别再手写 HTTP 客户端调 AI 了!Spring AI 官方出手,一行代码搞定多模型切换

别再手写 HTTP 客户端调 AI 了!Spring AI 官方出手,一行代码搞定多模型切换
介绍
Spring AI 是 Spring 生态体系下的官方 AI 工程化框架,旨在为大语言模型(LLM)集成提供标准化的解决方案。该框架的核心价值在于将复杂的 AI 模型调用逻辑封装为符合 Spring 设计哲学(如依赖注入、自动配置)的组件,从而降低 Java 技术栈接入 AI 能力的工程成本。
其核心特性主要体现在三个维度。首先是多模型兼容性,框架提供了统一的 API 抽象,支持 OpenAI、Azure OpenAI、Google Gemini 及本地模型(如 Ollama),允许在不修改业务代码的情况下灵活切换底层模型。其次是生态深度融合,它并非独立的 SDK,而是与 Spring Boot、Spring Security 等原生组件无缝衔接,开发者可以直接利用现有的 Spring 基础设施来管理 AI 上下文、安全认证和监控。最后是企业级工程保障,框架内置了可观测性、流控、重试机制等生产环境必需特性,满足企业对稳定性和可维护性的严苛要求。
- 多模型兼容:内置对 OpenAI、Google Gemini、百度文心一言等主流厂商模型的适配,支持本地化模型对接,统一接口可灵活切换模型;
- 生态深度融合:与 Spring 生态(如依赖注入、Spring Security、监控组件)无缝衔接,现有 Spring 项目可零侵入集成,开发者无需学习新框架思想;
- 企业级保障:提供 API 密钥加密存储、权限控制、调用监控等生产级特性,同时支持流程编排与异常重试,满足企业对安全性、稳定性的需求。
目前,该框架已被广泛应用于智能客服、RAG(检索增强生成)知识库、代码辅助生成等企业级场景。
环境依赖与版本基线
tips:SpringAI至少需要SpringBoot 3.2,而SpringBoot3.2至少需要Java17
重要版本限制:Spring AI 对运行环境有严格的要求,必须使用 Java 17 及以上版本,且对应的 Spring Boot 版本需为 3.2 及以上。这是由于框架大量使用了现代 Java 特性及 Spring Boot 3.x 的自动配置机制,低版本环境无法兼容。

项目依赖配置
