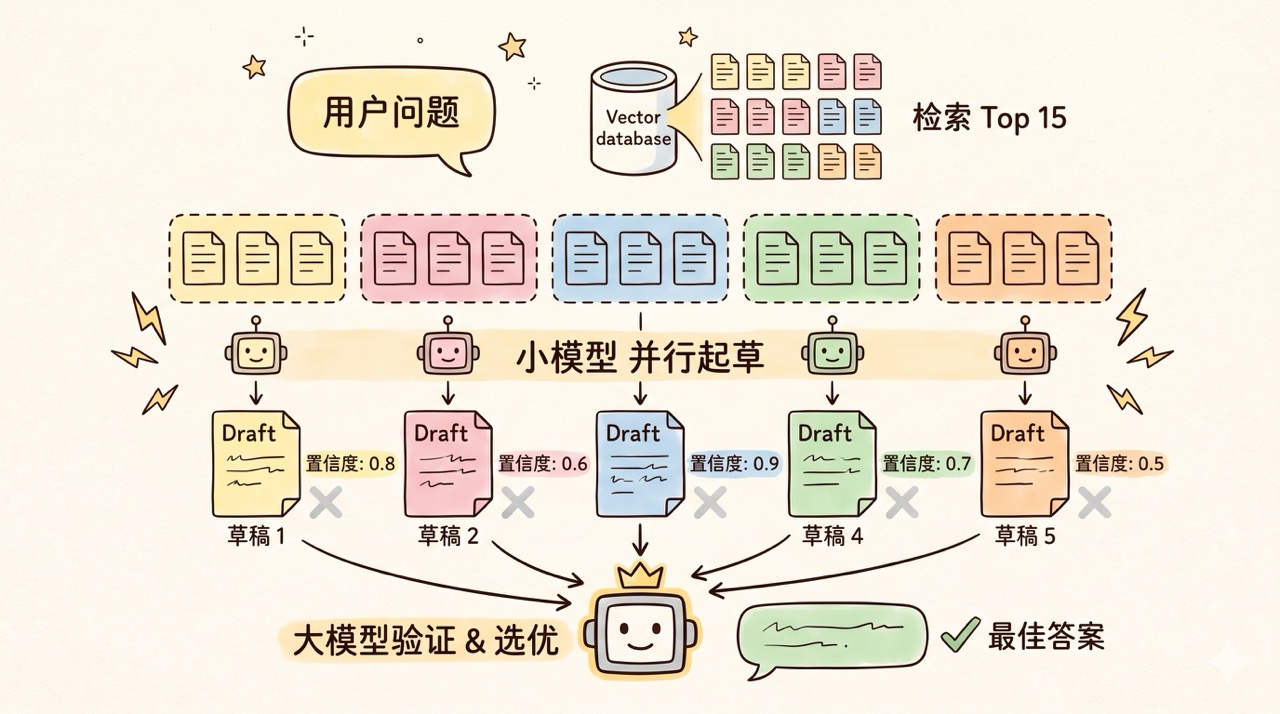
这就有点像团队共同做个大项目,多位前端和后端开发一起干活和仔细验证,最后产品经理只需要简单验证就好,能大幅缩短工作总时长,有问题也更容易发现。
Speculative RAG 的实现代码如下:
## 方法选择
看到这里,你可能已经被这十几种 RAG 方案搞晕了。
我到底该用哪一种啊啊啊啊?!
没事,我给大家梳理了一张表格,直接根据自己的项目情况来选方案:
你的情况 推荐方案 标准文本知识库,追求基本可用 Naive RAG 用户提问风格多变、口语化 Multi-Query RAG 或 HyDE 生产环境,追求检索质量 Hybrid Search + Reranking 对准确率要求高,不能容忍幻觉 Corrective RAG 或 Self-RAG 查询复杂度差异大 Adaptive RAG 路由 需要跨文档多跳推理 GraphRAG 数据以结构化表格为主 Text-to-SQL RAG 文档包含大量图表/图片 多模态 RAG 多数据源、多类型混合 Agentic RAG / Multi-Agent RAG 延迟敏感 Speculative RAG
对于正在动手搭建 RAG 系统的初学者来说,我建议 **从简单开始,逐步完善。**
先跑通 Naive RAG,发现哪个环节出了问题,就针对性地选用前面的 RAG 方案。
千万别一上来就搞 Multi-Agent + GraphRAG + 多模态全家桶,不仅实现成本高,效果也不一定更好。
那怎么知道 RAG 系统效果好不好呢?
其实有个评估框架 RAGAS,就是用来做这个的。它有四个核心指标:
- 忠实度(回答有没有瞎编)
- 答案相关性(答的是不是你问的)
- 上下文精确率(搜到的有多少是有用的)
- 上下文召回率(该搜到的搜到了吗)
这样你就能先评估效果再优化,而不是仅凭感觉调参数。
除此之外,RAG 相关的主流技术还有编排框架 LangChain / LangGraph、LlamaIndex、一体化平台 Dify 、RAGFlow、向量数据库 Chroma、Milvus、Qdrant 等,大家感兴趣的话可以自行学习了解一下~
OK,这篇文章写了快 1 万字,把 16 种 RAG 的实现和优化方案都讲完了,希望对大家有所帮助。
我是鱼皮,持续分享 AI 编程干货,这篇文章也会收录到我免费开源的 《AI 编程零基础入门教程》,GitHub Star 数已经破万,从零开始带你学会用 AI 开发上线自己的产品。
开源仓库:https://github.com/liyupi/ai-guide

学会的话欢迎点赞收藏关注哦,也欢迎评论区聊聊:你用过 RAG 么?最喜欢那种 RAG 方案?
02:30
46万观看 162弹幕

练习两年半,我做了个免费 AI编程自学网!吊打付费课,会打字就能学
评论