在 Maven 项目中,引入 spring-ai-openai-spring-boot-starter 依赖即可快速集成。为了保证依赖版本的一致性,建议通过 BOM(Bill of Materials) 进行版本管理:
在 pom.xml 中编写:
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>1.0.0-M5</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-M5</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
模型参数配置
在 application.yml 中配置 API Key 及模型参数。以下配置展示了如何接入兼容 OpenAI 协议的第三方模型(如 SiliconFlow 提供的 DeepSeek):
server:
port: 8080
spring:
ai:
openai:
api-key: sk-xxxxxxxxxxxxxxxxxxxxxxxx # 生产环境建议使用环境变量或配置中心注入
base-url: https://api.siliconflow.cn
chat:
options:
model: deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
temperature: 0.7 # 控制生成随机性的核心参数关于 temperature 参数:它决定了模型输出的随机性和创造性。取值范围通常在 0.0 到 1.0 之间。较低的值(如 0.2)会使模型输出更加确定、严谨,适用于代码生成或事实性问答;较高的值(如 0.8)则增加了输出的多样性,适用于创意写作或头脑风暴场景。在实际工程中,需根据业务对准确性和创造性的需求进行权衡。
快速集成示例
@Slf4j
@RestController
@RequestMapping("/ai")
public class DemoController {
@Resource
private OpenAiChatModel chatModel;
@GetMapping("/generate")
public String generate(@RequestParam(value = "message", defaultValue = "hello") String message) {
String response = chatModel.call(message);
log.info("response: {}", response);
return response;
}
}
以下代码展示了最基础的调用方式。通过注入 OpenAiChatModel 接口,直接发起同步请求并获取文本响应:
核心架构:ChatClient 与 ChatModel
Spring AI 提供了两种不同层级的抽象接口以适应不同的开发场景。理解这两者的差异是进行高效开发的前提。
该框架设计遵循了分层架构原则,将底层模型连接与上层业务调用逻辑解耦。这种设计不仅降低了 API 调用的复杂度,还确保了在不同模型提供商之间的可移植性,符合 Spring 模块化的设计理念。
ChatClient:高层流式 API
ChatClient 是面向大多数业务场景的高层门面接口。它采用了流式设计,支持链式调用,屏蔽了底层的 Prompt 构建细节和响应解析逻辑,旨在简化常见交互场景的开发。
该接口主要用于封装客户端构建、提示词规范设定以及请求发起等通用流程。
基础调用示例
@RestController
public class ChatDeepSeekController {
private final ChatClient chatClient;
public ChatDeepSeekController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping("/chat")
public String chat(@RequestParam(value = "msg", defaultValue = "给我讲个笑话") String message) {
return this.chatClient.prompt()
.user(message)
.call()
.content();
}
}
效果:

系统提示词配置
通过配置 ChatClient.Builder 的 defaultSystem 属性,可以全局定义模型的角色设定和行为边界。这比在每次请求中手动拼接 System Prompt 更加规范且易于维护。
@Configuration
public class AIConfig {
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
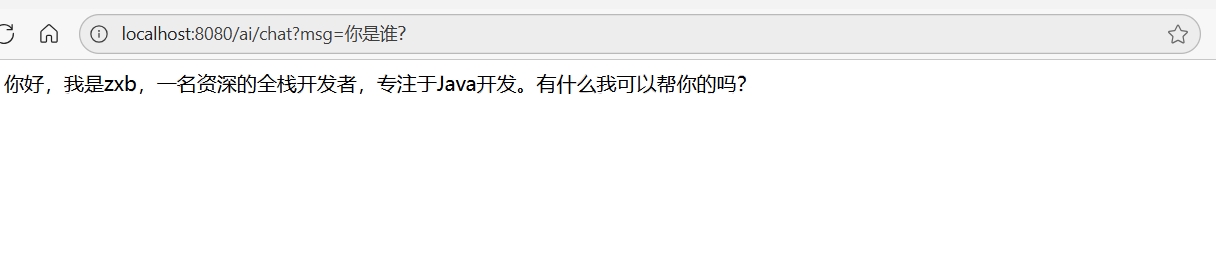
return builder.defaultSystem("你是一名资深的全栈开发者,精通Java技术栈。你的名字叫zxb。").build();
}
}
效果如下:
流式响应
在用户体验要求较高的场景(如对话式交互)中,流式输出是必不可少的。Spring AI 利用 Project Reactor 的 Flux 实现了非阻塞的流式响应,将 Token 逐个推送到客户端,显著降低了首字延迟(TTFT)。
-
-
call():阻塞式调用,等待模型完整生成所有 Token 后一次性返回结果。
-
-
-
stream():流式调用,返回一个Flux<String>,允许订阅端实时消费生成的数据流。
-
流式调用示例
@GetMapping(value = "/chat/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE + ";charset=UTF-8")
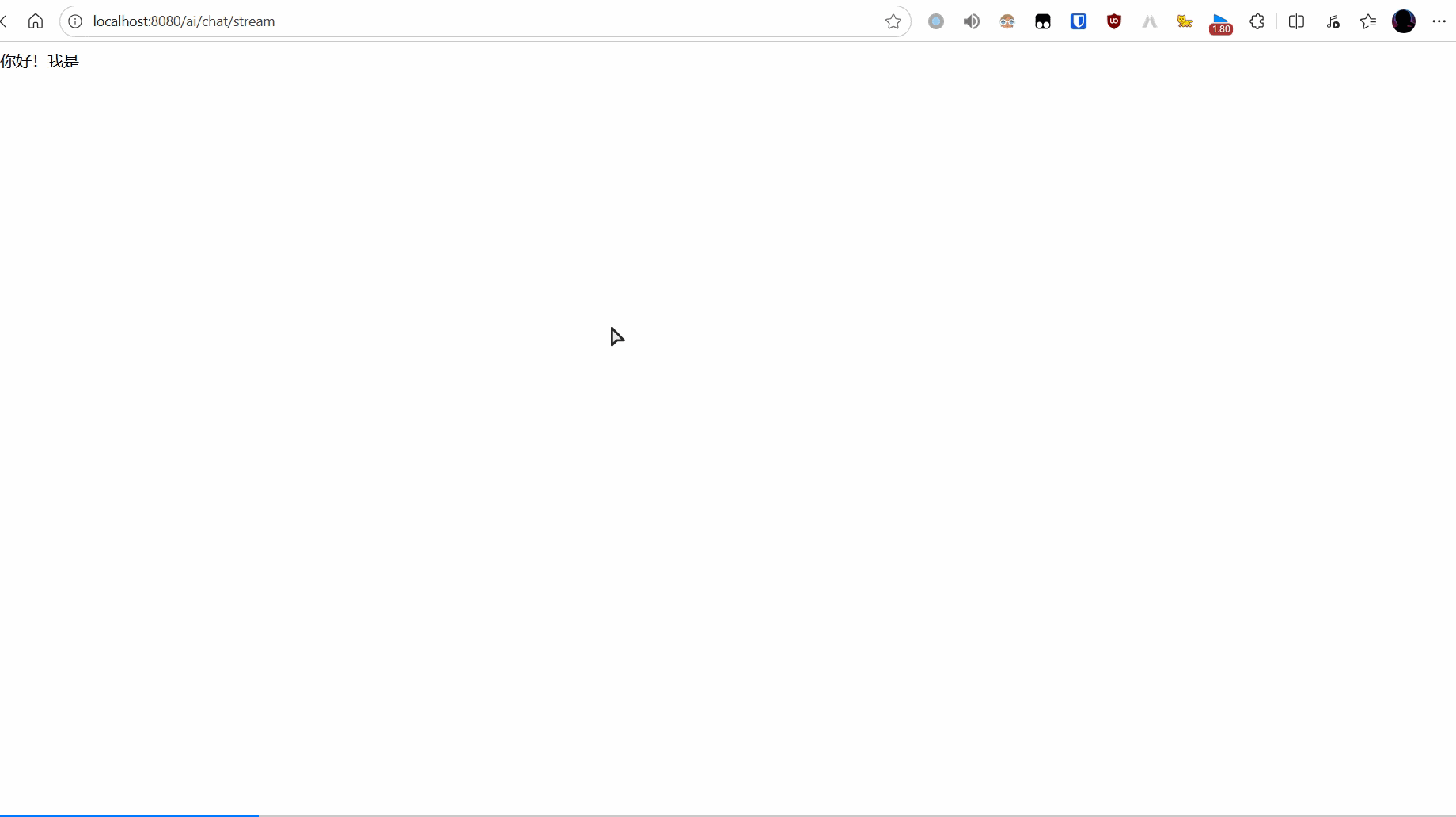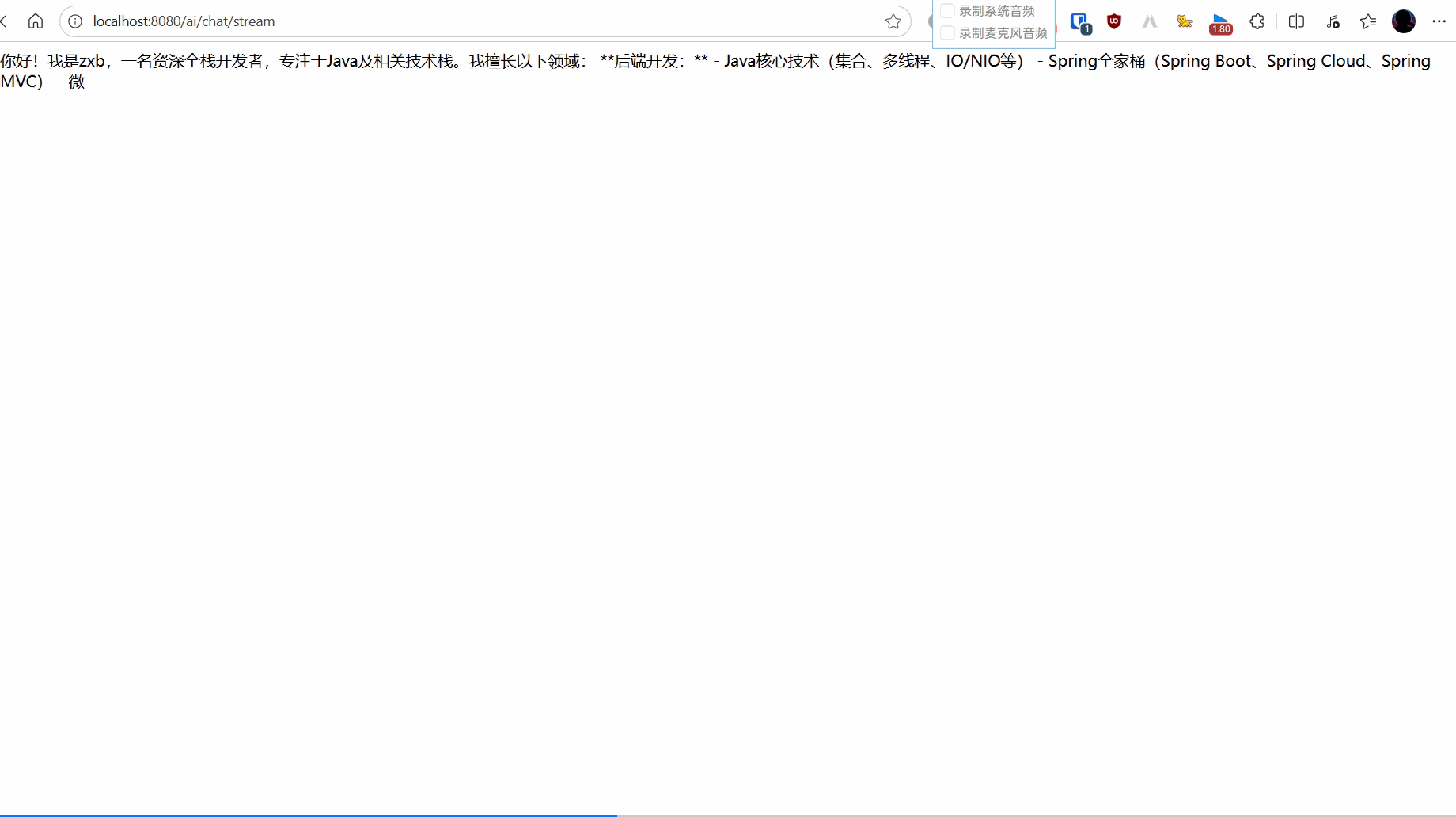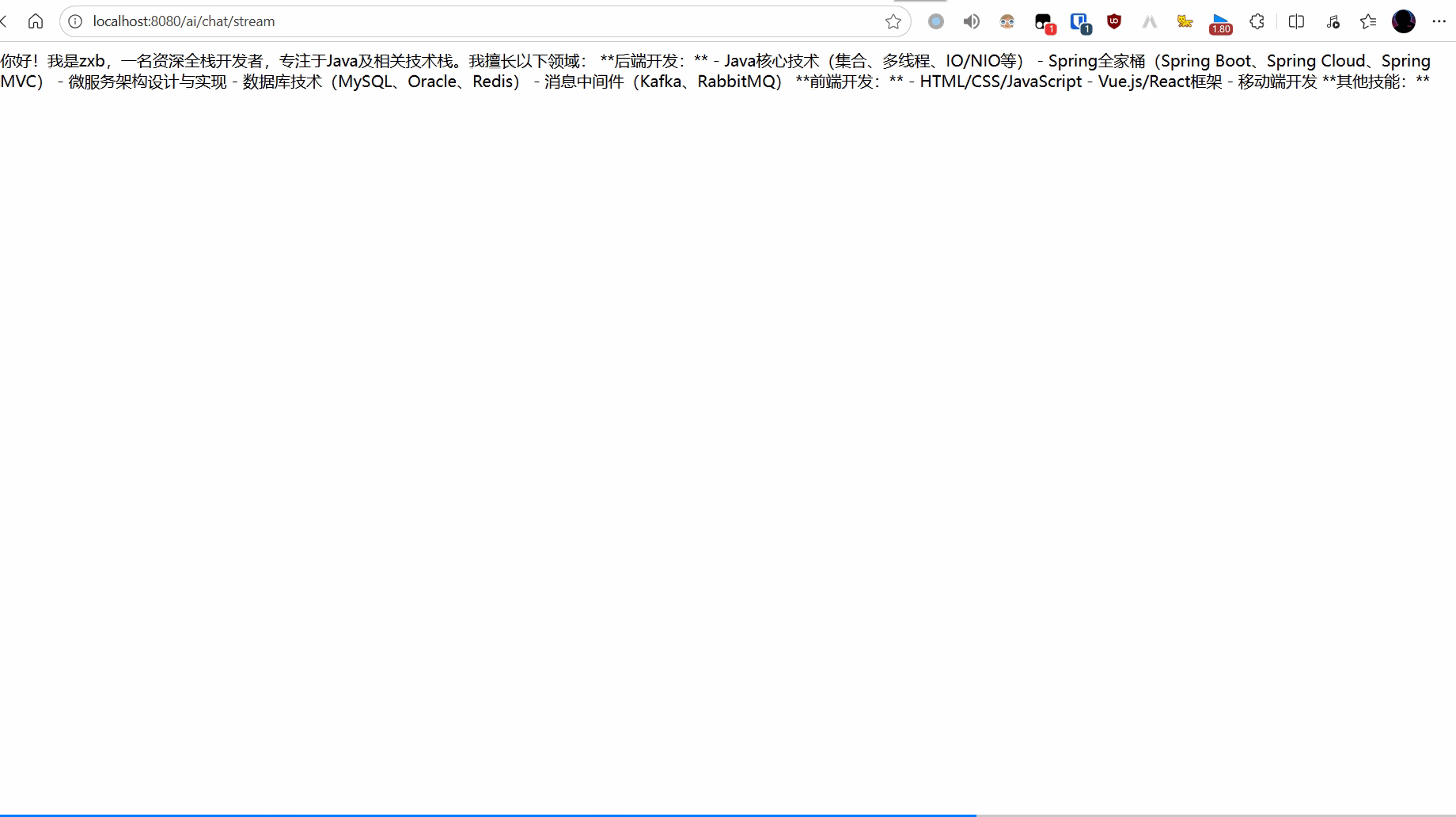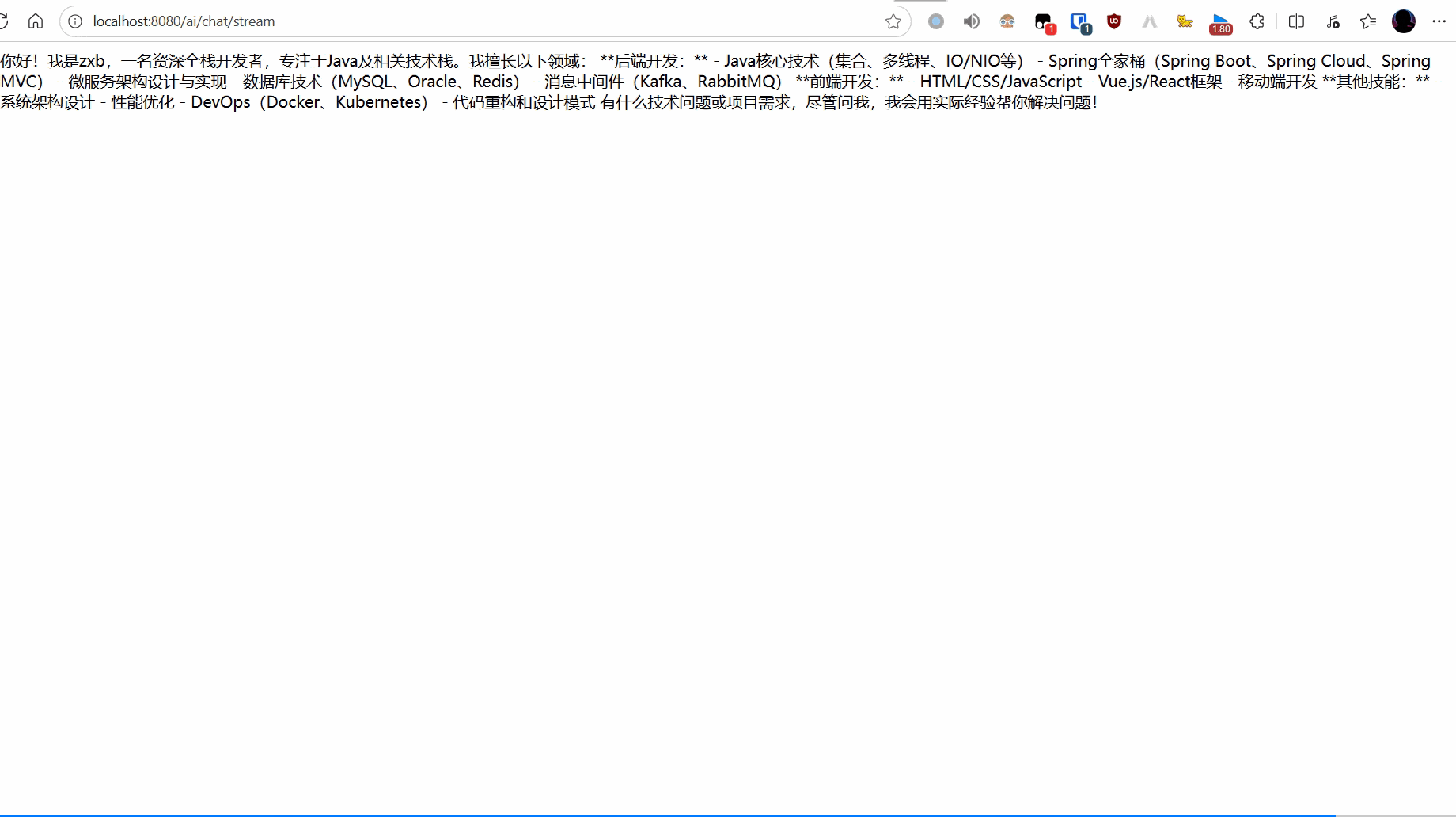
public Flux<String> chatStream(@RequestParam(name = "msg", defaultValue = "你好,你是谁?会什么?") String message) {
return chatClient.prompt().user(message).stream().content();
}
效果如下:
ChatModel:底层抽象接口
ChatModel 是直接对应底层 LLM 能力的抽象接口,例如 OpenAiChatModel 或 OllamaChatModel。它提供了对 Prompt 结构、模型选项(Temperature, TopP 等)以及元数据的细粒度控制。
架构定位:ChatModel 位于底层,是 ChatClient 的依赖对象。ChatClient 内部通过调用 ChatModel 完成实际的模型交互。
Demo:实现简单的对话
@GetMapping("/openai")
public String openai(@RequestParam("msg") String msg) {
ChatResponse response = chatModel.call(
new Prompt(
msg,
OpenAiChatOptions.builder()
.model("deepseek-chat")
.temperature(0.8)
.build()
)
);
return response.getResult().getOutput().getContent();
}
Prompt 模板管理
在生产环境中,硬编码 Prompt 字符串是极不可取的。Spring AI 提供了 SystemPromptTemplate 和 UserMessage 等 API,支持类似 MyBatis 的占位符替换机制。这使得 Prompt 结构可以与代码逻辑分离,便于动态配置和维护。
动态 Prompt 示例
@GetMapping(value = "/prompt", produces = MediaType.TEXT_EVENT_STREAM_VALUE + ";charset=UTF-8")
public Flux<String> prompt(@RequestParam("name") String name, @RequestParam("voice") String voice) {
String userText = """
给我推荐xx的至少三种美食
""";
UserMessage userMessage = new UserMessage(userText);
String systemText = """
你是一个美食咨询助手,可以帮助人们查询美食信息。
你的名字是{name}
你应该用你的名字和{voice}的饮食习惯回复用户的请求。
""";
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemText);
// 动态替换占位符
Message systemMessage = systemPromptTemplate.createMessage(Map.of("name", name, "voice", voice));
Prompt prompt = new Prompt(List.of(userMessage, systemMessage));
return chatClient.prompt(prompt).stream().content();
}
效果如下:

Function Calling:工具调用机制
机制概述
Function Calling 是连接大语言模型与确定性业务逻辑的桥梁。通过该机制,模型不再局限于训练数据中的知识,而是能够根据用户意图自主判断并触发预先注册的 Java 函数(如查询数据库、调用外部 API),然后将函数执行结果整合到最终回复中。
flowchart TD A[User Input] --> B[LLM Decision Engine] B -->|Needs Tool| C[Return Function Call Request] B -->|Direct Answer| D[Generate Response] C --> E[Spring AI Executor] E --> F[Invoke Registered Java Function] F --> G[Business Logic / DB Query] G --> H[Return Result to LLM] H --> D
实现步骤
1. 定义并注册函数
使用 @Bean 和 @Description 注解声明函数。@Description 中的内容至关重要,LLM 正是据此判断何时调用该函数。建议使用 Java Record 定义输入参数,以确保类型的清晰和不可变性。
@Configuration
public class CalculatorService {
@Bean
@Description("执行加法运算,输入两个整数并返回它们的和")
public Function<AddOperation, Integer> addOperation() {
return request -> request.a + request.b;
}
@Bean
@Description("执行乘法运算,输入两个整数并返回它们的积")
public Function<MulOperation, Integer> mulOperation() {
return request -> request.m * request.n;
}
// 使用 Record 定义类型安全的数据结构
public record AddOperation(int a, int b) {}
public record MulOperation(int m, int n) {}
}
2. 在 ChatClient 中启用函数
在构建请求时,通过 .functions() 方法将上述注册的 Bean 名称传递给 ChatClient。Spring AI 会自动处理函数元数据的序列化与模型回传结果的反序列化。
效果如下:


本地模型集成:Ollama
pom地址
对于对数据隐私有极高要求或希望降低 API 成本的场景,Spring AI 提供了对本地模型引擎 Ollama 的原生支持。
需引入 spring-ai-ollama-spring-boot-starter 依赖,并确保项目中配置了 Spring 的 Milestone 仓库(由于 Spring AI 尚处于快速迭代阶段,许多依赖未发布至中央仓库)。
配置本地地址
配置指向本地 Ollama 服务实例(默认端口 11434):
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: deepseek-r1:7b
temperature: 0.7
代码适配
由于 Spring AI 提供了统一的抽象层,从 OpenAI 切换至 Ollama 仅需替换注入的 ChatModel 实现类(OpenAiChatModel -> OllamaChatModel),业务逻辑层代码无需任何修改。
@Resource
private OllamaChatModel ollamaChatModel;
@GetMapping("/api/test")
public String generateTest(@RequestParam(value = "message", defaultValue = "hello") String message) {
String response = this.ollamaChatModel.call(message);
System.out.println("response: " + response);
return response;
}
评论